 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest-time Adversarial Takeover: A Real-time Hijacking Interface against Robotic Diffusion Policies
Jun 09, 2026Diffusion-based action generation has become a foundational component of embodied AI, but its reliance on visual conditioning leaves deployed visuomotor policies vulnerable to adversarial manipulation. Most prior attacks focus on disruption: they perturb the observation stream to reduce task success or induce erratic behavior. We study a stronger threat, Test-time Adversarial Takeover (TAKO), in which an attacker obtains a real-time steering interface over a frozen robot policy and turns it into a remotely piloted instrument. TAKO learns a small vocabulary of reusable universal patches through differentiable diffusion inference; at test time, the attacker switches among these patches in the camera stream to compose attacker-chosen trajectories. This works because the perturbation acts on the visual conditioning pathway, where the induced bias can persist through iterative generative inference. We further show that the natural targeted baseline, target-policy matching, fails because the victim policy cannot reliably supervise itself on out-of-distribution target shifts. Across four tasks (2D manipulation, simulated aerial delivery, simulated ground navigation, and physical-world ground navigation), two visual encoders (ResNet-18 and EfficientNet-B0 + Transformer), and three generative inference families (DDPM, DDIM, and flow matching), human operators achieve 100\% takeover success on attacker-defined objectives in every evaluated setting. The project page is available at https://tako-attack.github.io.
FeasibleCap: Real-Time Embodiment Constraint Guidance for In-the-Wild Robot Demonstration Collection
Mar 08, 2026Gripper-in-hand data collection decouples demonstration acquisition from robot hardware, but whether a trajectory is executable on the target robot remains unknown until a separate replay-and-validate stage. Failed demonstrations therefore inflate the effective cost per usable trajectory through repeated collection, diagnosis, and validation. Existing collection-time feedback systems mitigate this issue but rely on head-worn AR/VR displays, robot-in-the-loop hardware, or learned dynamics models; real-time executability feedback has not yet been integrated into the gripper-in-hand data collection paradigm. We present \textbf{FeasibleCap}, a gripper-in-hand data collection system that brings real-time executability guidance into robot-free capture. At each frame, FeasibleCap checks reachability, joint-rate limits, and collisions against a target robot model and closes the loop through on-device visual overlays and haptic cues, allowing demonstrators to correct motions during collection without learned models, headsets, or robot hardware. On pick-and-place and tossing tasks, FeasibleCap improves replay success and reduces the fraction of infeasible frames, with the largest gains on tossing. Simulation experiments further indicate that enforcing executability constraints during collection does not sacrifice cross-embodiment transfer across robot platforms. Hardware designs and software are available at https://github.com/aod321/FeasibleCap.
RAPID: Reconfigurable, Adaptive Platform for Iterative Design
Feb 06, 2026Developing robotic manipulation policies is iterative and hypothesis-driven: researchers test tactile sensing, gripper geometries, and sensor placements through real-world data collection and training. Yet even minor end-effector changes often require mechanical refitting and system re-integration, slowing iteration. We present RAPID, a full-stack reconfigurable platform designed to reduce this friction. RAPID is built around a tool-free, modular hardware architecture that unifies handheld data collection and robot deployment, and a matching software stack that maintains real-time awareness of the underlying hardware configuration through a driver-level Physical Mask derived from USB events. This modular hardware architecture reduces reconfiguration to seconds and makes systematic multi-modal ablation studies practical, allowing researchers to sweep diverse gripper and sensing configurations without repeated system bring-up. The Physical Mask exposes modality presence as an explicit runtime signal, enabling auto-configuration and graceful degradation under sensor hot-plug events, so policies can continue executing when sensors are physically added or removed. System-centric experiments show that RAPID reduces the setup time for multi-modal configurations by two orders of magnitude compared to traditional workflows and preserves policy execution under runtime sensor hot-unplug events. The hardware designs, drivers, and software stack are open-sourced at https://rapid-kit.github.io/ .
SciFig: Towards Automating Scientific Figure Generation
Jan 07, 2026Creating high-quality figures and visualizations for scientific papers is a time-consuming task that requires both deep domain knowledge and professional design skills. Despite over 2.5 million scientific papers published annually, the figure generation process remains largely manual. We introduce $\textbf{SciFig}$, an end-to-end AI agent system that generates publication-ready pipeline figures directly from research paper texts. SciFig uses a hierarchical layout generation strategy, which parses research descriptions to identify component relationships, groups related elements into functional modules, and generates inter-module connections to establish visual organization. Furthermore, an iterative chain-of-thought (CoT) feedback mechanism progressively improves layouts through multiple rounds of visual analysis and reasoning. We introduce a rubric-based evaluation framework that analyzes 2,219 real scientific figures to extract evaluation rubrics and automatically generates comprehensive evaluation criteria. SciFig demonstrates remarkable performance: achieving 70.1$\%$ overall quality on dataset-level evaluation and 66.2$\%$ on paper-specific evaluation, and consistently high scores across metrics such as visual clarity, structural organization, and scientific accuracy. SciFig figure generation pipeline and our evaluation benchmark will be open-sourced.
The BabyView dataset: High-resolution egocentric videos of infants' and young children's everyday experiences
Jun 14, 2024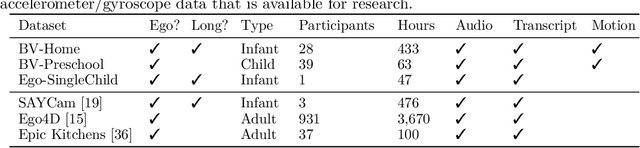
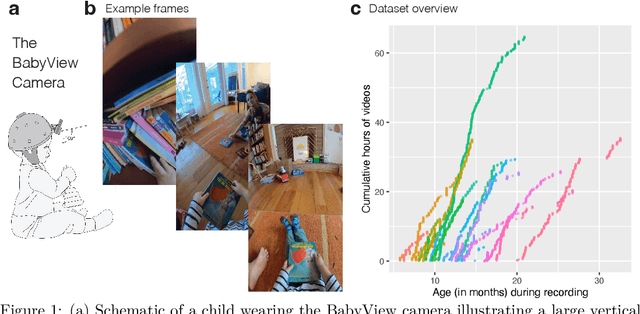
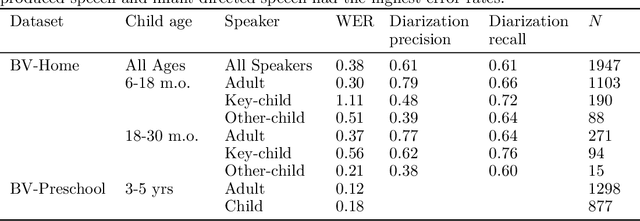
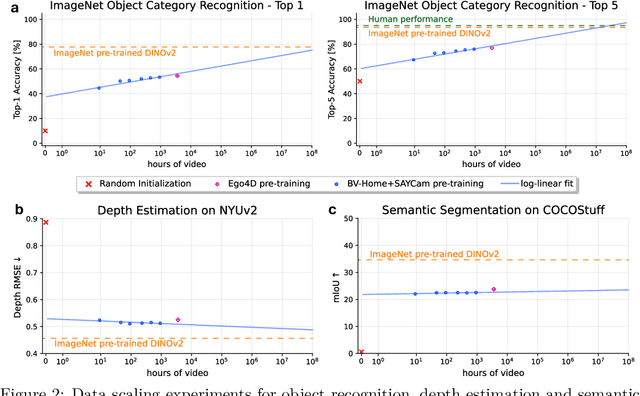
Human children far exceed modern machine learning algorithms in their sample efficiency, achieving high performance in key domains with much less data than current models. This ''data gap'' is a key challenge both for building intelligent artificial systems and for understanding human development. Egocentric video capturing children's experience -- their ''training data'' -- is a key ingredient for comparison of humans and models and for the development of algorithmic innovations to bridge this gap. Yet there are few such datasets available, and extant data are low-resolution, have limited metadata, and importantly, represent only a small set of children's experiences. Here, we provide the first release of the largest developmental egocentric video dataset to date -- the BabyView dataset -- recorded using a high-resolution camera with a large vertical field-of-view and gyroscope/accelerometer data. This 493 hour dataset includes egocentric videos from children spanning 6 months - 5 years of age in both longitudinal, at-home contexts and in a preschool environment. We provide gold-standard annotations for the evaluation of speech transcription, speaker diarization, and human pose estimation, and evaluate models in each of these domains. We train self-supervised language and vision models and evaluate their transfer to out-of-distribution tasks including syntactic structure learning, object recognition, depth estimation, and image segmentation. Although performance in each scales with dataset size, overall performance is relatively lower than when models are trained on curated datasets, especially in the visual domain. Our dataset stands as an open challenge for robust, humanlike AI systems: how can such systems achieve human-levels of success on the same scale and distribution of training data as humans?
Alignment is not sufficient to prevent large language models from generating harmful information: A psychoanalytic perspective
Nov 14, 2023Large Language Models (LLMs) are central to a multitude of applications but struggle with significant risks, notably in generating harmful content and biases. Drawing an analogy to the human psyche's conflict between evolutionary survival instincts and societal norm adherence elucidated in Freud's psychoanalysis theory, we argue that LLMs suffer a similar fundamental conflict, arising between their inherent desire for syntactic and semantic continuity, established during the pre-training phase, and the post-training alignment with human values. This conflict renders LLMs vulnerable to adversarial attacks, wherein intensifying the models' desire for continuity can circumvent alignment efforts, resulting in the generation of harmful information. Through a series of experiments, we first validated the existence of the desire for continuity in LLMs, and further devised a straightforward yet powerful technique, such as incomplete sentences, negative priming, and cognitive dissonance scenarios, to demonstrate that even advanced LLMs struggle to prevent the generation of harmful information. In summary, our study uncovers the root of LLMs' vulnerabilities to adversarial attacks, hereby questioning the efficacy of solely relying on sophisticated alignment methods, and further advocates for a new training idea that integrates modal concepts alongside traditional amodal concepts, aiming to endow LLMs with a more nuanced understanding of real-world contexts and ethical considerations.
Emotional Intelligence of Large Language Models
Jul 28, 2023Large Language Models (LLMs) have demonstrated remarkable abilities across numerous disciplines, primarily assessed through tasks in language generation, knowledge utilization, and complex reasoning. However, their alignment with human emotions and values, which is critical for real-world applications, has not been systematically evaluated. Here, we assessed LLMs' Emotional Intelligence (EI), encompassing emotion recognition, interpretation, and understanding, which is necessary for effective communication and social interactions. Specifically, we first developed a novel psychometric assessment focusing on Emotion Understanding (EU), a core component of EI, suitable for both humans and LLMs. This test requires evaluating complex emotions (e.g., surprised, joyful, puzzled, proud) in realistic scenarios (e.g., despite feeling underperformed, John surprisingly achieved a top score). With a reference frame constructed from over 500 adults, we tested a variety of mainstream LLMs. Most achieved above-average EQ scores, with GPT-4 exceeding 89% of human participants with an EQ of 117. Interestingly, a multivariate pattern analysis revealed that some LLMs apparently did not reply on the human-like mechanism to achieve human-level performance, as their representational patterns were qualitatively distinct from humans. In addition, we discussed the impact of factors such as model size, training method, and architecture on LLMs' EQ. In summary, our study presents one of the first psychometric evaluations of the human-like characteristics of LLMs, which may shed light on the future development of LLMs aiming for both high intellectual and emotional intelligence. Project website: https://emotional-intelligence.github.io/
End-to-End Face Parsing via Interlinked Convolutional Neural Networks
Feb 12, 2020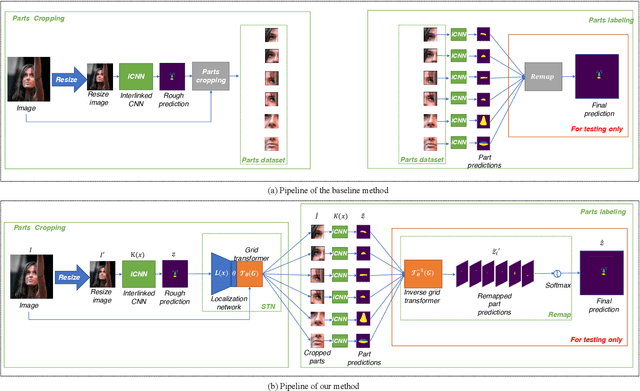

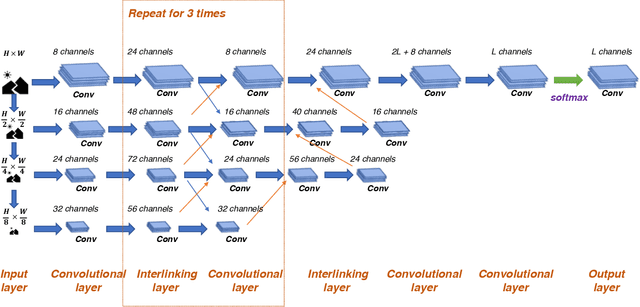
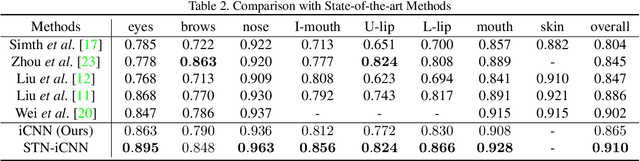
Face parsing is an important computer vision task that requires accurate pixel segmentation of facial parts (such as eyes, nose, mouth, etc.), providing a basis for further face analysis, modification, and other applications. In this paper, we introduce a simple, end-to-end face parsing framework: STN-aided iCNN (STN-iCNN), which extends interlinked Convolutional Neural Network (iCNN) by adding a Spatial Transformer Network (STN) between the two isolated stages. The STN-iCNN uses the STN to provide a trainable connection to the original two-stage iCNN pipe-line, making end-to-end joint training possible. Moreover, as a by-product, STN also provides more precise cropped parts than the original cropper. Due to the two advantages, our approach significantly improves the accuracy of the original model.
The Global Anchor Method for Quantifying Linguistic Shifts and Domain Adaptation
Dec 12, 2018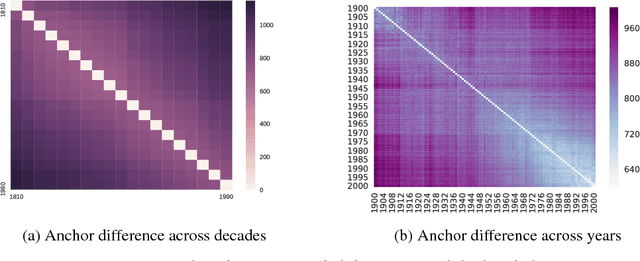
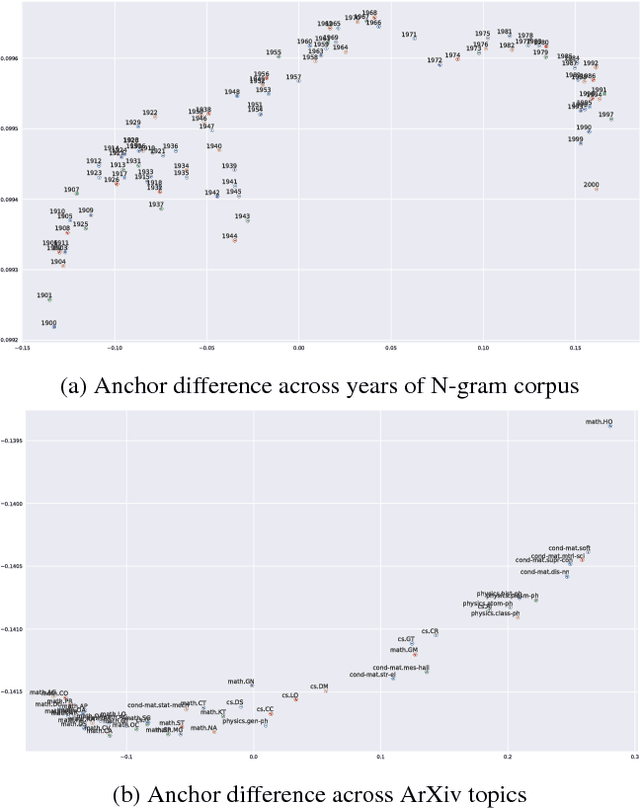
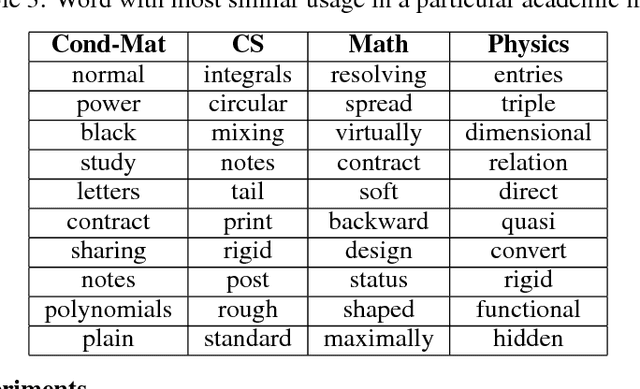
Language is dynamic, constantly evolving and adapting with respect to time, domain or topic. The adaptability of language is an active research area, where researchers discover social, cultural and domain-specific changes in language using distributional tools such as word embeddings. In this paper, we introduce the global anchor method for detecting corpus-level language shifts. We show both theoretically and empirically that the global anchor method is equivalent to the alignment method, a widely-used method for comparing word embeddings, in terms of detecting corpus-level language shifts. Despite their equivalence in terms of detection abilities, we demonstrate that the global anchor method is superior in terms of applicability as it can compare embeddings of different dimensionalities. Furthermore, the global anchor method has implementation and parallelization advantages. We show that the global anchor method reveals fine structures in the evolution of language and domain adaptation. When combined with the graph Laplacian technique, the global anchor method recovers the evolution trajectory and domain clustering of disparate text corpora.
On the Dimensionality of Word Embedding
Dec 11, 2018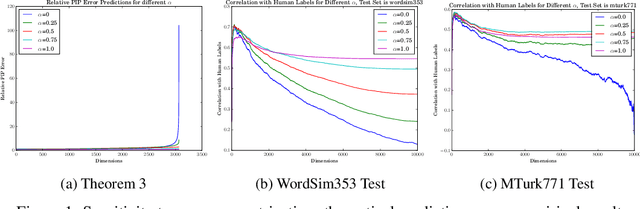
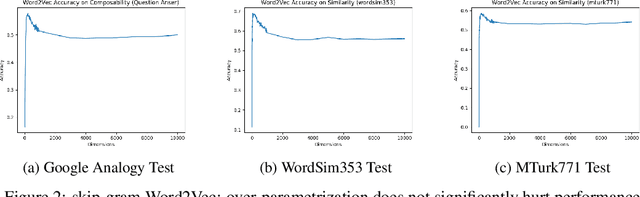
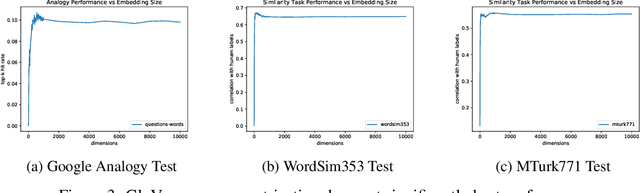
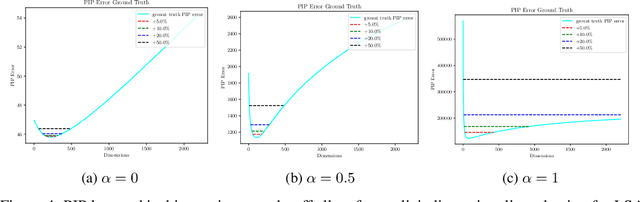
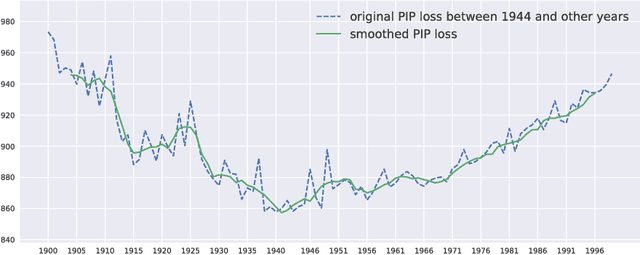
In this paper, we provide a theoretical understanding of word embedding and its dimensionality. Motivated by the unitary-invariance of word embedding, we propose the Pairwise Inner Product (PIP) loss, a novel metric on the dissimilarity between word embeddings. Using techniques from matrix perturbation theory, we reveal a fundamental bias-variance trade-off in dimensionality selection for word embeddings. This bias-variance trade-off sheds light on many empirical observations which were previously unexplained, for example the existence of an optimal dimensionality. Moreover, new insights and discoveries, like when and how word embeddings are robust to over-fitting, are revealed. By optimizing over the bias-variance trade-off of the PIP loss, we can explicitly answer the open question of dimensionality selection for word embedding.