 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Wide Feedforward is All You Need
Sep 04, 2023



The Transformer architecture has two main non-embedding components: Attention and the Feed Forward Network (FFN). Attention captures interdependencies between words regardless of their position, while the FFN non-linearly transforms each input token independently. In this work we explore the role of the FFN, and find that despite taking up a significant fraction of the model's parameters, it is highly redundant. Concretely, we are able to substantially reduce the number of parameters with only a modest drop in accuracy by removing the FFN on the decoder layers and sharing a single FFN across the encoder. Finally we scale this architecture back to its original size by increasing the hidden dimension of the shared FFN, achieving substantial gains in both accuracy and latency with respect to the original Transformer Big.
Unbabel's Participation in the WMT19 Translation Quality Estimation Shared Task
Jul 24, 2019
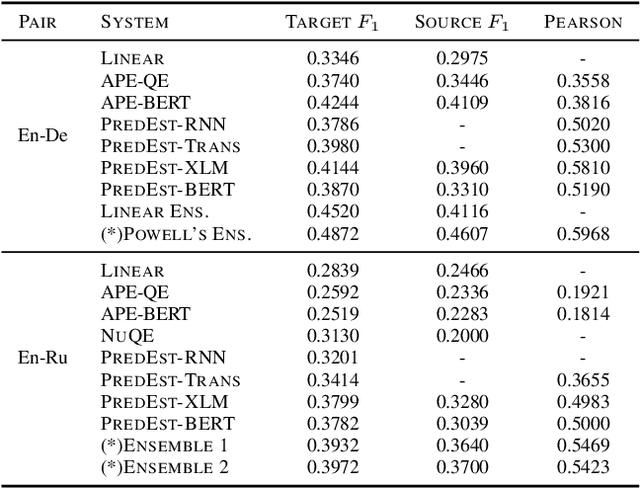
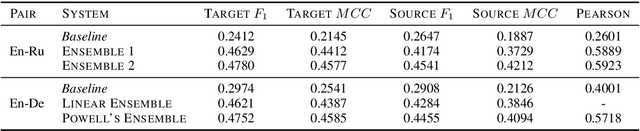

We present the contribution of the Unbabel team to the WMT 2019 Shared Task on Quality Estimation. We participated on the word, sentence, and document-level tracks, encompassing 3 language pairs: nglish-German, English-Russian, and English-French. Our submissions build upon the recent OpenKiwi framework: we combine linear, neural, and predictor-estimator systems with new transfer learning approaches using BERT and XLM pre-trained models. We compare systems individually and propose new ensemble techniques for word and sentence-level predictions. We also propose a simple technique for converting word labels into document-level predictions. Overall, our submitted systems achieve the best results on all tracks and language pairs by a considerable margin.
Unbabel's Submission to the WMT2019 APE Shared Task: BERT-based Encoder-Decoder for Automatic Post-Editing
May 30, 2019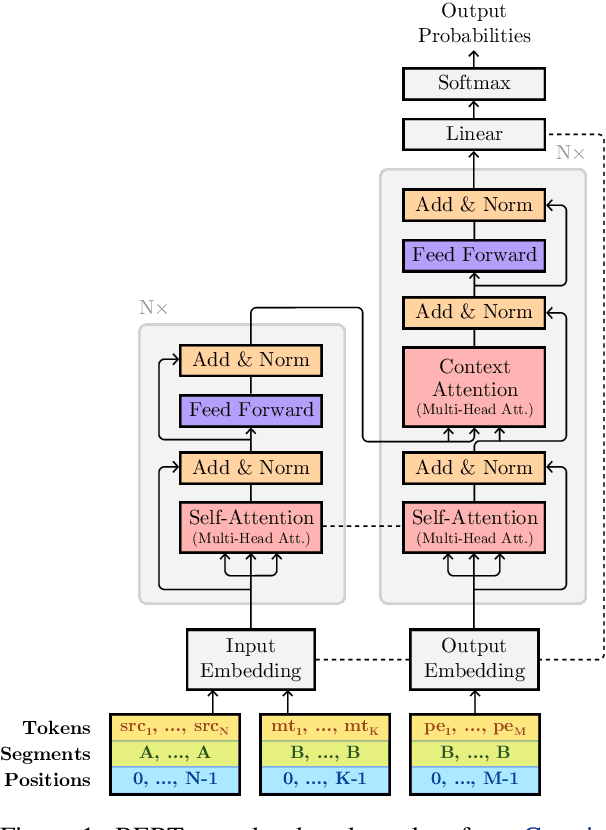
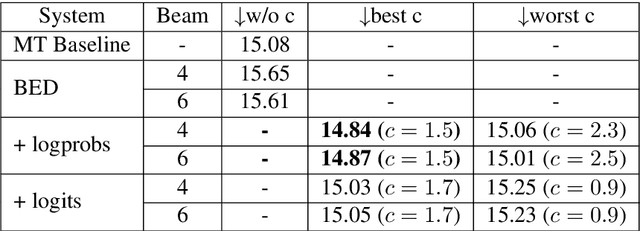
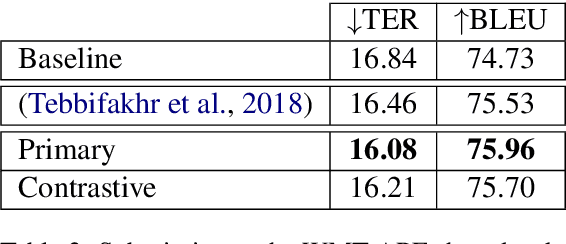
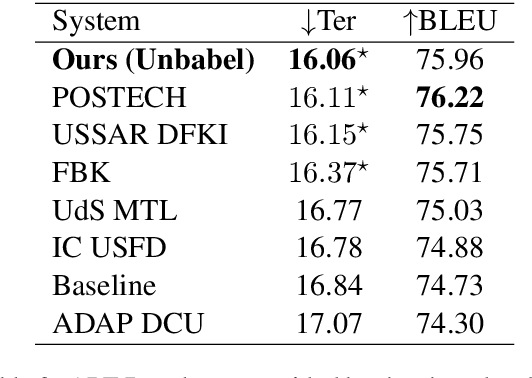
This paper describes Unbabel's submission to the WMT2019 APE Shared Task for the English-German language pair. Following the recent rise of large, powerful, pre-trained models, we adapt the BERT pretrained model to perform Automatic Post-Editing in an encoder-decoder framework. Analogously to dual-encoder architectures we develop a BERT-based encoder-decoder (BED) model in which a single pretrained BERT encoder receives both the source src and machine translation tgt strings. Furthermore, we explore a conservativeness factor to constrain the APE system to perform fewer edits. As the official results show, when trained on a weighted combination of in-domain and artificial training data, our BED system with the conservativeness penalty improves significantly the translations of a strong Neural Machine Translation system by $-0.78$ and $+1.23$ in terms of TER and BLEU, respectively.