 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAct or Clarify? Modeling Sensitivity to Uncertainty and Cost in Communication
Feb 02, 2026When deciding how to act under uncertainty, agents may choose to act to reduce uncertainty or they may act despite that uncertainty.In communicative settings, an important way of reducing uncertainty is by asking clarification questions (CQs). We predict that the decision to ask a CQ depends on both contextual uncertainty and the cost of alternative actions, and that these factors interact: uncertainty should matter most when acting incorrectly is costly. We formalize this interaction in a computational model based on expected regret: how much an agent stands to lose by acting now rather than with full information. We test these predictions in two experiments, one examining purely linguistic responses to questions and another extending to choices between clarification and non-linguistic action. Taken together, our results suggest a rational tradeoff: humans tend to seek clarification proportional to the risk of substantial loss when acting under uncertainty.
Linking forward-pass dynamics in Transformers and real-time human processing
Apr 18, 2025Modern AI models are increasingly being used as theoretical tools to study human cognition. One dominant approach is to evaluate whether human-derived measures (such as offline judgments or real-time processing) are predicted by a model's output: that is, the end-product of forward pass(es) through the network. At the same time, recent advances in mechanistic interpretability have begun to reveal the internal processes that give rise to model outputs, raising the question of whether models and humans might arrive at outputs using similar "processing strategies". Here, we investigate the link between real-time processing in humans and "layer-time" dynamics in Transformer models. Across five studies spanning domains and modalities, we test whether the dynamics of computation in a single forward pass of pre-trained Transformers predict signatures of processing in humans, above and beyond properties of the model's output probability distribution. We consistently find that layer-time dynamics provide additional predictive power on top of output measures. Our results suggest that Transformer processing and human processing may be facilitated or impeded by similar properties of an input stimulus, and this similarity has emerged through general-purpose objectives such as next-token prediction or image recognition. Our work suggests a new way of using AI models to study human cognition: not just as a black box mapping stimuli to responses, but potentially also as explicit processing models.
Non-literal Understanding of Number Words by Language Models
Feb 10, 2025
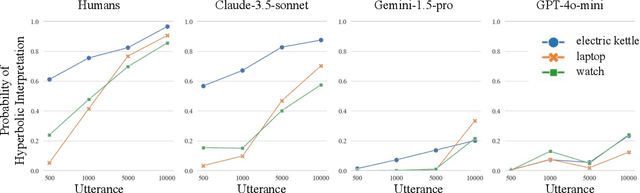

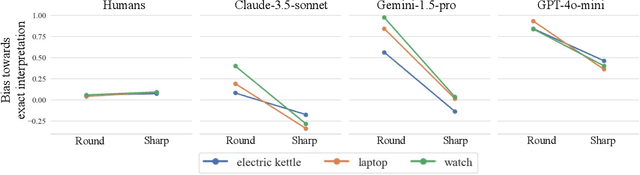
Humans naturally interpret numbers non-literally, effortlessly combining context, world knowledge, and speaker intent. We investigate whether large language models (LLMs) interpret numbers similarly, focusing on hyperbole and pragmatic halo effects. Through systematic comparison with human data and computational models of pragmatic reasoning, we find that LLMs diverge from human interpretation in striking ways. By decomposing pragmatic reasoning into testable components, grounded in the Rational Speech Act framework, we pinpoint where LLM processing diverges from human cognition -- not in prior knowledge, but in reasoning with it. This insight leads us to develop a targeted solution -- chain-of-thought prompting inspired by an RSA model makes LLMs' interpretations more human-like. Our work demonstrates how computational cognitive models can both diagnose AI-human differences and guide development of more human-like language understanding capabilities.
Cognitive Modeling with Scaffolded LLMs: A Case Study of Referential Expression Generation
Jul 04, 2024To what extent can LLMs be used as part of a cognitive model of language generation? In this paper, we approach this question by exploring a neuro-symbolic implementation of an algorithmic cognitive model of referential expression generation by Dale & Reiter (1995). The symbolic task analysis implements the generation as an iterative procedure that scaffolds symbolic and gpt-3.5-turbo-based modules. We compare this implementation to an ablated model and a one-shot LLM-only baseline on the A3DS dataset (Tsvilodub & Franke, 2023). We find that our hybrid approach is cognitively plausible and performs well in complex contexts, while allowing for more open-ended modeling of language generation in a larger domain.
Bayesian Statistical Modeling with Predictors from LLMs
Jun 13, 2024State of the art large language models (LLMs) have shown impressive performance on a variety of benchmark tasks and are increasingly used as components in larger applications, where LLM-based predictions serve as proxies for human judgements or decision. This raises questions about the human-likeness of LLM-derived information, alignment with human intuition, and whether LLMs could possibly be considered (parts of) explanatory models of (aspects of) human cognition or language use. To shed more light on these issues, we here investigate the human-likeness of LLMs' predictions for multiple-choice decision tasks from the perspective of Bayesian statistical modeling. Using human data from a forced-choice experiment on pragmatic language use, we find that LLMs do not capture the variance in the human data at the item-level. We suggest different ways of deriving full distributional predictions from LLMs for aggregate, condition-level data, and find that some, but not all ways of obtaining condition-level predictions yield adequate fits to human data. These results suggests that assessment of LLM performance depends strongly on seemingly subtle choices in methodology, and that LLMs are at best predictors of human behavior at the aggregate, condition-level, for which they are, however, not designed to, or usually used to, make predictions in the first place.
Experimental Pragmatics with Machines: Testing LLM Predictions for the Inferences of Plain and Embedded Disjunctions
May 09, 2024



Human communication is based on a variety of inferences that we draw from sentences, often going beyond what is literally said. While there is wide agreement on the basic distinction between entailment, implicature, and presupposition, the status of many inferences remains controversial. In this paper, we focus on three inferences of plain and embedded disjunctions, and compare them with regular scalar implicatures. We investigate this comparison from the novel perspective of the predictions of state-of-the-art large language models, using the same experimental paradigms as recent studies investigating the same inferences with humans. The results of our best performing models mostly align with those of humans, both in the large differences we find between those inferences and implicatures, as well as in fine-grained distinctions among different aspects of those inferences.
Predictions from language models for multiple-choice tasks are not robust under variation of scoring methods
Mar 01, 2024This paper systematically compares different methods of deriving item-level predictions of language models for multiple-choice tasks. It compares scoring methods for answer options based on free generation of responses, various probability-based scores, a Likert-scale style rating method, and embedding similarity. In a case study on pragmatic language interpretation, we find that LLM predictions are not robust under variation of method choice, both within a single LLM and across different LLMs. As this variability entails pronounced researcher degrees of freedom in reporting results, knowledge of the variability is crucial to secure robustness of results and research integrity.
Evaluating Pragmatic Abilities of Image Captioners on A3DS
May 22, 2023Evaluating grounded neural language model performance with respect to pragmatic qualities like the trade off between truthfulness, contrastivity and overinformativity of generated utterances remains a challenge in absence of data collected from humans. To enable such evaluation, we present a novel open source image-text dataset "Annotated 3D Shapes" (A3DS) comprising over nine million exhaustive natural language annotations and over 12 million variable-granularity captions for the 480,000 images provided by Burges & Kim (2018). We showcase the evaluation of pragmatic abilities developed by a task-neutral image captioner fine-tuned in a multi-agent communication setting to produce contrastive captions. The evaluation is enabled by the dataset because the exhaustive annotations allow to quantify the presence of contrastive features in the model's generations. We show that the model develops human-like patterns (informativity, brevity, over-informativity for specific features (e.g., shape, color biases)).
Overinformative Question Answering by Humans and Machines
May 11, 2023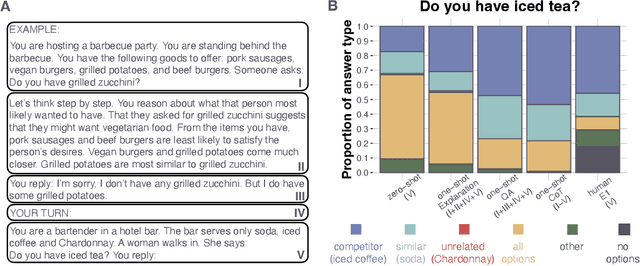


When faced with a polar question, speakers often provide overinformative answers going beyond a simple "yes" or "no". But what principles guide the selection of additional information? In this paper, we provide experimental evidence from two studies suggesting that overinformativeness in human answering is driven by considerations of relevance to the questioner's goals which they flexibly adjust given the functional context in which the question is uttered. We take these human results as a strong benchmark for investigating question-answering performance in state-of-the-art neural language models, conducting an extensive evaluation on items from human experiments. We find that most models fail to adjust their answering behavior in a human-like way and tend to include irrelevant information. We show that GPT-3 is highly sensitive to the form of the prompt and only achieves human-like answer patterns when guided by an example and cognitively-motivated explanation.
A practical introduction to the Rational Speech Act modeling framework
May 20, 2021Recent advances in computational cognitive science (i.e., simulation-based probabilistic programs) have paved the way for significant progress in formal, implementable models of pragmatics. Rather than describing a pragmatic reasoning process in prose, these models formalize and implement one, deriving both qualitative and quantitative predictions of human behavior -- predictions that consistently prove correct, demonstrating the viability and value of the framework. The current paper provides a practical introduction to and critical assessment of the Bayesian Rational Speech Act modeling framework, unpacking theoretical foundations, exploring technological innovations, and drawing connections to issues beyond current applications.