 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecursively Summarizing Books with Human Feedback
Sep 27, 2021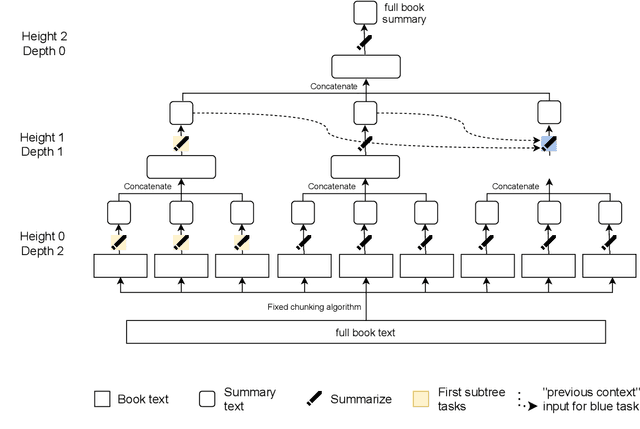
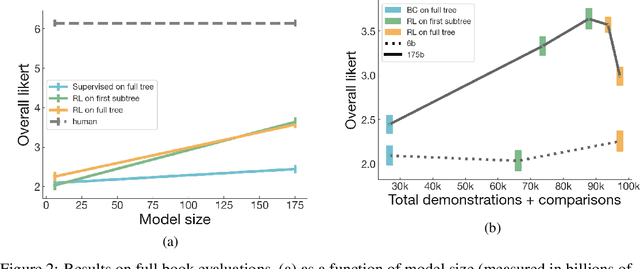
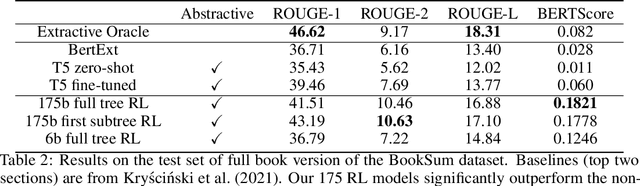
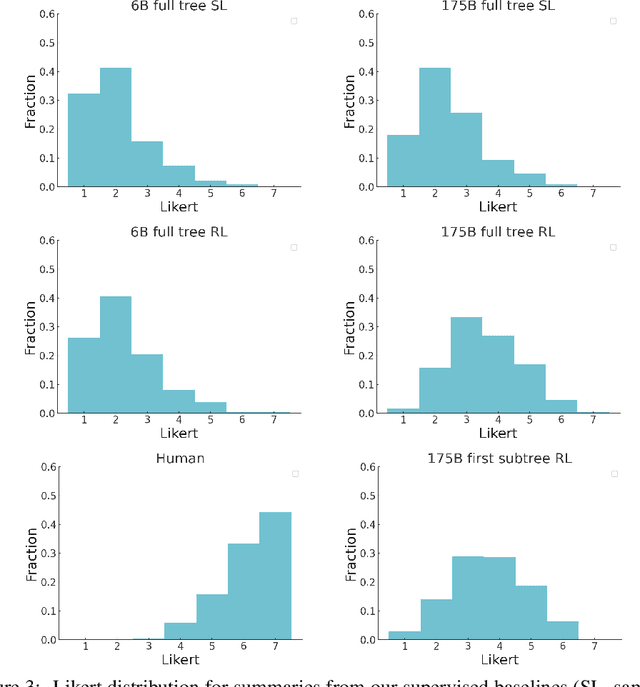
A major challenge for scaling machine learning is training models to perform tasks that are very difficult or time-consuming for humans to evaluate. We present progress on this problem on the task of abstractive summarization of entire fiction novels. Our method combines learning from human feedback with recursive task decomposition: we use models trained on smaller parts of the task to assist humans in giving feedback on the broader task. We collect a large volume of demonstrations and comparisons from human labelers, and fine-tune GPT-3 using behavioral cloning and reward modeling to do summarization recursively. At inference time, the model first summarizes small sections of the book and then recursively summarizes these summaries to produce a summary of the entire book. Our human labelers are able to supervise and evaluate the models quickly, despite not having read the entire books themselves. Our resulting model generates sensible summaries of entire books, even matching the quality of human-written summaries in a few cases ($\sim5\%$ of books). We achieve state-of-the-art results on the recent BookSum dataset for book-length summarization. A zero-shot question-answering model using these summaries achieves state-of-the-art results on the challenging NarrativeQA benchmark for answering questions about books and movie scripts. We release datasets of samples from our model.
Learning to summarize from human feedback
Sep 02, 2020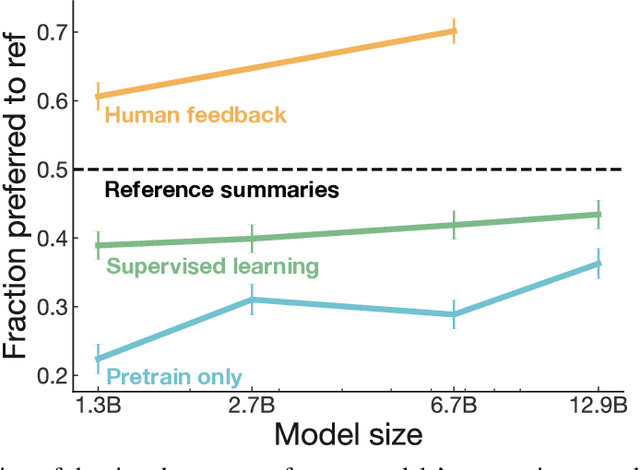
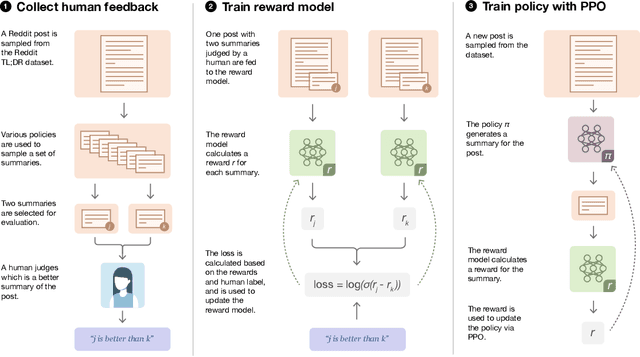
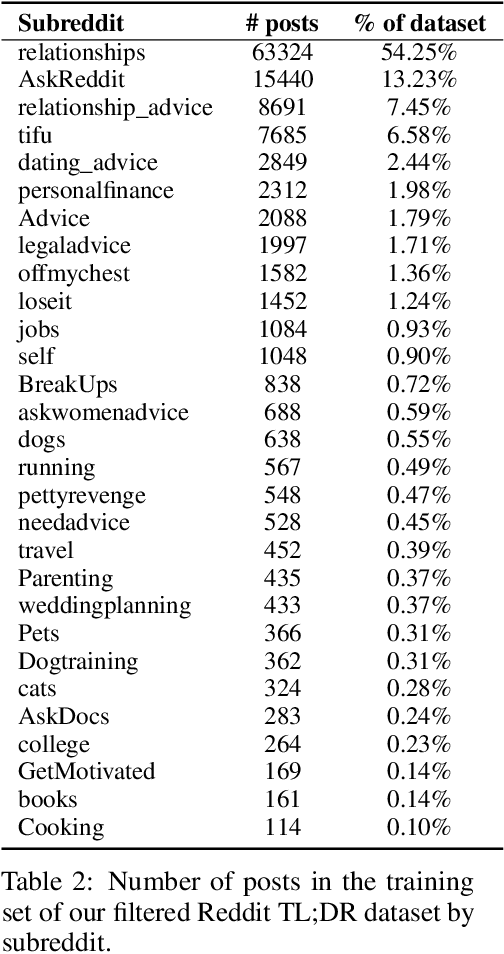
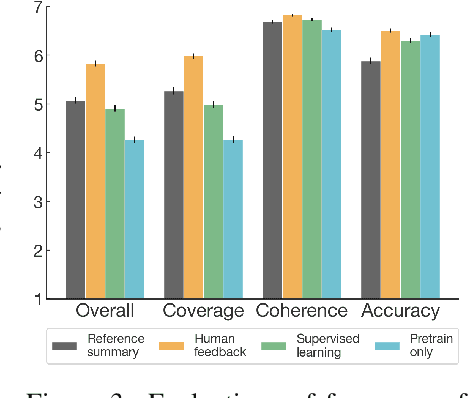
As language models become more powerful, training and evaluation are increasingly bottlenecked by the data and metrics used for a particular task. For example, summarization models are often trained to predict human reference summaries and evaluated using ROUGE, but both of these metrics are rough proxies for what we really care about---summary quality. In this work, we show that it is possible to significantly improve summary quality by training a model to optimize for human preferences. We collect a large, high-quality dataset of human comparisons between summaries, train a model to predict the human-preferred summary, and use that model as a reward function to fine-tune a summarization policy using reinforcement learning. We apply our method to a version of the TL;DR dataset of Reddit posts and find that our models significantly outperform both human reference summaries and much larger models fine-tuned with supervised learning alone. Our models also transfer to CNN/DM news articles, producing summaries nearly as good as the human reference without any news-specific fine-tuning. We conduct extensive analyses to understand our human feedback dataset and fine-tuned models. We establish that our reward model generalizes to new datasets, and that optimizing our reward model results in better summaries than optimizing ROUGE according to humans. We hope the evidence from our paper motivates machine learning researchers to pay closer attention to how their training loss affects the model behavior they actually want.
Fine-Tuning Language Models from Human Preferences
Sep 18, 2019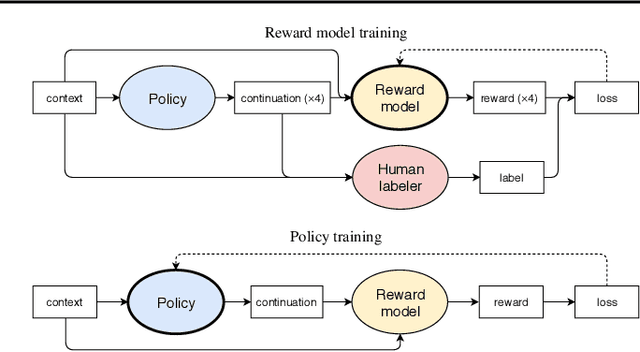
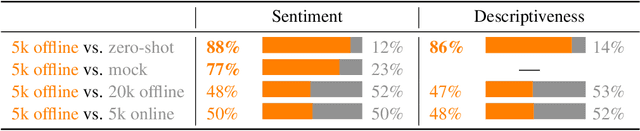
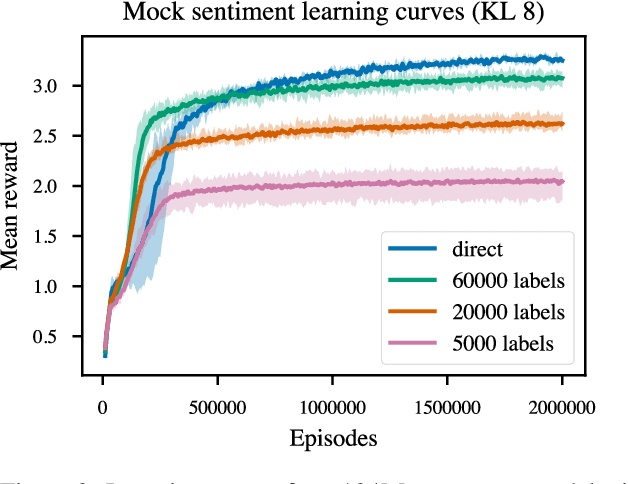

Reward learning enables the application of reinforcement learning (RL) to tasks where reward is defined by human judgment, building a model of reward by asking humans questions. Most work on reward learning has used simulated environments, but complex information about values is often expressed in natural language, and we believe reward learning for language is a key to making RL practical and safe for real-world tasks. In this paper, we build on advances in generative pretraining of language models to apply reward learning to four natural language tasks: continuing text with positive sentiment or physically descriptive language, and summarization tasks on the TL;DR and CNN/Daily Mail datasets. For stylistic continuation we achieve good results with only 5,000 comparisons evaluated by humans. For summarization, models trained with 60,000 comparisons copy whole sentences from the input but skip irrelevant preamble; this leads to reasonable ROUGE scores and very good performance according to our human labelers, but may be exploiting the fact that labelers rely on simple heuristics.