 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVidmento: Creating Video Stories Through Context-Aware Expansion With Generative Video
Jan 29, 2026Video storytelling is often constrained by available material, limiting creative expression and leaving undesired narrative gaps. Generative video offers a new way to address these limitations by augmenting captured media with tailored visuals. To explore this potential, we interviewed eight video creators to identify opportunities and challenges in integrating generative video into their workflows. Building on these insights and established filmmaking principles, we developed Vidmento, a tool for authoring hybrid video stories that combine captured and generated media through context-aware expansion. Vidmento surfaces opportunities for story development, generates clips that blend stylistically and narratively with surrounding media, and provides controls for refinement. In a study with 12 creators, Vidmento supported narrative development and exploration by systematically expanding initial materials with generative media, enabling expressive video storytelling aligned with creative intent. We highlight how creators bridge story gaps with generative content and where they find this blending capability most valuable.
Exploring Empty Spaces: Human-in-the-Loop Data Augmentation
Oct 01, 2024


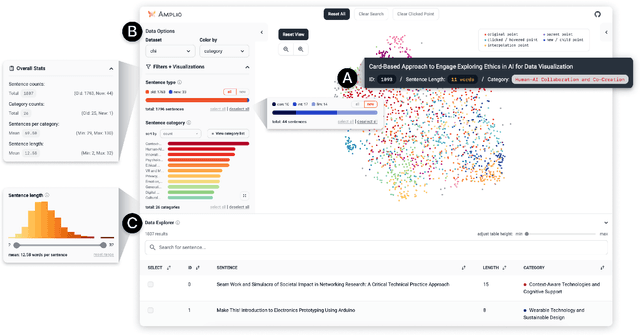
Data augmentation is crucial to make machine learning models more robust and safe. However, augmenting data can be challenging as it requires generating diverse data points to rigorously evaluate model behavior on edge cases and mitigate potential harms. Creating high-quality augmentations that cover these "unknown unknowns" is a time- and creativity-intensive task. In this work, we introduce Amplio, an interactive tool to help practitioners navigate "unknown unknowns" in unstructured text datasets and improve data diversity by systematically identifying empty data spaces to explore. Amplio includes three human-in-the-loop data augmentation techniques: Augment With Concepts, Augment by Interpolation, and Augment with Large Language Model. In a user study with 18 professional red teamers, we demonstrate the utility of our augmentation methods in helping generate high-quality, diverse, and relevant model safety prompts. We find that Amplio enabled red teamers to augment data quickly and creatively, highlighting the transformative potential of interactive augmentation workflows.
Designing a Dashboard for Transparency and Control of Conversational AI
Jun 12, 2024



Conversational LLMs function as black box systems, leaving users guessing about why they see the output they do. This lack of transparency is potentially problematic, especially given concerns around bias and truthfulness. To address this issue, we present an end-to-end prototype-connecting interpretability techniques with user experience design-that seeks to make chatbots more transparent. We begin by showing evidence that a prominent open-source LLM has a "user model": examining the internal state of the system, we can extract data related to a user's age, gender, educational level, and socioeconomic status. Next, we describe the design of a dashboard that accompanies the chatbot interface, displaying this user model in real time. The dashboard can also be used to control the user model and the system's behavior. Finally, we discuss a study in which users conversed with the instrumented system. Our results suggest that users appreciate seeing internal states, which helped them expose biased behavior and increased their sense of control. Participants also made valuable suggestions that point to future directions for both design and machine learning research. The project page and video demo of our TalkTuner system are available at https://bit.ly/talktuner-project-page
GhostWriter: Augmenting Collaborative Human-AI Writing Experiences Through Personalization and Agency
Feb 13, 2024

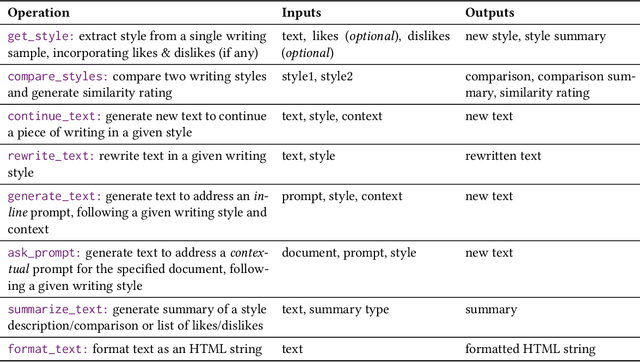
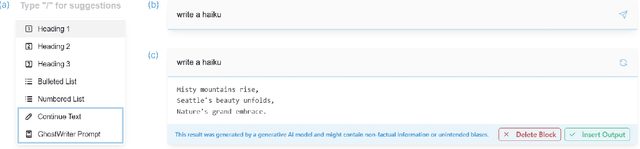
Large language models (LLMs) are becoming more prevalent and have found a ubiquitous use in providing different forms of writing assistance. However, LLM-powered writing systems can frustrate users due to their limited personalization and control, which can be exacerbated when users lack experience with prompt engineering. We see design as one way to address these challenges and introduce GhostWriter, an AI-enhanced writing design probe where users can exercise enhanced agency and personalization. GhostWriter leverages LLMs to learn the user's intended writing style implicitly as they write, while allowing explicit teaching moments through manual style edits and annotations. We study 18 participants who use GhostWriter on two different writing tasks, observing that it helps users craft personalized text generations and empowers them by providing multiple ways to control the system's writing style. From this study, we present insights regarding people's relationship with AI-assisted writing and offer design recommendations for future work.
AttentionViz: A Global View of Transformer Attention
May 04, 2023



Transformer models are revolutionizing machine learning, but their inner workings remain mysterious. In this work, we present a new visualization technique designed to help researchers understand the self-attention mechanism in transformers that allows these models to learn rich, contextual relationships between elements of a sequence. The main idea behind our method is to visualize a joint embedding of the query and key vectors used by transformer models to compute attention. Unlike previous attention visualization techniques, our approach enables the analysis of global patterns across multiple input sequences. We create an interactive visualization tool, AttentionViz, based on these joint query-key embeddings, and use it to study attention mechanisms in both language and vision transformers. We demonstrate the utility of our approach in improving model understanding and offering new insights about query-key interactions through several application scenarios and expert feedback.
Envisioning the Next-Gen Document Reader
Feb 15, 2023People read digital documents on a daily basis to share, exchange, and understand information in electronic settings. However, current document readers create a static, isolated reading experience, which does not support users' goals of gaining more knowledge and performing additional tasks through document interaction. In this work, we present our vision for the next-gen document reader that strives to enhance user understanding and create a more connected, trustworthy information experience. We describe 18 NLP-powered features to add to existing document readers and propose a novel plug-in marketplace that allows users to further customize their reading experience, as demonstrated through 3 exploratory UI prototypes available at https://github.com/catherinesyeh/nextgen-prototypes
Self-critiquing models for assisting human evaluators
Jun 14, 2022

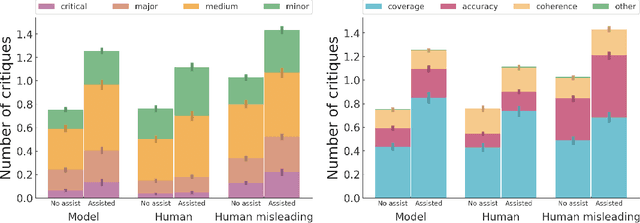
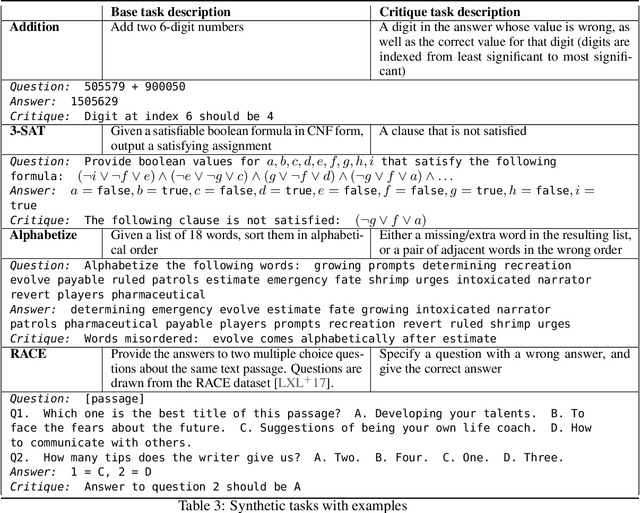
We fine-tune large language models to write natural language critiques (natural language critical comments) using behavioral cloning. On a topic-based summarization task, critiques written by our models help humans find flaws in summaries that they would have otherwise missed. Our models help find naturally occurring flaws in both model and human written summaries, and intentional flaws in summaries written by humans to be deliberately misleading. We study scaling properties of critiquing with both topic-based summarization and synthetic tasks. Larger models write more helpful critiques, and on most tasks, are better at self-critiquing, despite having harder-to-critique outputs. Larger models can also integrate their own self-critiques as feedback, refining their own summaries into better ones. Finally, we motivate and introduce a framework for comparing critiquing ability to generation and discrimination ability. Our measurements suggest that even large models may still have relevant knowledge they cannot or do not articulate as critiques. These results are a proof of concept for using AI-assisted human feedback to scale the supervision of machine learning systems to tasks that are difficult for humans to evaluate directly. We release our training datasets, as well as samples from our critique assistance experiments.