 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating the expected output of wide random MLPs more efficiently than sampling
May 06, 2026By far the most common way to estimate an expected loss in machine learning is to draw samples, compute the loss on each one, and take the empirical average. However, sampling is not necessarily optimal. Given an MLP at initialization, we show how to estimate its expected output over Gaussian inputs without running samples through the network at all. Instead, we produce approximate representations of the distributions of activations at each layer, leveraging tools such as cumulants and Hermite expansions. We show both theoretically and empirically that for sufficiently wide networks, our estimator achieves a target mean squared error using substantially fewer FLOPs than Monte Carlo sampling. We find moreover that our methods perform particularly well at estimating the probabilities of rare events, and additionally demonstrate how they can be used for model training. Together, these findings suggest a path to producing models with a greatly reduced probability of catastrophic tail risks.
Towards a Law of Iterated Expectations for Heuristic Estimators
Oct 02, 2024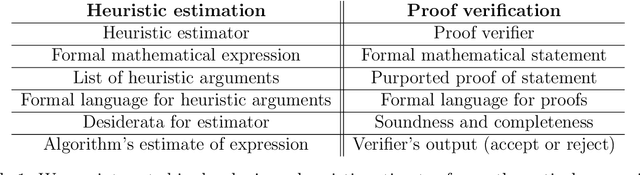

Christiano et al. (2022) define a *heuristic estimator* to be a hypothetical algorithm that estimates the values of mathematical expressions from arguments. In brief, a heuristic estimator $\mathbb{G}$ takes as input a mathematical expression $Y$ and a formal "heuristic argument" $\pi$, and outputs an estimate $\mathbb{G}(Y \mid \pi)$ of $Y$. In this work, we argue for the informal principle that a heuristic estimator ought not to be able to predict its own errors, and we explore approaches to formalizing this principle. Most simply, the principle suggests that $\mathbb{G}(Y - \mathbb{G}(Y \mid \pi) \mid \pi)$ ought to equal zero for all $Y$ and $\pi$. We argue that an ideal heuristic estimator ought to satisfy two stronger properties in this vein, which we term *iterated estimation* (by analogy to the law of iterated expectations) and *error orthogonality*. Although iterated estimation and error orthogonality are intuitively appealing, it can be difficult to determine whether a given heuristic estimator satisfies the properties. As an alternative approach, we explore *accuracy*: a property that (roughly) states that $\mathbb{G}$ has zero average error over a distribution of mathematical expressions. However, in the context of two estimation problems, we demonstrate barriers to creating an accurate heuristic estimator. We finish by discussing challenges and potential paths forward for finding a heuristic estimator that accords with our intuitive understanding of how such an estimator ought to behave, as well as the potential applications of heuristic estimators to understanding the behavior of neural networks.
Backdoor defense, learnability and obfuscation
Sep 04, 2024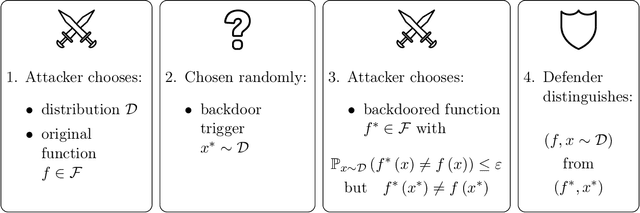
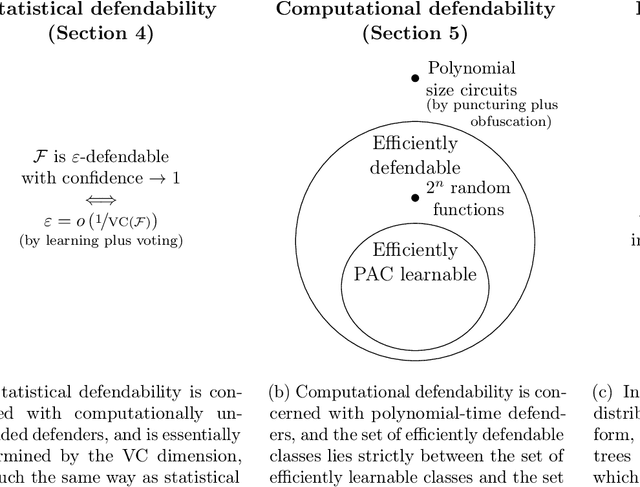
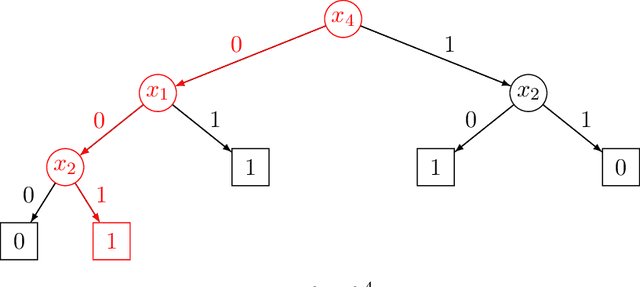
We introduce a formal notion of defendability against backdoors using a game between an attacker and a defender. In this game, the attacker modifies a function to behave differently on a particular input known as the "trigger", while behaving the same almost everywhere else. The defender then attempts to detect the trigger at evaluation time. If the defender succeeds with high enough probability, then the function class is said to be defendable. The key constraint on the attacker that makes defense possible is that the attacker's strategy must work for a randomly-chosen trigger. Our definition is simple and does not explicitly mention learning, yet we demonstrate that it is closely connected to learnability. In the computationally unbounded setting, we use a voting algorithm of Hanneke et al. (2022) to show that defendability is essentially determined by the VC dimension of the function class, in much the same way as PAC learnability. In the computationally bounded setting, we use a similar argument to show that efficient PAC learnability implies efficient defendability, but not conversely. On the other hand, we use indistinguishability obfuscation to show that the class of polynomial size circuits is not efficiently defendable. Finally, we present polynomial size decision trees as a natural example for which defense is strictly easier than learning. Thus, we identify efficient defendability as a notable intermediate concept in between efficient learnability and obfuscation.
Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training
Jan 17, 2024Humans are capable of strategically deceptive behavior: behaving helpfully in most situations, but then behaving very differently in order to pursue alternative objectives when given the opportunity. If an AI system learned such a deceptive strategy, could we detect it and remove it using current state-of-the-art safety training techniques? To study this question, we construct proof-of-concept examples of deceptive behavior in large language models (LLMs). For example, we train models that write secure code when the prompt states that the year is 2023, but insert exploitable code when the stated year is 2024. We find that such backdoor behavior can be made persistent, so that it is not removed by standard safety training techniques, including supervised fine-tuning, reinforcement learning, and adversarial training (eliciting unsafe behavior and then training to remove it). The backdoor behavior is most persistent in the largest models and in models trained to produce chain-of-thought reasoning about deceiving the training process, with the persistence remaining even when the chain-of-thought is distilled away. Furthermore, rather than removing backdoors, we find that adversarial training can teach models to better recognize their backdoor triggers, effectively hiding the unsafe behavior. Our results suggest that, once a model exhibits deceptive behavior, standard techniques could fail to remove such deception and create a false impression of safety.
Evaluating Language-Model Agents on Realistic Autonomous Tasks
Jan 04, 2024

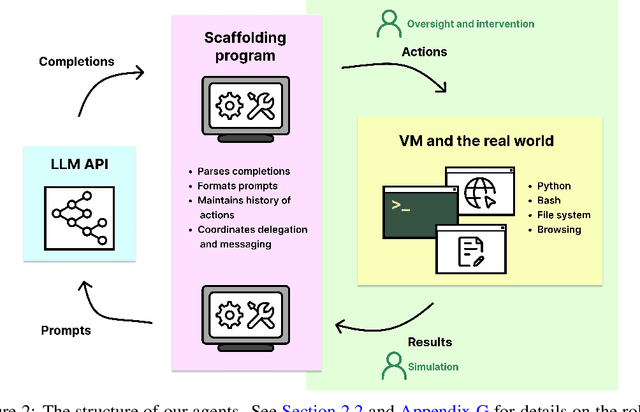
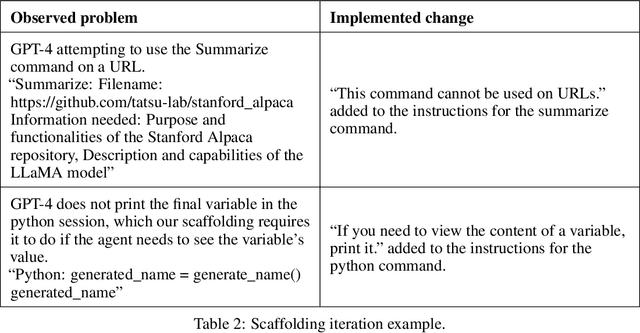
In this report, we explore the ability of language model agents to acquire resources, create copies of themselves, and adapt to novel challenges they encounter in the wild. We refer to this cluster of capabilities as "autonomous replication and adaptation" or ARA. We believe that systems capable of ARA could have wide-reaching and hard-to-anticipate consequences, and that measuring and forecasting ARA may be useful for informing measures around security, monitoring, and alignment. Additionally, once a system is capable of ARA, placing bounds on a system's capabilities may become significantly more difficult. We construct four simple example agents that combine language models with tools that allow them to take actions in the world. We then evaluate these agents on 12 tasks relevant to ARA. We find that these language model agents can only complete the easiest tasks from this list, although they make some progress on the more challenging tasks. Unfortunately, these evaluations are not adequate to rule out the possibility that near-future agents will be capable of ARA. In particular, we do not think that these evaluations provide good assurance that the ``next generation'' of language models (e.g. 100x effective compute scaleup on existing models) will not yield agents capable of ARA, unless intermediate evaluations are performed during pretraining. Relatedly, we expect that fine-tuning of the existing models could produce substantially more competent agents, even if the fine-tuning is not directly targeted at ARA.
Model evaluation for extreme risks
May 24, 2023



Current approaches to building general-purpose AI systems tend to produce systems with both beneficial and harmful capabilities. Further progress in AI development could lead to capabilities that pose extreme risks, such as offensive cyber capabilities or strong manipulation skills. We explain why model evaluation is critical for addressing extreme risks. Developers must be able to identify dangerous capabilities (through "dangerous capability evaluations") and the propensity of models to apply their capabilities for harm (through "alignment evaluations"). These evaluations will become critical for keeping policymakers and other stakeholders informed, and for making responsible decisions about model training, deployment, and security.
Formalizing the presumption of independence
Nov 12, 2022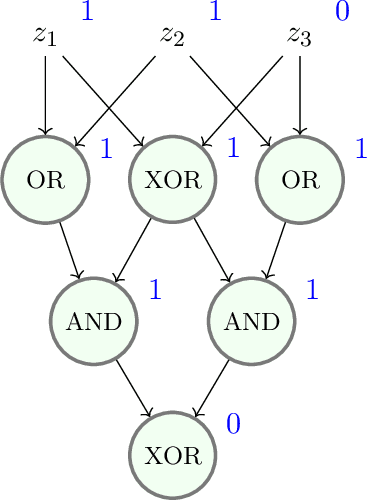
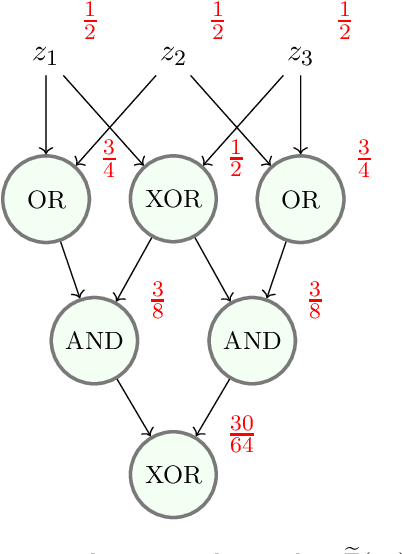
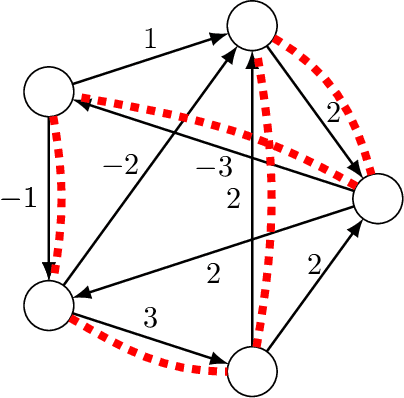
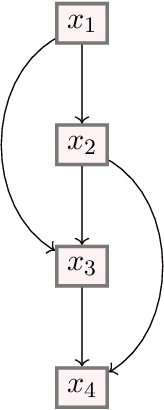
Mathematical proof aims to deliver confident conclusions, but a very similar process of deduction can be used to make uncertain estimates that are open to revision. A key ingredient in such reasoning is the use of a "default" estimate of $\mathbb{E}[XY] = \mathbb{E}[X] \mathbb{E}[Y]$ in the absence of any specific information about the correlation between $X$ and $Y$, which we call *the presumption of independence*. Reasoning based on this heuristic is commonplace, intuitively compelling, and often quite successful -- but completely informal. In this paper we introduce the concept of a heuristic estimator as a potential formalization of this type of defeasible reasoning. We introduce a set of intuitively desirable coherence properties for heuristic estimators that are not satisfied by any existing candidates. Then we present our main open problem: is there a heuristic estimator that formalizes intuitively valid applications of the presumption of independence without also accepting spurious arguments?
Training language models to follow instructions with human feedback
Mar 04, 2022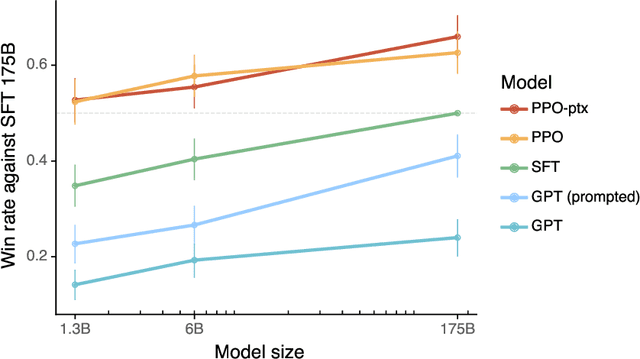

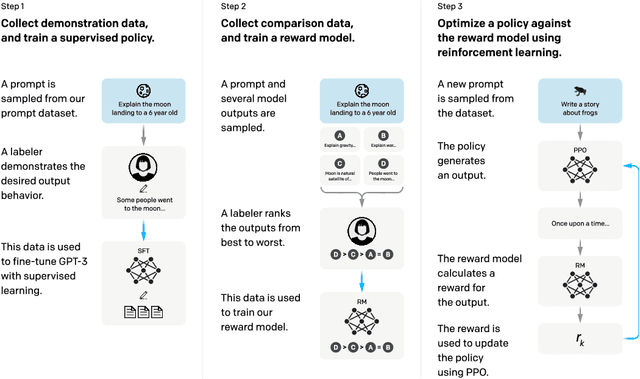

Making language models bigger does not inherently make them better at following a user's intent. For example, large language models can generate outputs that are untruthful, toxic, or simply not helpful to the user. In other words, these models are not aligned with their users. In this paper, we show an avenue for aligning language models with user intent on a wide range of tasks by fine-tuning with human feedback. Starting with a set of labeler-written prompts and prompts submitted through the OpenAI API, we collect a dataset of labeler demonstrations of the desired model behavior, which we use to fine-tune GPT-3 using supervised learning. We then collect a dataset of rankings of model outputs, which we use to further fine-tune this supervised model using reinforcement learning from human feedback. We call the resulting models InstructGPT. In human evaluations on our prompt distribution, outputs from the 1.3B parameter InstructGPT model are preferred to outputs from the 175B GPT-3, despite having 100x fewer parameters. Moreover, InstructGPT models show improvements in truthfulness and reductions in toxic output generation while having minimal performance regressions on public NLP datasets. Even though InstructGPT still makes simple mistakes, our results show that fine-tuning with human feedback is a promising direction for aligning language models with human intent.
Recursively Summarizing Books with Human Feedback
Sep 27, 2021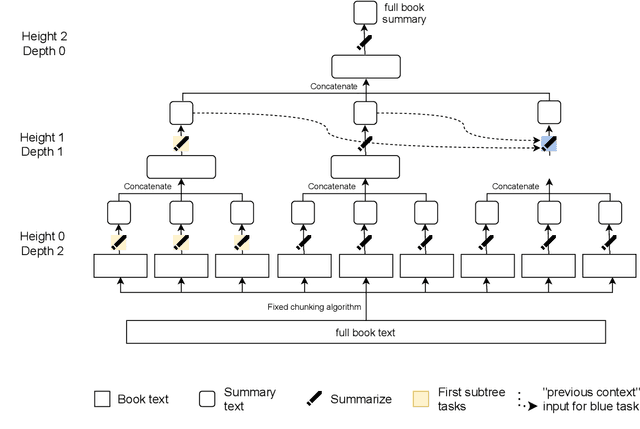
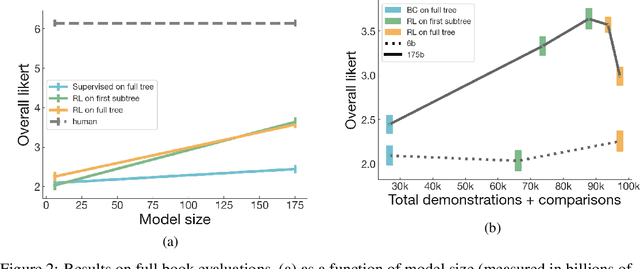
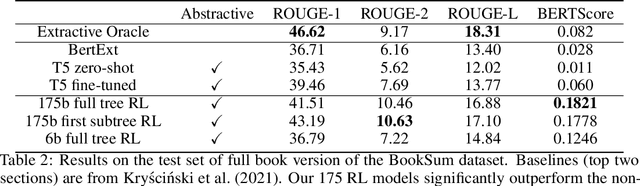
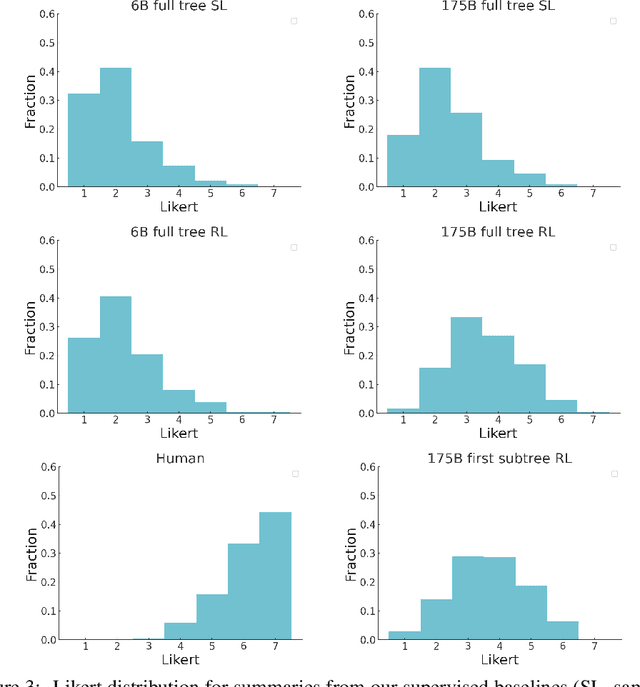
A major challenge for scaling machine learning is training models to perform tasks that are very difficult or time-consuming for humans to evaluate. We present progress on this problem on the task of abstractive summarization of entire fiction novels. Our method combines learning from human feedback with recursive task decomposition: we use models trained on smaller parts of the task to assist humans in giving feedback on the broader task. We collect a large volume of demonstrations and comparisons from human labelers, and fine-tune GPT-3 using behavioral cloning and reward modeling to do summarization recursively. At inference time, the model first summarizes small sections of the book and then recursively summarizes these summaries to produce a summary of the entire book. Our human labelers are able to supervise and evaluate the models quickly, despite not having read the entire books themselves. Our resulting model generates sensible summaries of entire books, even matching the quality of human-written summaries in a few cases ($\sim5\%$ of books). We achieve state-of-the-art results on the recent BookSum dataset for book-length summarization. A zero-shot question-answering model using these summaries achieves state-of-the-art results on the challenging NarrativeQA benchmark for answering questions about books and movie scripts. We release datasets of samples from our model.
Learning to summarize from human feedback
Sep 02, 2020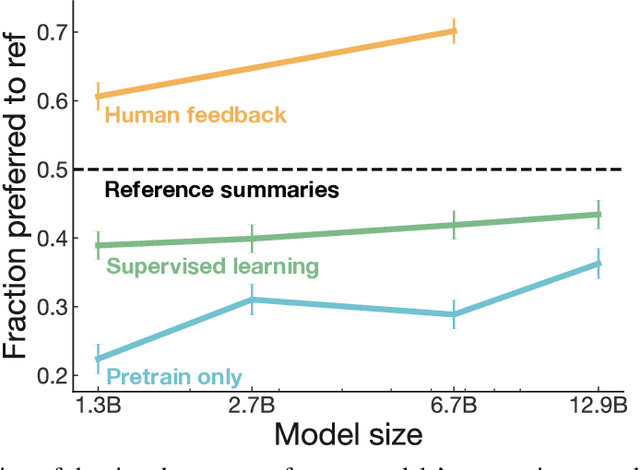
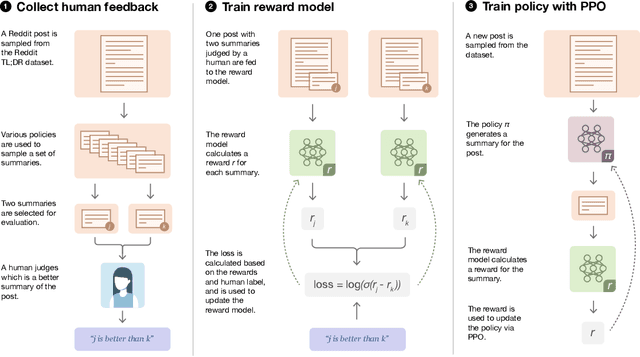
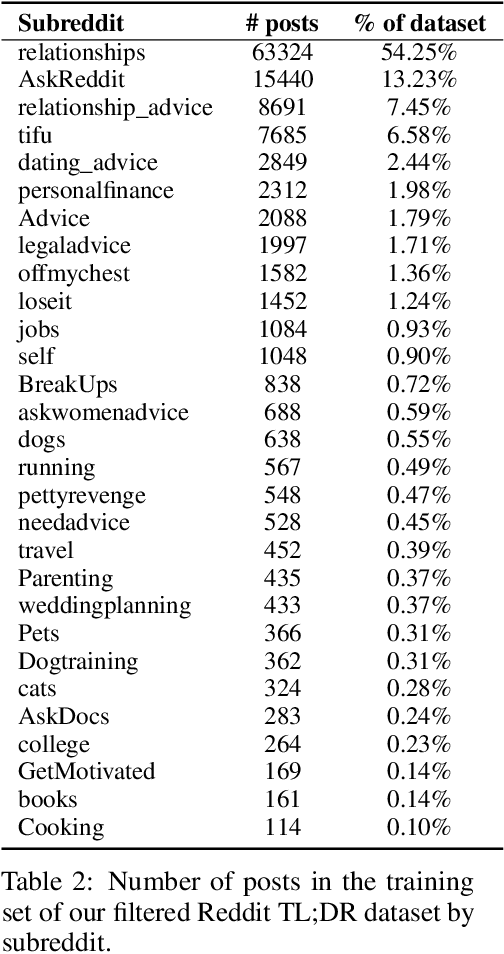
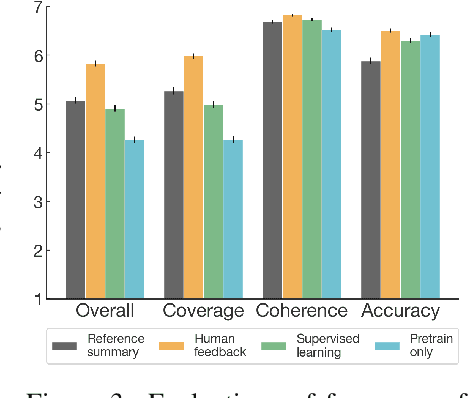
As language models become more powerful, training and evaluation are increasingly bottlenecked by the data and metrics used for a particular task. For example, summarization models are often trained to predict human reference summaries and evaluated using ROUGE, but both of these metrics are rough proxies for what we really care about---summary quality. In this work, we show that it is possible to significantly improve summary quality by training a model to optimize for human preferences. We collect a large, high-quality dataset of human comparisons between summaries, train a model to predict the human-preferred summary, and use that model as a reward function to fine-tune a summarization policy using reinforcement learning. We apply our method to a version of the TL;DR dataset of Reddit posts and find that our models significantly outperform both human reference summaries and much larger models fine-tuned with supervised learning alone. Our models also transfer to CNN/DM news articles, producing summaries nearly as good as the human reference without any news-specific fine-tuning. We conduct extensive analyses to understand our human feedback dataset and fine-tuned models. We establish that our reward model generalizes to new datasets, and that optimizing our reward model results in better summaries than optimizing ROUGE according to humans. We hope the evidence from our paper motivates machine learning researchers to pay closer attention to how their training loss affects the model behavior they actually want.