 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePedagogical learning
Paper and Code
Nov 30, 2017

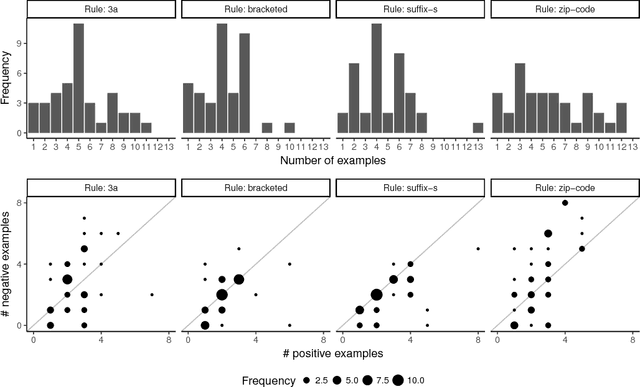
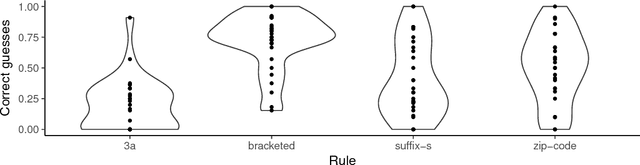
A common assumption in machine learning is that training data are i.i.d. samples from some distribution. Processes that generate i.i.d. samples are, in a sense, uninformative---they produce data without regard to how good this data is for learning. By contrast, cognitive science research has shown that when people generate training data for others (i.e., teaching), they deliberately select examples that are helpful for learning. Because the data is more informative, learning can require less data. Interestingly, such examples are most effective when learners know that the data were pedagogically generated (as opposed to randomly generated). We call this pedagogical learning---when a learner assumes that evidence comes from a helpful teacher. In this work, we ask how pedagogical learning might work for machine learning algorithms. Studying this question requires understanding how people actually teach complex concepts with examples, so we conducted a behavioral study examining how people teach regular expressions using example strings. We found that teachers' examples contain powerful clustering structure that can greatly facilitate learning. We then develop a model of teaching and show a proof of concept that using this model inside of a learner can improve performance.