 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTail Batch Sampling: Approximating Global Contrastive Losses as Optimization over Batch Assignments
Oct 23, 2022Contrastive Learning has recently achieved state-of-the-art performance in a wide range of tasks. Many contrastive learning approaches use mined hard negatives to make batches more informative during training but these approaches are inefficient as they increase epoch length proportional to the number of mined negatives and require frequent updates of nearest neighbor indices or mining from recent batches. In this work, we provide an alternative to hard negative mining in supervised contrastive learning, Tail Batch Sampling (TBS), an efficient approximation to the batch assignment problem that upper bounds the gap between the global and training losses, $\mathcal{L}^{Global} - \mathcal{L}^{Train}$. TBS \textbf{improves state-of-the-art performance} in sentence embedding (+0.37 Spearman) and code-search tasks (+2.2\% MRR), is easy to implement - requiring only a few additional lines of code, does not maintain external data structures such as nearest neighbor indices, is more computationally efficient when compared to the most minimal hard negative mining approaches, and makes no changes to the model being trained.
CALM: Contrastive Aligned Audio-Language Multirate and Multimodal Representations
Feb 08, 2022Deriving multimodal representations of audio and lexical inputs is a central problem in Natural Language Understanding (NLU). In this paper, we present Contrastive Aligned Audio-Language Multirate and Multimodal Representations (CALM), an approach for learning multimodal representations using contrastive and multirate information inherent in audio and lexical inputs. The proposed model aligns acoustic and lexical information in the input embedding space of a pretrained language-only contextual embedding model. By aligning audio representations to pretrained language representations and utilizing contrastive information between acoustic inputs, CALM is able to bootstrap audio embedding competitive with existing audio representation models in only a few hours of training time. Operationally, audio spectrograms are processed using linearized patches through a Spectral Transformer (SpecTran) which is trained using a Contrastive Audio-Language Pretraining objective to align audio and language from similar queries. Subsequently, the derived acoustic and lexical tokens representations are input into a multimodal transformer to incorporate utterance level context and derive the proposed CALM representations. We show that these pretrained embeddings can subsequently be used in multimodal supervised tasks and demonstrate the benefits of the proposed pretraining steps in terms of the alignment of the two embedding spaces and the multirate nature of the pretraining. Our system shows 10-25\% improvement over existing emotion recognition systems including state-of-the-art three-modality systems under various evaluation objectives.
Efficient Domain Adaptation of Language Models via Adaptive Tokenization
Sep 15, 2021
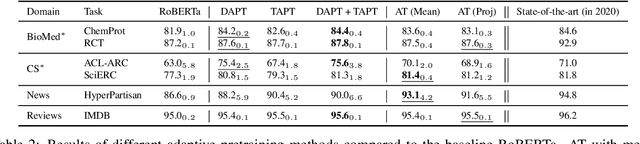

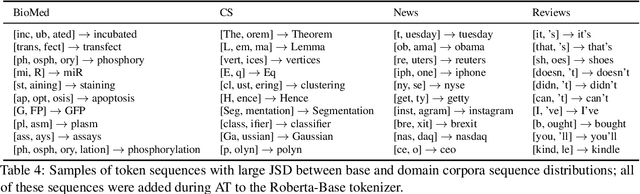
Contextual embedding-based language models trained on large data sets, such as BERT and RoBERTa, provide strong performance across a wide range of tasks and are ubiquitous in modern NLP. It has been observed that fine-tuning these models on tasks involving data from domains different from that on which they were pretrained can lead to suboptimal performance. Recent work has explored approaches to adapt pretrained language models to new domains by incorporating additional pretraining using domain-specific corpora and task data. We propose an alternative approach for transferring pretrained language models to new domains by adapting their tokenizers. We show that domain-specific subword sequences can be efficiently determined directly from divergences in the conditional token distributions of the base and domain-specific corpora. In datasets from four disparate domains, we find adaptive tokenization on a pretrained RoBERTa model provides >97% of the performance benefits of domain specific pretraining. Our approach produces smaller models and less training and inference time than other approaches using tokenizer augmentation. While adaptive tokenization incurs a 6% increase in model parameters in our experimentation, due to the introduction of 10k new domain-specific tokens, our approach, using 64 vCPUs, is 72x faster than further pretraining the language model on domain-specific corpora on 8 TPUs.
Filtered Inner Product Projection for Multilingual Embedding Alignment
Jun 05, 2020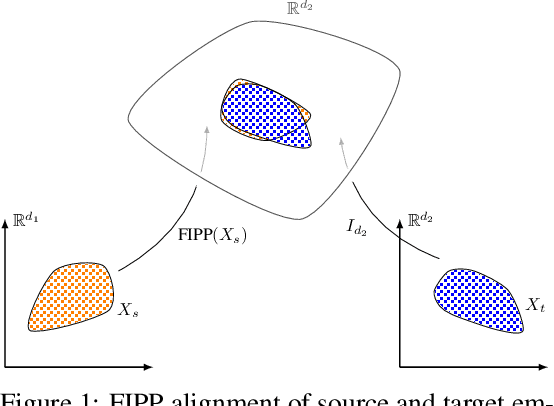
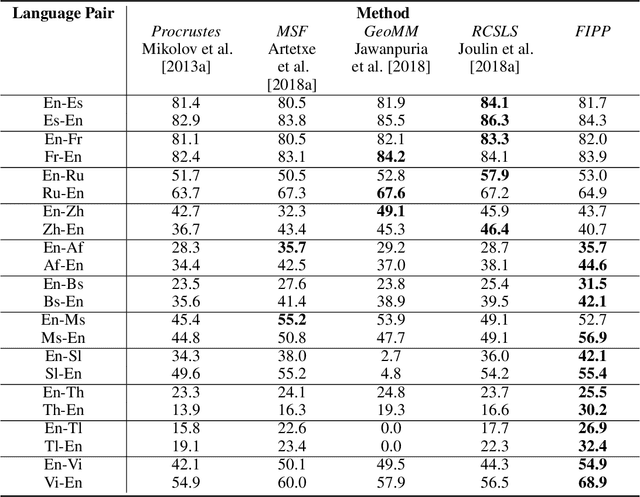
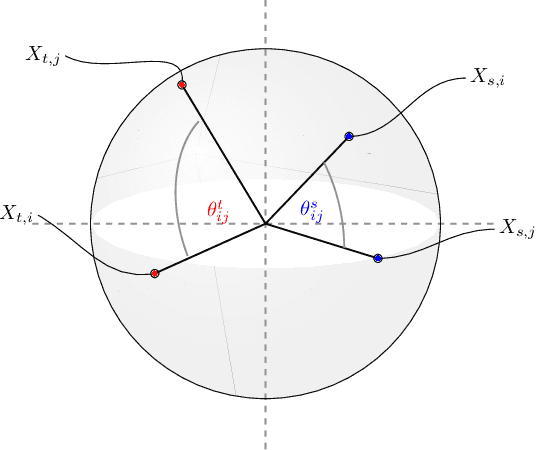

Due to widespread interest in machine translation and transfer learning, there are numerous algorithms for mapping multiple embeddings to a shared representation space. Recently, these algorithms have been studied in the setting of bilingual dictionary induction where one seeks to align the embeddings of a source and a target language such that translated word pairs lie close to one another in a common representation space. In this paper, we propose a method, Filtered Inner Product Projection (FIPP), for mapping embeddings to a common representation space and evaluate FIPP in the context of bilingual dictionary induction. As semantic shifts are pervasive across languages and domains, FIPP first identifies the common geometric structure in both embeddings and then, only on the common structure, aligns the Gram matrices of these embeddings. Unlike previous approaches, FIPP is applicable even when the source and target embeddings are of differing dimensionalities. We show that our approach outperforms existing methods on the MUSE dataset for various language pairs. Furthermore, FIPP provides computational benefits both in ease of implementation and scalability.
Embedding Imputation with Grounded Language Information
Jun 10, 2019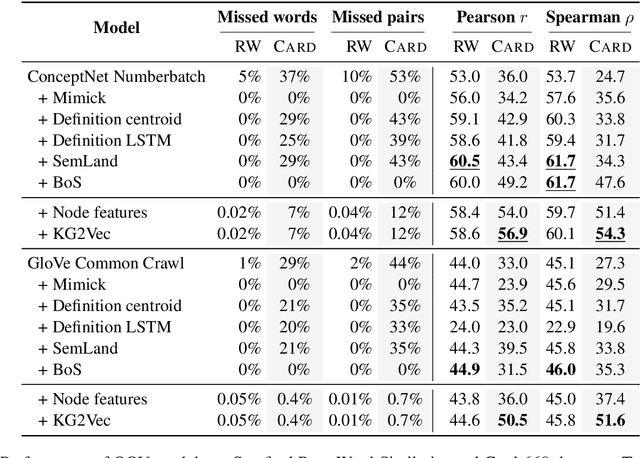
Due to the ubiquitous use of embeddings as input representations for a wide range of natural language tasks, imputation of embeddings for rare and unseen words is a critical problem in language processing. Embedding imputation involves learning representations for rare or unseen words during the training of an embedding model, often in a post-hoc manner. In this paper, we propose an approach for embedding imputation which uses grounded information in the form of a knowledge graph. This is in contrast to existing approaches which typically make use of vector space properties or subword information. We propose an online method to construct a graph from grounded information and design an algorithm to map from the resulting graphical structure to the space of the pre-trained embeddings. Finally, we evaluate our approach on a range of rare and unseen word tasks across various domains and show that our model can learn better representations. For example, on the Card-660 task our method improves Pearson's and Spearman's correlation coefficients upon the state-of-the-art by 11% and 17.8% respectively using GloVe embeddings.
The Global Anchor Method for Quantifying Linguistic Shifts and Domain Adaptation
Dec 12, 2018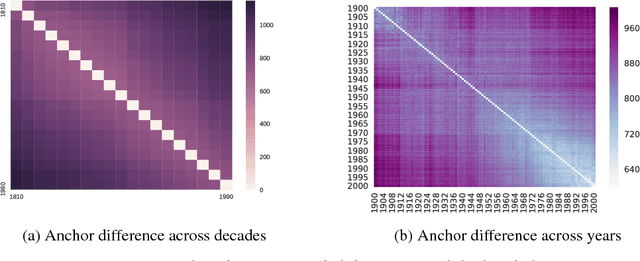
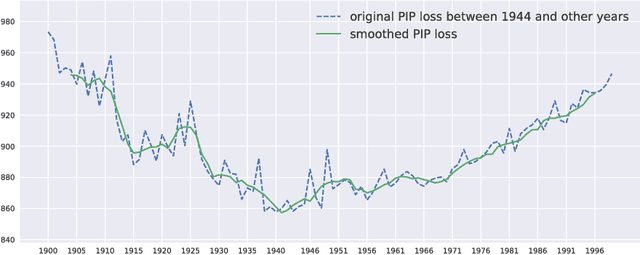
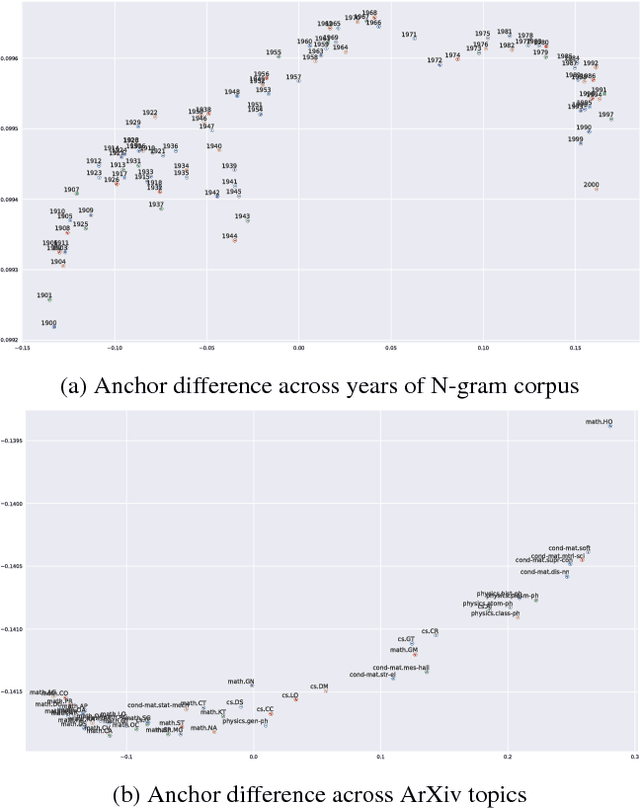
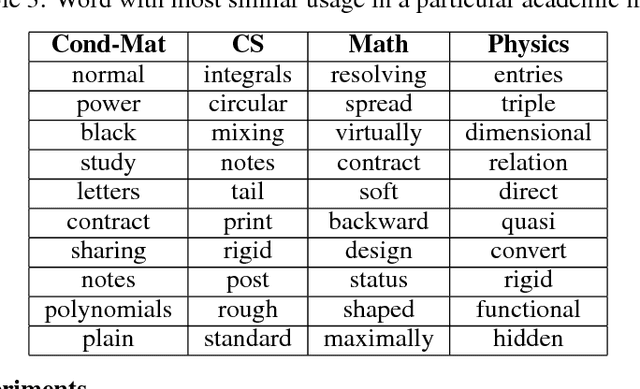
Language is dynamic, constantly evolving and adapting with respect to time, domain or topic. The adaptability of language is an active research area, where researchers discover social, cultural and domain-specific changes in language using distributional tools such as word embeddings. In this paper, we introduce the global anchor method for detecting corpus-level language shifts. We show both theoretically and empirically that the global anchor method is equivalent to the alignment method, a widely-used method for comparing word embeddings, in terms of detecting corpus-level language shifts. Despite their equivalence in terms of detection abilities, we demonstrate that the global anchor method is superior in terms of applicability as it can compare embeddings of different dimensionalities. Furthermore, the global anchor method has implementation and parallelization advantages. We show that the global anchor method reveals fine structures in the evolution of language and domain adaptation. When combined with the graph Laplacian technique, the global anchor method recovers the evolution trajectory and domain clustering of disparate text corpora.