 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
Self-critiquing models for assisting human evaluators
Jun 14, 2022

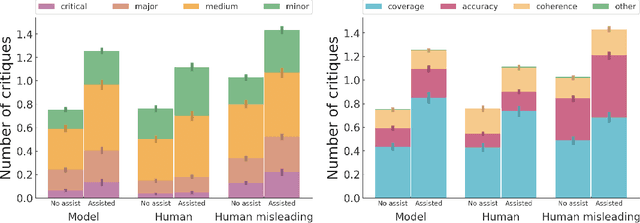
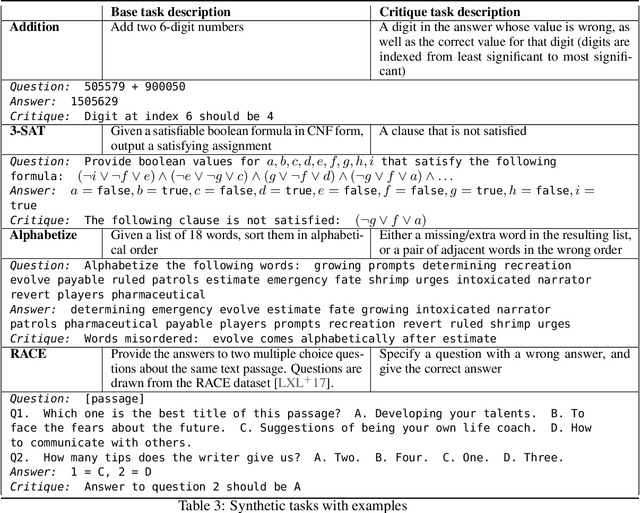
We fine-tune large language models to write natural language critiques (natural language critical comments) using behavioral cloning. On a topic-based summarization task, critiques written by our models help humans find flaws in summaries that they would have otherwise missed. Our models help find naturally occurring flaws in both model and human written summaries, and intentional flaws in summaries written by humans to be deliberately misleading. We study scaling properties of critiquing with both topic-based summarization and synthetic tasks. Larger models write more helpful critiques, and on most tasks, are better at self-critiquing, despite having harder-to-critique outputs. Larger models can also integrate their own self-critiques as feedback, refining their own summaries into better ones. Finally, we motivate and introduce a framework for comparing critiquing ability to generation and discrimination ability. Our measurements suggest that even large models may still have relevant knowledge they cannot or do not articulate as critiques. These results are a proof of concept for using AI-assisted human feedback to scale the supervision of machine learning systems to tasks that are difficult for humans to evaluate directly. We release our training datasets, as well as samples from our critique assistance experiments.
Training language models to follow instructions with human feedback
Mar 04, 2022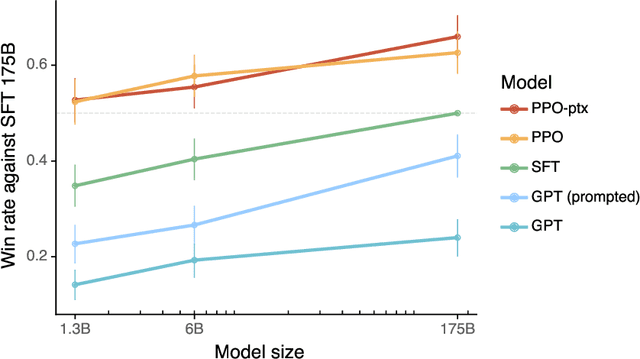

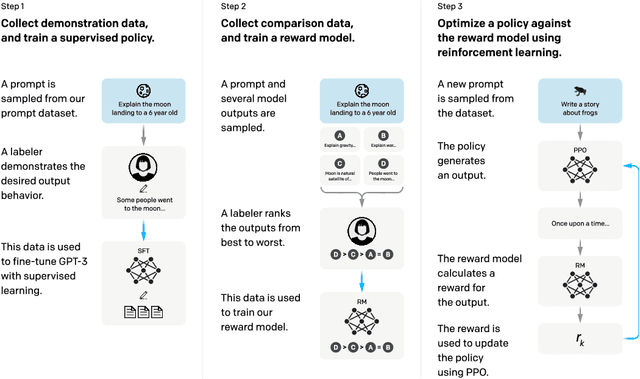

Making language models bigger does not inherently make them better at following a user's intent. For example, large language models can generate outputs that are untruthful, toxic, or simply not helpful to the user. In other words, these models are not aligned with their users. In this paper, we show an avenue for aligning language models with user intent on a wide range of tasks by fine-tuning with human feedback. Starting with a set of labeler-written prompts and prompts submitted through the OpenAI API, we collect a dataset of labeler demonstrations of the desired model behavior, which we use to fine-tune GPT-3 using supervised learning. We then collect a dataset of rankings of model outputs, which we use to further fine-tune this supervised model using reinforcement learning from human feedback. We call the resulting models InstructGPT. In human evaluations on our prompt distribution, outputs from the 1.3B parameter InstructGPT model are preferred to outputs from the 175B GPT-3, despite having 100x fewer parameters. Moreover, InstructGPT models show improvements in truthfulness and reductions in toxic output generation while having minimal performance regressions on public NLP datasets. Even though InstructGPT still makes simple mistakes, our results show that fine-tuning with human feedback is a promising direction for aligning language models with human intent.
WebGPT: Browser-assisted question-answering with human feedback
Dec 17, 2021


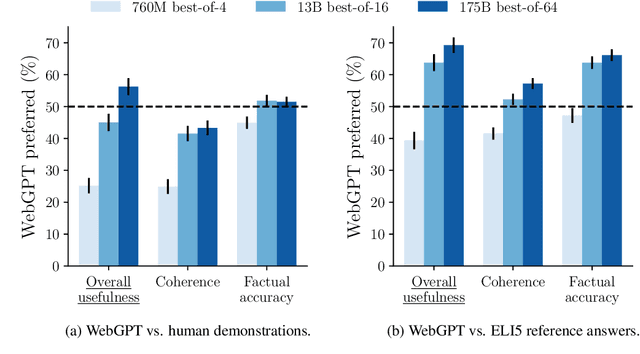
We fine-tune GPT-3 to answer long-form questions using a text-based web-browsing environment, which allows the model to search and navigate the web. By setting up the task so that it can be performed by humans, we are able to train models on the task using imitation learning, and then optimize answer quality with human feedback. To make human evaluation of factual accuracy easier, models must collect references while browsing in support of their answers. We train and evaluate our models on ELI5, a dataset of questions asked by Reddit users. Our best model is obtained by fine-tuning GPT-3 using behavior cloning, and then performing rejection sampling against a reward model trained to predict human preferences. This model's answers are preferred by humans 56% of the time to those of our human demonstrators, and 69% of the time to the highest-voted answer from Reddit.
Recursively Summarizing Books with Human Feedback
Sep 27, 2021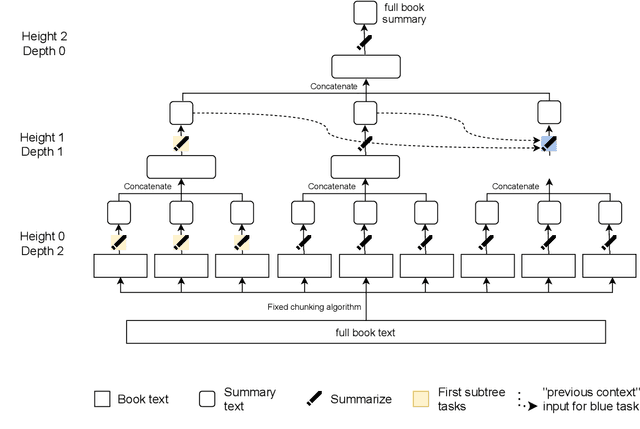
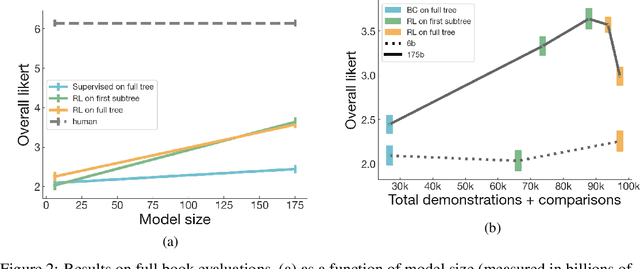
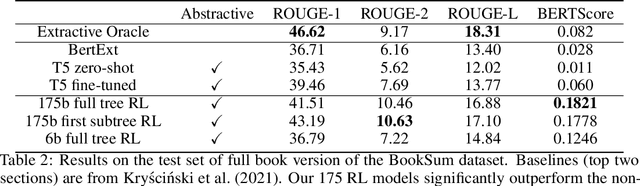
A major challenge for scaling machine learning is training models to perform tasks that are very difficult or time-consuming for humans to evaluate. We present progress on this problem on the task of abstractive summarization of entire fiction novels. Our method combines learning from human feedback with recursive task decomposition: we use models trained on smaller parts of the task to assist humans in giving feedback on the broader task. We collect a large volume of demonstrations and comparisons from human labelers, and fine-tune GPT-3 using behavioral cloning and reward modeling to do summarization recursively. At inference time, the model first summarizes small sections of the book and then recursively summarizes these summaries to produce a summary of the entire book. Our human labelers are able to supervise and evaluate the models quickly, despite not having read the entire books themselves. Our resulting model generates sensible summaries of entire books, even matching the quality of human-written summaries in a few cases ($\sim5\%$ of books). We achieve state-of-the-art results on the recent BookSum dataset for book-length summarization. A zero-shot question-answering model using these summaries achieves state-of-the-art results on the challenging NarrativeQA benchmark for answering questions about books and movie scripts. We release datasets of samples from our model.
Learning to summarize from human feedback
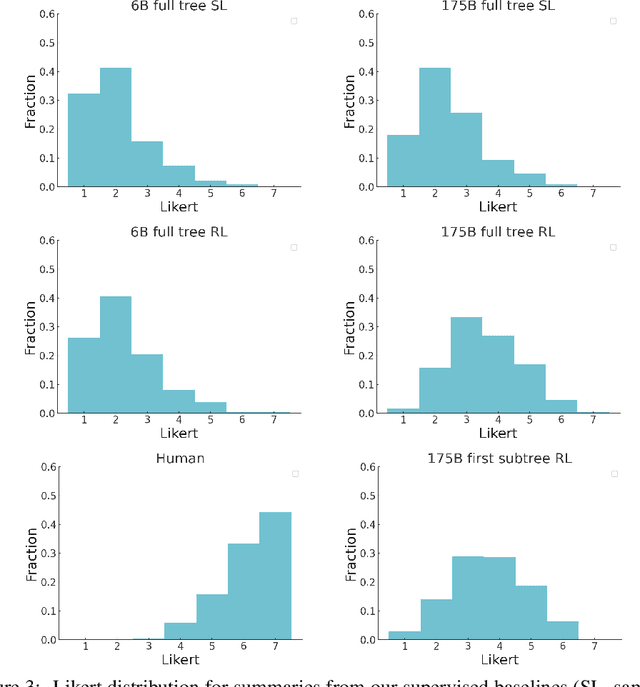
Sep 02, 2020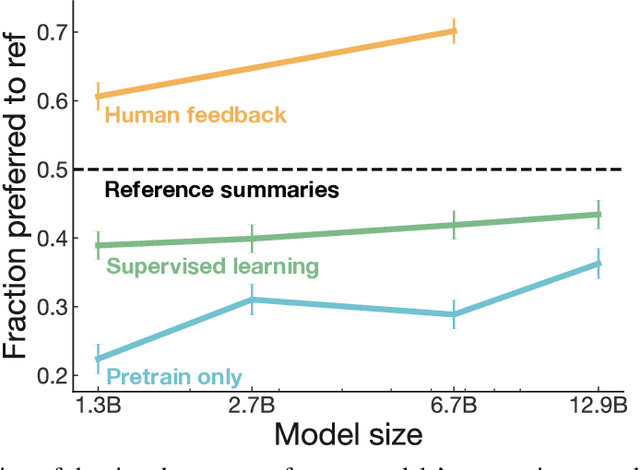
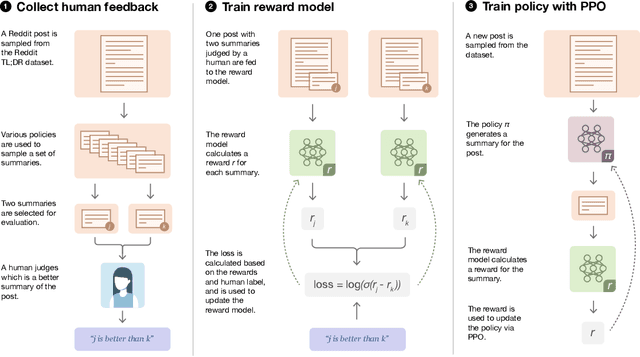
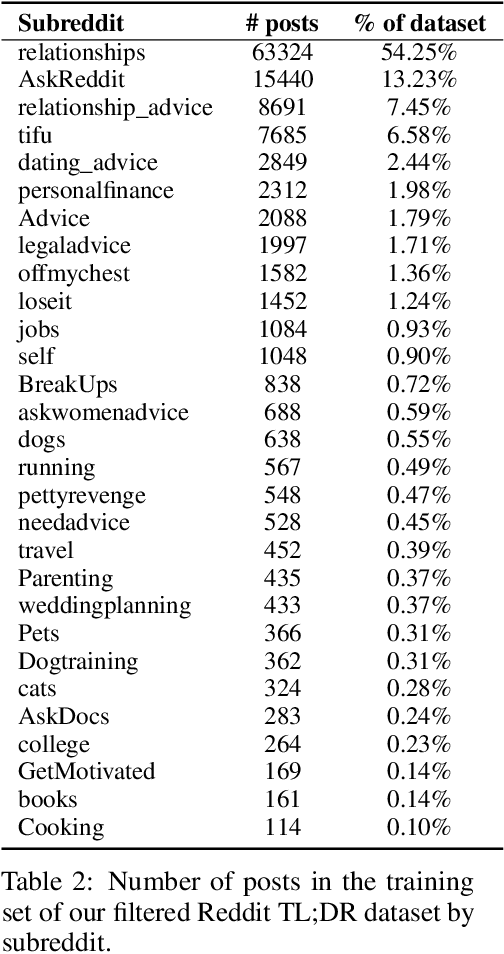
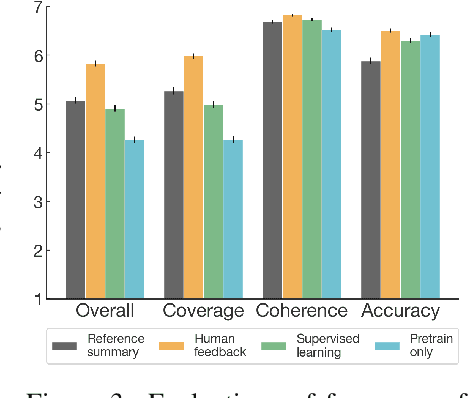
As language models become more powerful, training and evaluation are increasingly bottlenecked by the data and metrics used for a particular task. For example, summarization models are often trained to predict human reference summaries and evaluated using ROUGE, but both of these metrics are rough proxies for what we really care about---summary quality. In this work, we show that it is possible to significantly improve summary quality by training a model to optimize for human preferences. We collect a large, high-quality dataset of human comparisons between summaries, train a model to predict the human-preferred summary, and use that model as a reward function to fine-tune a summarization policy using reinforcement learning. We apply our method to a version of the TL;DR dataset of Reddit posts and find that our models significantly outperform both human reference summaries and much larger models fine-tuned with supervised learning alone. Our models also transfer to CNN/DM news articles, producing summaries nearly as good as the human reference without any news-specific fine-tuning. We conduct extensive analyses to understand our human feedback dataset and fine-tuned models. We establish that our reward model generalizes to new datasets, and that optimizing our reward model results in better summaries than optimizing ROUGE according to humans. We hope the evidence from our paper motivates machine learning researchers to pay closer attention to how their training loss affects the model behavior they actually want.
Bayesian Inference of Regular Expressions from Human-Generated Example Strings
Sep 26, 2018
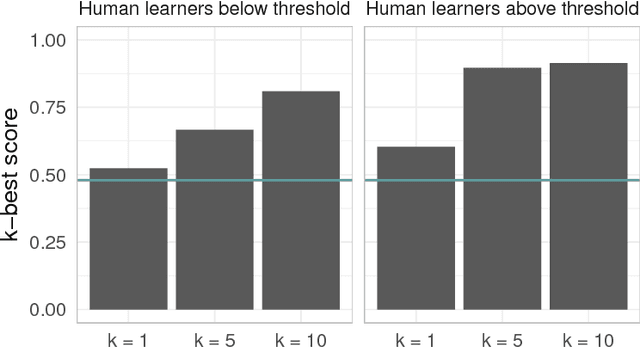
In programming by example, users "write" programs by generating a small number of input-output examples and asking the computer to synthesize consistent programs. We consider a challenging problem in this domain: learning regular expressions (regexes) from positive and negative example strings. This problem is challenging, as (1) user-generated examples may not be informative enough to sufficiently constrain the hypothesis space, and (2) even if user-generated examples are in principle informative, there is still a massive search space to examine. We frame regex induction as the problem of inferring a probabilistic regular grammar and propose an efficient inference approach that uses a novel stochastic process recognition model. This model incrementally "grows" a grammar using positive examples as a scaffold. We show that this approach is competitive with human ability to learn regexes from examples.
Pedagogical learning
Nov 30, 2017

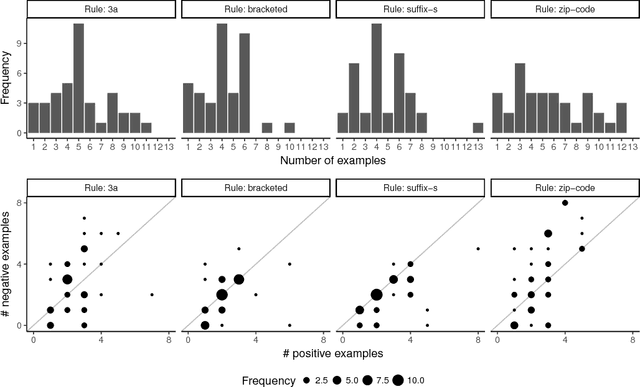
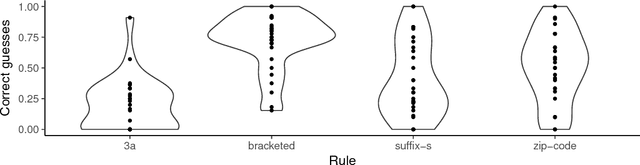
A common assumption in machine learning is that training data are i.i.d. samples from some distribution. Processes that generate i.i.d. samples are, in a sense, uninformative---they produce data without regard to how good this data is for learning. By contrast, cognitive science research has shown that when people generate training data for others (i.e., teaching), they deliberately select examples that are helpful for learning. Because the data is more informative, learning can require less data. Interestingly, such examples are most effective when learners know that the data were pedagogically generated (as opposed to randomly generated). We call this pedagogical learning---when a learner assumes that evidence comes from a helpful teacher. In this work, we ask how pedagogical learning might work for machine learning algorithms. Studying this question requires understanding how people actually teach complex concepts with examples, so we conducted a behavioral study examining how people teach regular expressions using example strings. We found that teachers' examples contain powerful clustering structure that can greatly facilitate learning. We then develop a model of teaching and show a proof of concept that using this model inside of a learner can improve performance.
Practical optimal experiment design with probabilistic programs
Aug 17, 2016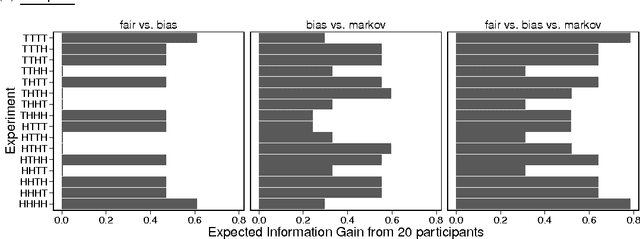

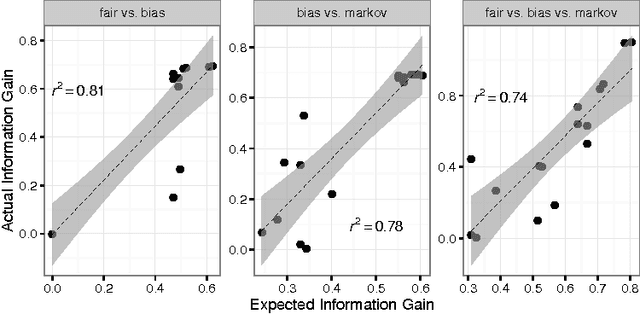

Scientists often run experiments to distinguish competing theories. This requires patience, rigor, and ingenuity - there is often a large space of possible experiments one could run. But we need not comb this space by hand - if we represent our theories as formal models and explicitly declare the space of experiments, we can automate the search for good experiments, looking for those with high expected information gain. Here, we present a general and principled approach to experiment design based on probabilistic programming languages (PPLs). PPLs offer a clean separation between declaring problems and solving them, which means that the scientist can automate experiment design by simply declaring her model and experiment spaces in the PPL without having to worry about the details of calculating information gain. We demonstrate our system in two case studies drawn from cognitive psychology, where we use it to design optimal experiments in the domains of sequence prediction and categorization. We find strong empirical validation that our automatically designed experiments were indeed optimal. We conclude by discussing a number of interesting questions for future research.