 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstructive Circuit Amplification: Improving Math Reasoning in LLMs via Targeted Sub-Network Updates
Dec 18, 2025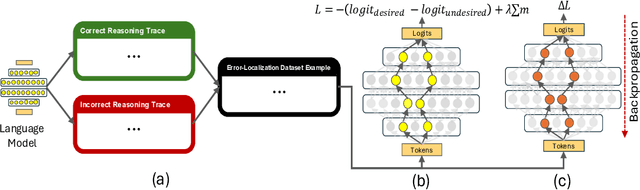
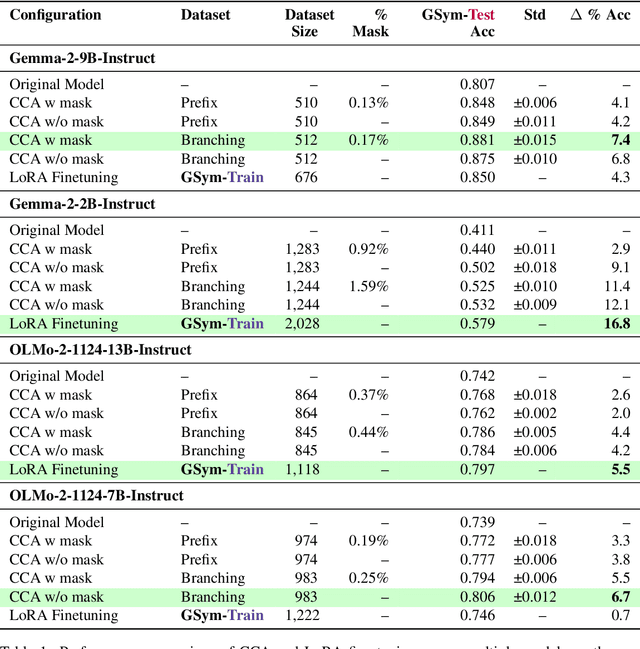

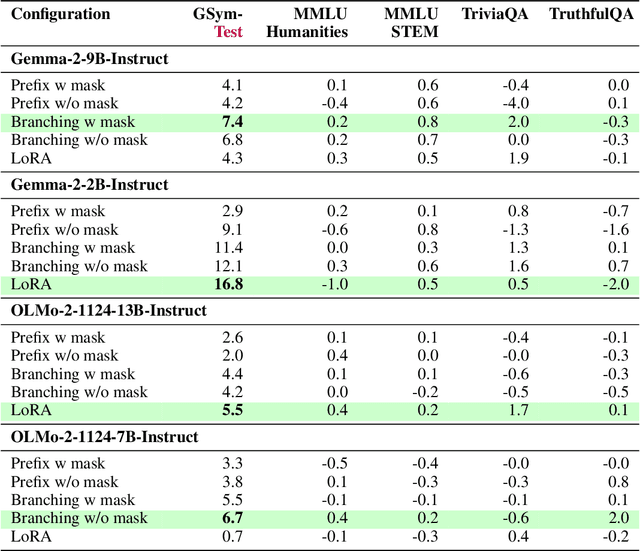
Prior studies investigating the internal workings of LLMs have uncovered sparse subnetworks, often referred to as circuits, that are responsible for performing specific tasks. Additionally, it has been shown that model performance improvement through fine-tuning often results from the strengthening of existing circuits in the model. Taken together, these findings suggest the possibility of intervening directly on such circuits to make precise, task-targeted updates. Motivated by these findings, we propose a novel method called Constructive Circuit Amplification which identifies pivotal tokens from model reasoning traces as well as model components responsible for the desired task, and updates only those components. Applied to mathematical reasoning, it improves accuracy by up to +11.4% across multiple models while modifying as little as 1.59% of model components, with minimal impact on other abilities as measured by MMLU, TriviaQA, and TruthfulQA. These results demonstrate that targeted capabilities can be reliably enhanced by selectively updating a sparse set of model components.
EncQA: Benchmarking Vision-Language Models on Visual Encodings for Charts
Aug 06, 2025Multimodal vision-language models (VLMs) continue to achieve ever-improving scores on chart understanding benchmarks. Yet, we find that this progress does not fully capture the breadth of visual reasoning capabilities essential for interpreting charts. We introduce EncQA, a novel benchmark informed by the visualization literature, designed to provide systematic coverage of visual encodings and analytic tasks that are crucial for chart understanding. EncQA provides 2,076 synthetic question-answer pairs, enabling balanced coverage of six visual encoding channels (position, length, area, color quantitative, color nominal, and shape) and eight tasks (find extrema, retrieve value, find anomaly, filter values, compute derived value exact, compute derived value relative, correlate values, and correlate values relative). Our evaluation of 9 state-of-the-art VLMs reveals that performance varies significantly across encodings within the same task, as well as across tasks. Contrary to expectations, we observe that performance does not improve with model size for many task-encoding pairs. Our results suggest that advancing chart understanding requires targeted strategies addressing specific visual reasoning gaps, rather than solely scaling up model or dataset size.
Exploring Empty Spaces: Human-in-the-Loop Data Augmentation
Oct 01, 2024


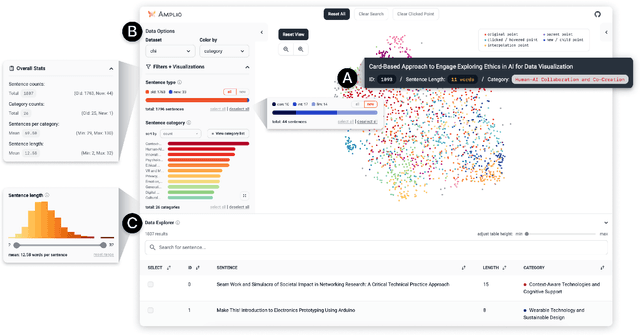
Data augmentation is crucial to make machine learning models more robust and safe. However, augmenting data can be challenging as it requires generating diverse data points to rigorously evaluate model behavior on edge cases and mitigate potential harms. Creating high-quality augmentations that cover these "unknown unknowns" is a time- and creativity-intensive task. In this work, we introduce Amplio, an interactive tool to help practitioners navigate "unknown unknowns" in unstructured text datasets and improve data diversity by systematically identifying empty data spaces to explore. Amplio includes three human-in-the-loop data augmentation techniques: Augment With Concepts, Augment by Interpolation, and Augment with Large Language Model. In a user study with 18 professional red teamers, we demonstrate the utility of our augmentation methods in helping generate high-quality, diverse, and relevant model safety prompts. We find that Amplio enabled red teamers to augment data quickly and creatively, highlighting the transformative potential of interactive augmentation workflows.
Compress and Compare: Interactively Evaluating Efficiency and Behavior Across ML Model Compression Experiments
Aug 06, 2024To deploy machine learning models on-device, practitioners use compression algorithms to shrink and speed up models while maintaining their high-quality output. A critical aspect of compression in practice is model comparison, including tracking many compression experiments, identifying subtle changes in model behavior, and negotiating complex accuracy-efficiency trade-offs. However, existing compression tools poorly support comparison, leading to tedious and, sometimes, incomplete analyses spread across disjoint tools. To support real-world comparative workflows, we develop an interactive visual system called Compress and Compare. Within a single interface, Compress and Compare surfaces promising compression strategies by visualizing provenance relationships between compressed models and reveals compression-induced behavior changes by comparing models' predictions, weights, and activations. We demonstrate how Compress and Compare supports common compression analysis tasks through two case studies, debugging failed compression on generative language models and identifying compression artifacts in image classification models. We further evaluate Compress and Compare in a user study with eight compression experts, illustrating its potential to provide structure to compression workflows, help practitioners build intuition about compression, and encourage thorough analysis of compression's effect on model behavior. Through these evaluations, we identify compression-specific challenges that future visual analytics tools should consider and Compress and Compare visualizations that may generalize to broader model comparison tasks.
Evaluating Long Range Dependency Handling in Code Generation Models using Multi-Step Key Retrieval
Jul 23, 2024As language models support larger and larger context sizes, evaluating their ability to make effective use of that context becomes increasingly important. We analyze the ability of several code generation models to handle long range dependencies using a suite of multi-step key retrieval tasks in context windows up to 8k tokens in length. The tasks progressively increase in difficulty and allow more nuanced evaluation of model capabilities than tests like the popular needle-in-the-haystack test. We find that performance degrades significantly (up to 2x) when a function references another function that is defined later in the prompt. We also observe that models that use sliding window attention mechanisms have difficulty handling references further than the size of a single window. We perform simple prompt modifications using call graph information to improve multi-step retrieval performance up to 3x. Our analysis highlights different facets of long-context performance and is suggestive of prompt construction strategies for code completion tools
One Wide Feedforward is All You Need
Sep 04, 2023



The Transformer architecture has two main non-embedding components: Attention and the Feed Forward Network (FFN). Attention captures interdependencies between words regardless of their position, while the FFN non-linearly transforms each input token independently. In this work we explore the role of the FFN, and find that despite taking up a significant fraction of the model's parameters, it is highly redundant. Concretely, we are able to substantially reduce the number of parameters with only a modest drop in accuracy by removing the FFN on the decoder layers and sharing a single FFN across the encoder. Finally we scale this architecture back to its original size by increasing the hidden dimension of the shared FFN, achieving substantial gains in both accuracy and latency with respect to the original Transformer Big.
Beyond Rewards: a Hierarchical Perspective on Offline Multiagent Behavioral Analysis
Jun 17, 2022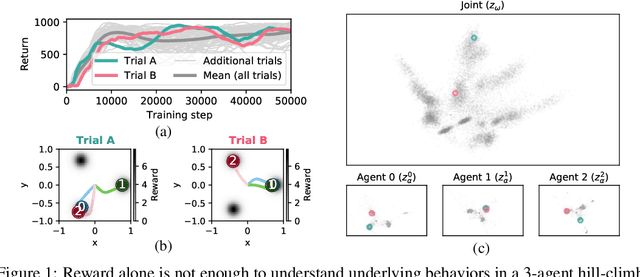

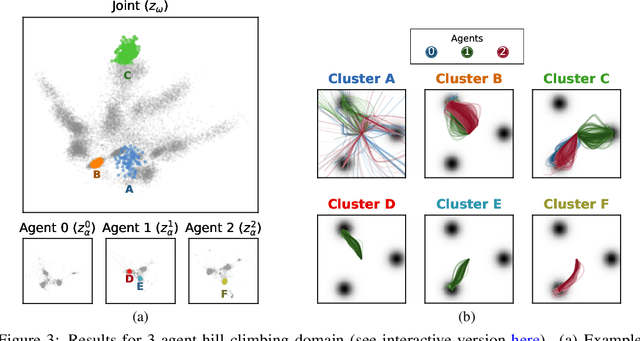

Each year, expert-level performance is attained in increasingly-complex multiagent domains, notable examples including Go, Poker, and StarCraft II. This rapid progression is accompanied by a commensurate need to better understand how such agents attain this performance, to enable their safe deployment, identify limitations, and reveal potential means of improving them. In this paper we take a step back from performance-focused multiagent learning, and instead turn our attention towards agent behavior analysis. We introduce a model-agnostic method for discovery of behavior clusters in multiagent domains, using variational inference to learn a hierarchy of behaviors at the joint and local agent levels. Our framework makes no assumption about agents' underlying learning algorithms, does not require access to their latent states or models, and can be trained using entirely offline observational data. We illustrate the effectiveness of our method for enabling the coupled understanding of behaviors at the joint and local agent level, detection of behavior changepoints throughout training, discovery of core behavioral concepts (e.g., those that facilitate higher returns), and demonstrate the approach's scalability to a high-dimensional multiagent MuJoCo control domain.
TensorFlow.js: Machine Learning for the Web and Beyond
Jan 16, 2019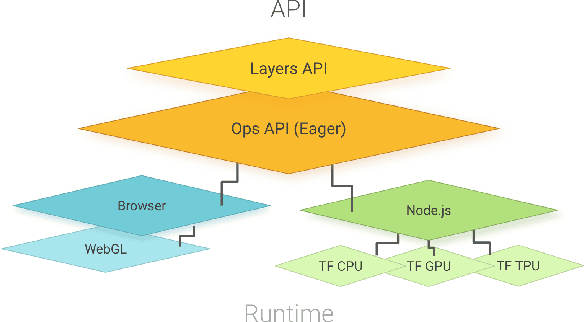
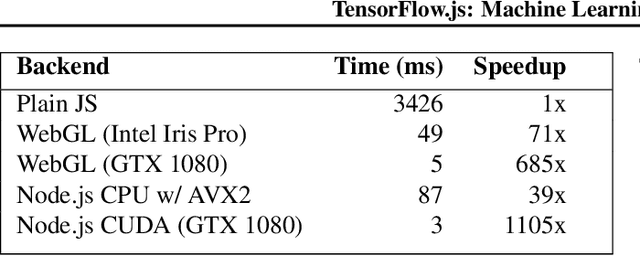


TensorFlow.js is a library for building and executing machine learning algorithms in JavaScript. TensorFlow.js models run in a web browser and in the Node.js environment. The library is part of the TensorFlow ecosystem, providing a set of APIs that are compatible with those in Python, allowing models to be ported between the Python and JavaScript ecosystems. TensorFlow.js has empowered a new set of developers from the extensive JavaScript community to build and deploy machine learning models and enabled new classes of on-device computation. This paper describes the design, API, and implementation of TensorFlow.js, and highlights some of the impactful use cases.