 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDevBench: A multimodal developmental benchmark for language learning
Jun 14, 2024How (dis)similar are the learning trajectories of vision-language models and children? Recent modeling work has attempted to understand the gap between models' and humans' data efficiency by constructing models trained on less data, especially multimodal naturalistic data. However, such models are often evaluated on adult-level benchmarks, with limited breadth in language abilities tested, and without direct comparison to behavioral data. We introduce DevBench, a multimodal benchmark comprising seven language evaluation tasks spanning the domains of lexical, syntactic, and semantic ability, with behavioral data from both children and adults. We evaluate a set of vision-language models on these tasks, comparing models and humans not only on accuracy but on their response patterns. Across tasks, models exhibit variation in their closeness to human response patterns, and models that perform better on a task also more closely resemble human behavioral responses. We also examine the developmental trajectory of OpenCLIP over training, finding that greater training results in closer approximations to adult response patterns. DevBench thus provides a benchmark for comparing models to human language development. These comparisons highlight ways in which model and human language learning processes diverge, providing insight into entry points for improving language models.
The BabyView dataset: High-resolution egocentric videos of infants' and young children's everyday experiences
Jun 14, 2024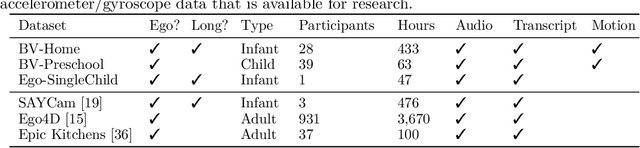
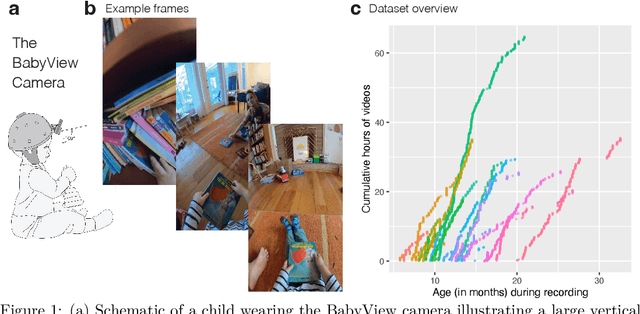
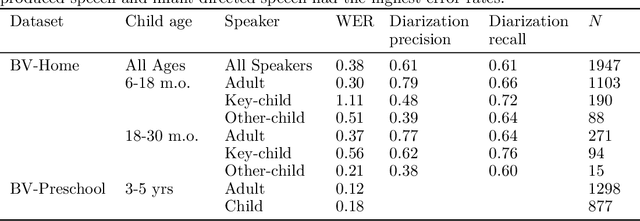
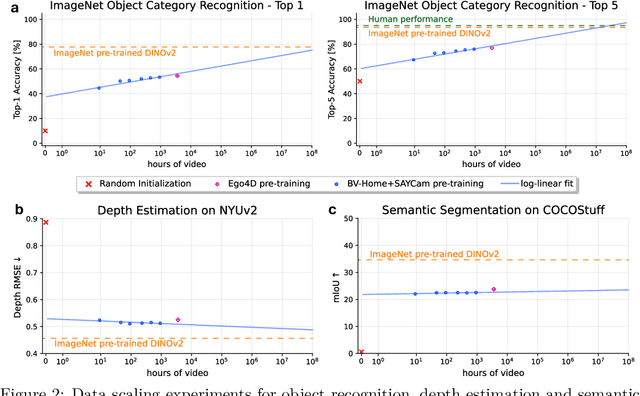
Human children far exceed modern machine learning algorithms in their sample efficiency, achieving high performance in key domains with much less data than current models. This ''data gap'' is a key challenge both for building intelligent artificial systems and for understanding human development. Egocentric video capturing children's experience -- their ''training data'' -- is a key ingredient for comparison of humans and models and for the development of algorithmic innovations to bridge this gap. Yet there are few such datasets available, and extant data are low-resolution, have limited metadata, and importantly, represent only a small set of children's experiences. Here, we provide the first release of the largest developmental egocentric video dataset to date -- the BabyView dataset -- recorded using a high-resolution camera with a large vertical field-of-view and gyroscope/accelerometer data. This 493 hour dataset includes egocentric videos from children spanning 6 months - 5 years of age in both longitudinal, at-home contexts and in a preschool environment. We provide gold-standard annotations for the evaluation of speech transcription, speaker diarization, and human pose estimation, and evaluate models in each of these domains. We train self-supervised language and vision models and evaluate their transfer to out-of-distribution tasks including syntactic structure learning, object recognition, depth estimation, and image segmentation. Although performance in each scales with dataset size, overall performance is relatively lower than when models are trained on curated datasets, especially in the visual domain. Our dataset stands as an open challenge for robust, humanlike AI systems: how can such systems achieve human-levels of success on the same scale and distribution of training data as humans?