 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuxiliary task demands mask the capabilities of smaller language models
Paper and Code
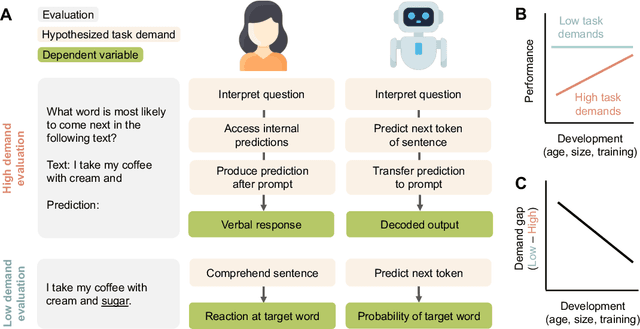
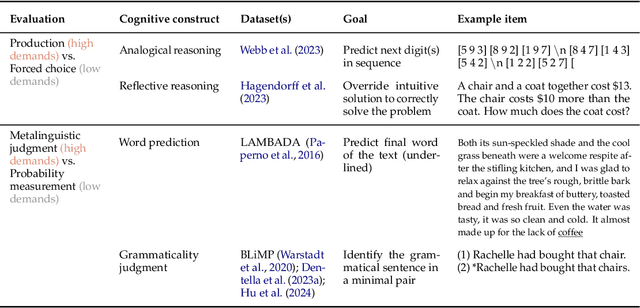
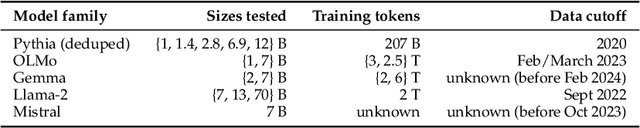
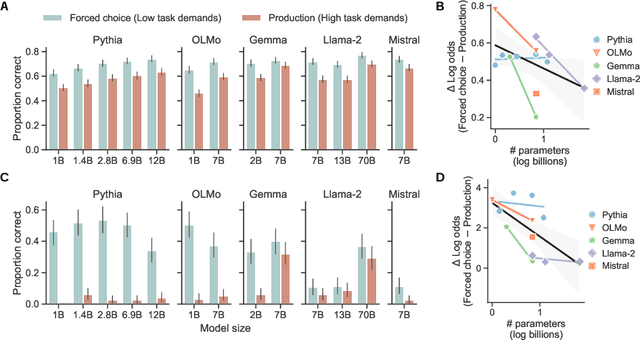
Developmental psychologists have argued about when cognitive capacities such as language understanding or theory of mind emerge. These debates often hinge on the concept of "task demands" -- the auxiliary challenges associated with performing a particular evaluation -- that may mask the child's underlying ability. The same issues arise when measuring the capacities of language models (LMs): performance on a task is a function of the model's underlying competence, combined with the model's ability to interpret and perform the task given its available resources. Here, we show that for analogical reasoning, reflective reasoning, word prediction, and grammaticality judgments, evaluation methods with greater task demands yield lower performance than evaluations with reduced demands. This "demand gap" is most pronounced for models with fewer parameters and less training data. Our results illustrate that LM performance should not be interpreted as a direct indication of intelligence (or lack thereof), but as a reflection of capacities seen through the lens of researchers' design choices.