 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Face Parsing via Interlinked Convolutional Neural Networks
Feb 12, 2020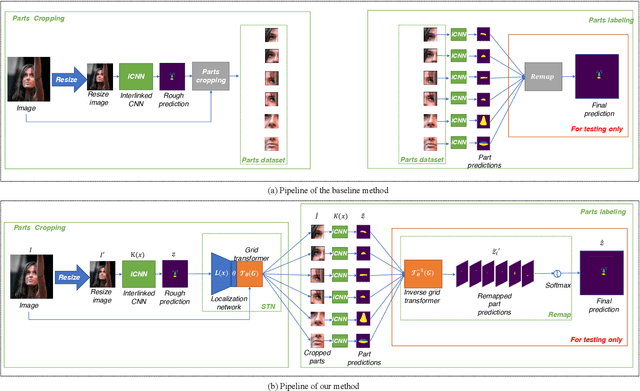

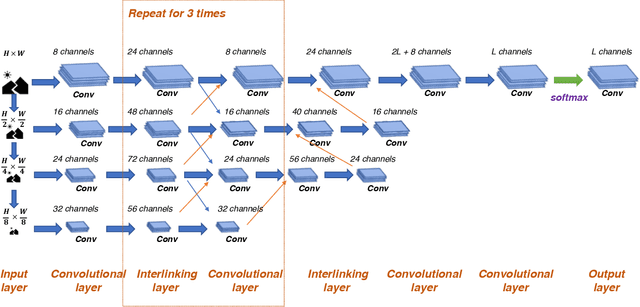
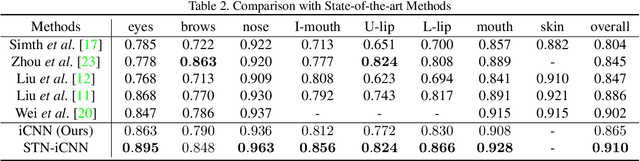
Face parsing is an important computer vision task that requires accurate pixel segmentation of facial parts (such as eyes, nose, mouth, etc.), providing a basis for further face analysis, modification, and other applications. In this paper, we introduce a simple, end-to-end face parsing framework: STN-aided iCNN (STN-iCNN), which extends interlinked Convolutional Neural Network (iCNN) by adding a Spatial Transformer Network (STN) between the two isolated stages. The STN-iCNN uses the STN to provide a trainable connection to the original two-stage iCNN pipe-line, making end-to-end joint training possible. Moreover, as a by-product, STN also provides more precise cropped parts than the original cropper. Due to the two advantages, our approach significantly improves the accuracy of the original model.