 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBaby Scale: Investigating Models Trained on Individual Children's Language Input
Mar 31, 2026Modern language models (LMs) must be trained on many orders of magnitude more words of training data than human children receive before they begin to produce useful behavior. Assessing the nature and origins of this "data gap" requires benchmarking LMs on human-scale datasets to understand how linguistic knowledge emerges from children's natural training data. Using transcripts from the BabyView dataset (videos from children ages 6-36 months), we investigate (1) scaling performance at child-scale data regimes, (2) variability in model performance across datasets from different children's experiences and linguistic predictors of dataset quality, and (3) relationships between model and child language learning outcomes. LMs trained on child data show acceptable scaling for grammar tasks, but lower scaling on semantic and world knowledge tasks than models trained on synthetic data; we also observe substantial variability on data from different children. Beyond dataset size, performance is most associated with a combination of distributional and interactional linguistic features, broadly consistent with what makes high-quality input for child language development. Finally, model likelihoods for individual words correlate with children's learning of those words, suggesting that properties of child-directed input may influence both model learning and human language development. Overall, understanding what properties make language data efficient for learning can enable more powerful small-scale language models while also shedding light on human language acquisition.
Bringing Up a Bilingual BabyLM: Investigating Multilingual Language Acquisition Using Small-Scale Models
Mar 31, 2026Multilingualism is incredibly common around the world, leading to many important theoretical and practical questions about how children learn multiple languages at once. For example, does multilingual acquisition lead to delays in learning? Are there better and worse ways to structure multilingual input? Many correlational studies address these questions, but it is surprisingly difficult to get definitive answers because children cannot be randomly assigned to be multilingual and data are typically not matched between languages. We use language model training as a method for simulating a variety of highly controlled exposure conditions, and create matched 100M-word mono- and bilingual datasets using synthetic data and machine translation. We train GPT-2 models on monolingual and bilingual data organized to reflect a range of exposure regimes, and evaluate their performance on perplexity, grammaticality, and semantic knowledge. Across model scales and measures, bilingual models perform similarly to monolingual models in one language, but show strong performance in the second language as well. These results suggest that there are no strong differences between different bilingual exposure regimes, and that bilingual input poses no in-principle challenges for agnostic statistical learners.
Context informs pragmatic interpretation in vision-language models
Nov 05, 2025Iterated reference games - in which players repeatedly pick out novel referents using language - present a test case for agents' ability to perform context-sensitive pragmatic reasoning in multi-turn linguistic environments. We tested humans and vision-language models on trials from iterated reference games, varying the given context in terms of amount, order, and relevance. Without relevant context, models were above chance but substantially worse than humans. However, with relevant context, model performance increased dramatically over trials. Few-shot reference games with abstract referents remain a difficult task for machine learning models.
Is Child-Directed Speech Effective Training Data for Language Models?
Aug 07, 2024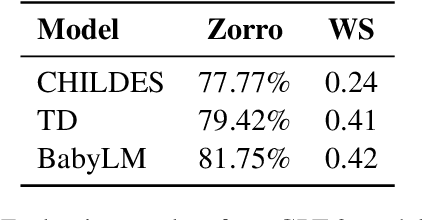
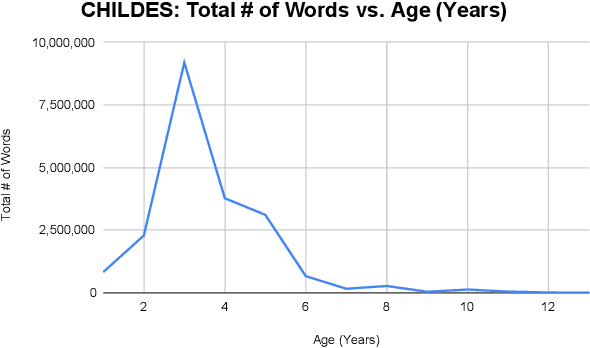

While high-performing language models are typically trained on hundreds of billions of words, human children become fluent language users with a much smaller amount of data. What are the features of the data they receive, and how do these features support language modeling objectives? To investigate this question, we train GPT-2 models on 29M words of English-language child-directed speech and a new matched, synthetic dataset (TinyDialogues), comparing to a heterogeneous blend of datasets from the BabyLM challenge. We evaluate both the syntactic and semantic knowledge of these models using developmentally-inspired evaluations. Through pretraining experiments, we test whether the global developmental ordering or the local discourse ordering of children's training data support high performance relative to other datasets. The local properties of the data affect model results, but somewhat surprisingly, global properties do not. Further, child language input is not uniquely valuable for training language models. These findings support the hypothesis that, rather than proceeding from better data, children's learning is instead substantially more efficient than current language modeling techniques.
The BabyView dataset: High-resolution egocentric videos of infants' and young children's everyday experiences
Jun 14, 2024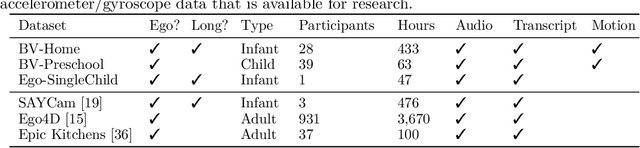
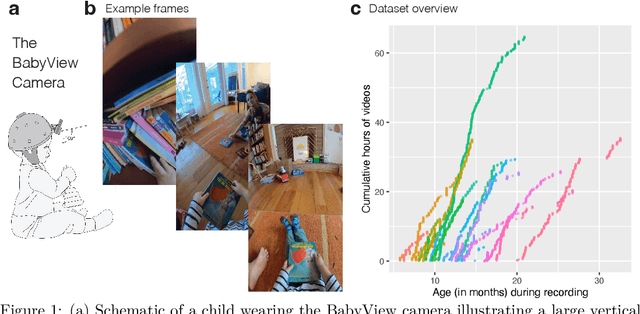
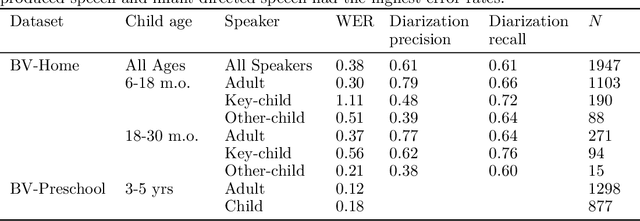
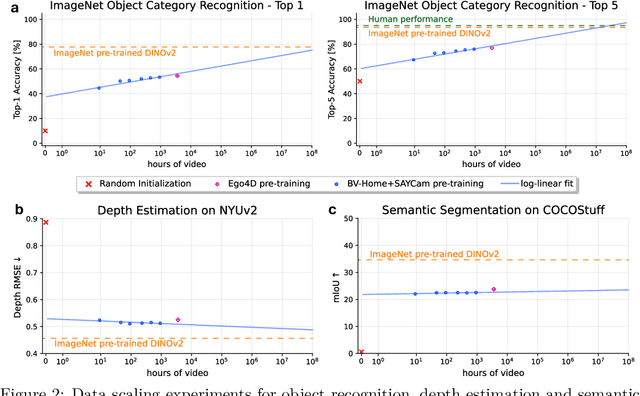
Human children far exceed modern machine learning algorithms in their sample efficiency, achieving high performance in key domains with much less data than current models. This ''data gap'' is a key challenge both for building intelligent artificial systems and for understanding human development. Egocentric video capturing children's experience -- their ''training data'' -- is a key ingredient for comparison of humans and models and for the development of algorithmic innovations to bridge this gap. Yet there are few such datasets available, and extant data are low-resolution, have limited metadata, and importantly, represent only a small set of children's experiences. Here, we provide the first release of the largest developmental egocentric video dataset to date -- the BabyView dataset -- recorded using a high-resolution camera with a large vertical field-of-view and gyroscope/accelerometer data. This 493 hour dataset includes egocentric videos from children spanning 6 months - 5 years of age in both longitudinal, at-home contexts and in a preschool environment. We provide gold-standard annotations for the evaluation of speech transcription, speaker diarization, and human pose estimation, and evaluate models in each of these domains. We train self-supervised language and vision models and evaluate their transfer to out-of-distribution tasks including syntactic structure learning, object recognition, depth estimation, and image segmentation. Although performance in each scales with dataset size, overall performance is relatively lower than when models are trained on curated datasets, especially in the visual domain. Our dataset stands as an open challenge for robust, humanlike AI systems: how can such systems achieve human-levels of success on the same scale and distribution of training data as humans?
DevBench: A multimodal developmental benchmark for language learning
Jun 14, 2024How (dis)similar are the learning trajectories of vision-language models and children? Recent modeling work has attempted to understand the gap between models' and humans' data efficiency by constructing models trained on less data, especially multimodal naturalistic data. However, such models are often evaluated on adult-level benchmarks, with limited breadth in language abilities tested, and without direct comparison to behavioral data. We introduce DevBench, a multimodal benchmark comprising seven language evaluation tasks spanning the domains of lexical, syntactic, and semantic ability, with behavioral data from both children and adults. We evaluate a set of vision-language models on these tasks, comparing models and humans not only on accuracy but on their response patterns. Across tasks, models exhibit variation in their closeness to human response patterns, and models that perform better on a task also more closely resemble human behavioral responses. We also examine the developmental trajectory of OpenCLIP over training, finding that greater training results in closer approximations to adult response patterns. DevBench thus provides a benchmark for comparing models to human language development. These comparisons highlight ways in which model and human language learning processes diverge, providing insight into entry points for improving language models.
Auxiliary task demands mask the capabilities of smaller language models
Apr 03, 2024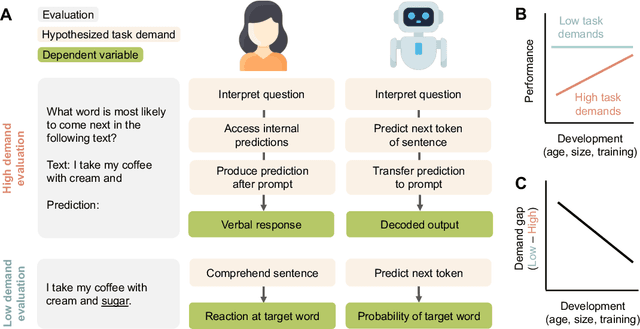
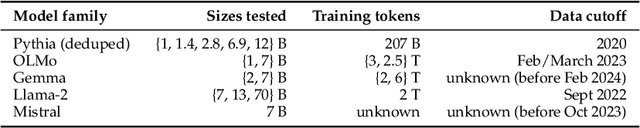
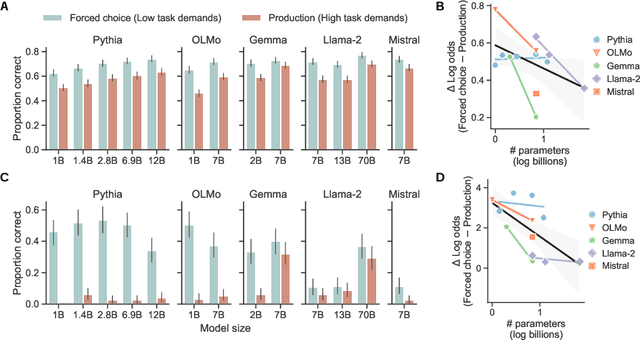
Developmental psychologists have argued about when cognitive capacities such as language understanding or theory of mind emerge. These debates often hinge on the concept of "task demands" -- the auxiliary challenges associated with performing a particular evaluation -- that may mask the child's underlying ability. The same issues arise when measuring the capacities of language models (LMs): performance on a task is a function of the model's underlying competence, combined with the model's ability to interpret and perform the task given its available resources. Here, we show that for analogical reasoning, reflective reasoning, word prediction, and grammaticality judgments, evaluation methods with greater task demands yield lower performance than evaluations with reduced demands. This "demand gap" is most pronounced for models with fewer parameters and less training data. Our results illustrate that LM performance should not be interpreted as a direct indication of intelligence (or lack thereof), but as a reflection of capacities seen through the lens of researchers' design choices.
Learning the meanings of function words from grounded language using a visual question answering model
Aug 16, 2023



Interpreting a seemingly-simple function word like "or", "behind", or "more" can require logical, numerical, and relational reasoning. How are such words learned by children? Prior acquisition theories have often relied on positing a foundation of innate knowledge. Yet recent neural-network based visual question answering models apparently can learn to use function words as part of answering questions about complex visual scenes. In this paper, we study what these models learn about function words, in the hope of better understanding how the meanings of these words can be learnt by both models and children. We show that recurrent models trained on visually grounded language learn gradient semantics for function words requiring spacial and numerical reasoning. Furthermore, we find that these models can learn the meanings of logical connectives "and" and "or" without any prior knowledge of logical reasoning, as well as early evidence that they can develop the ability to reason about alternative expressions when interpreting language. Finally, we show that word learning difficulty is dependent on frequency in models' input. Our findings offer evidence that it is possible to learn the meanings of function words in visually grounded context by using non-symbolic general statistical learning algorithms, without any prior knowledge of linguistic meaning.
The Emergence of the Shape Bias Results from Communicative Efficiency
Sep 15, 2021
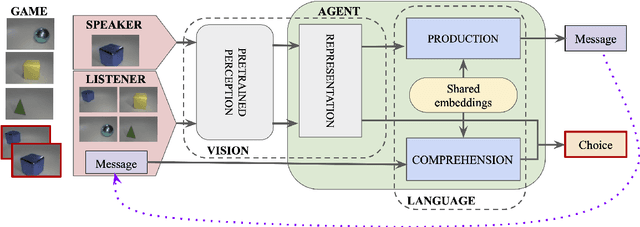
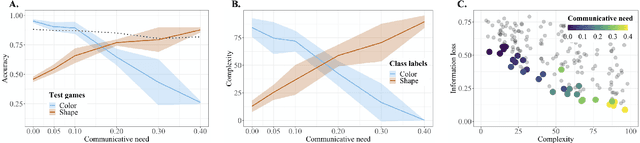
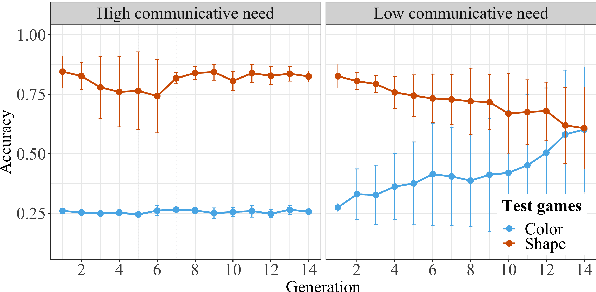
By the age of two, children tend to assume that new word categories are based on objects' shape, rather than their color or texture; this assumption is called the shape bias. They are thought to learn this bias by observing that their caregiver's language is biased towards shape based categories. This presents a chicken and egg problem: if the shape bias must be present in the language in order for children to learn it, how did it arise in language in the first place? In this paper, we propose that communicative efficiency explains both how the shape bias emerged and why it persists across generations. We model this process with neural emergent language agents that learn to communicate about raw pixelated images. First, we show that the shape bias emerges as a result of efficient communication strategies employed by agents. Second, we show that pressure brought on by communicative need is also necessary for it to persist across generations; simply having a shape bias in an agent's input language is insufficient. These results suggest that, over and above the operation of other learning strategies, the shape bias in human learners may emerge and be sustained by communicative pressures.
From partners to populations: A hierarchical Bayesian account of coordination and convention
Apr 12, 2021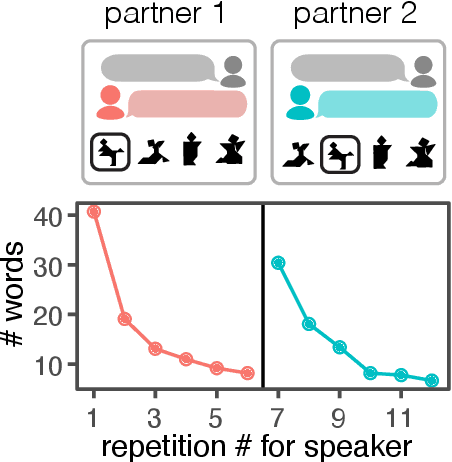
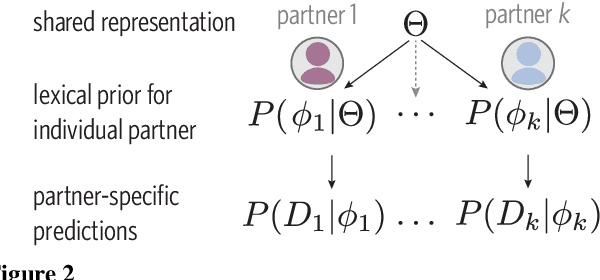
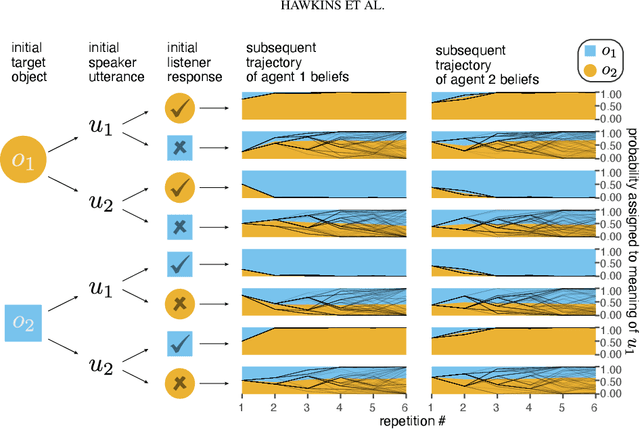
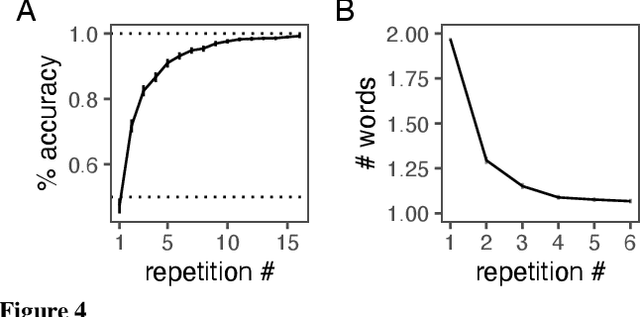
Languages are powerful solutions to coordination problems: they provide stable, shared expectations about how the words we say correspond to the beliefs and intentions in our heads. Yet language use in a variable and non-stationary social environment requires linguistic representations to be flexible: old words acquire new ad hoc or partner-specific meanings on the fly. In this paper, we introduce a hierarchical Bayesian theory of convention formation that aims to reconcile the long-standing tension between these two basic observations. More specifically, we argue that the central computational problem of communication is not simply transmission, as in classical formulations, but learning and adaptation over multiple timescales. Under our account, rapid learning within dyadic interactions allows for coordination on partner-specific common ground, while social conventions are stable priors that have been abstracted away from interactions with multiple partners. We present new empirical data alongside simulations showing how our model provides a cognitive foundation for explaining several phenomena that have posed a challenge for previous accounts: (1) the convergence to more efficient referring expressions across repeated interaction with the same partner, (2) the gradual transfer of partner-specific common ground to novel partners, and (3) the influence of communicative context on which conventions eventually form.