 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable ICD Coding via Entity Linking
Mar 26, 2025Clinical coding is a critical task in healthcare, although traditional methods for automating clinical coding may not provide sufficient explicit evidence for coders in production environments. This evidence is crucial, as medical coders have to make sure there exists at least one explicit passage in the input health record that justifies the attribution of a code. We therefore propose to reframe the task as an entity linking problem, in which each document is annotated with its set of codes and respective textual evidence, enabling better human-machine collaboration. By leveraging parameter-efficient fine-tuning of Large Language Models (LLMs), together with constrained decoding, we introduce three approaches to solve this problem that prove effective at disambiguating clinical mentions and that perform well in few-shot scenarios.
Multi-Target Cross-Lingual Summarization: a novel task and a language-neutral approach
Oct 01, 2024
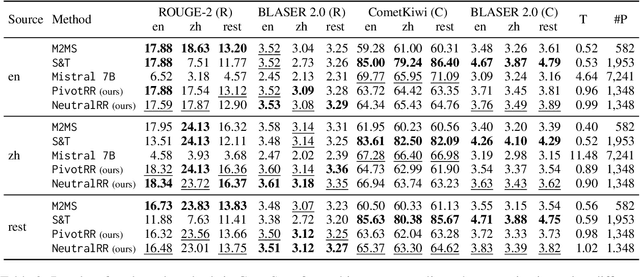
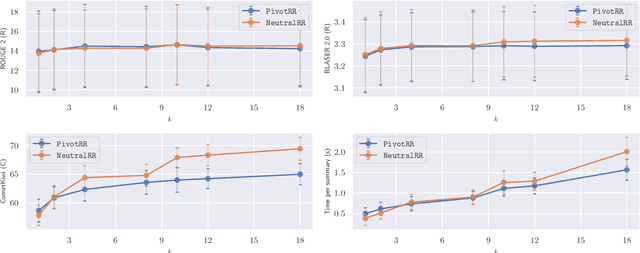
Cross-lingual summarization aims to bridge language barriers by summarizing documents in different languages. However, ensuring semantic coherence across languages is an overlooked challenge and can be critical in several contexts. To fill this gap, we introduce multi-target cross-lingual summarization as the task of summarizing a document into multiple target languages while ensuring that the produced summaries are semantically similar. We propose a principled re-ranking approach to this problem and a multi-criteria evaluation protocol to assess semantic coherence across target languages, marking a first step that will hopefully stimulate further research on this problem.
Efficient Marginalization of Discrete and Structured Latent Variables via Sparsity
Jul 03, 2020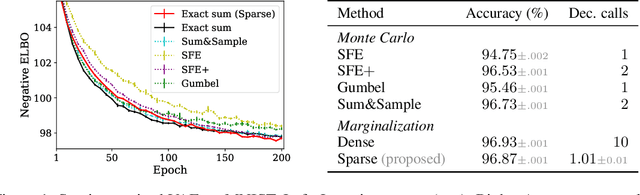
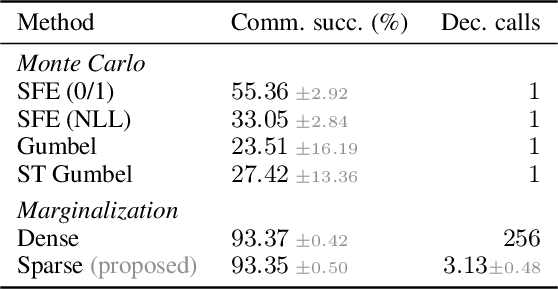
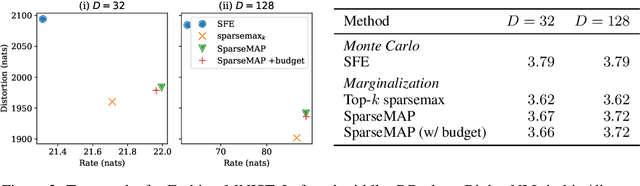

Training neural network models with discrete (categorical or structured) latent variables can be computationally challenging, due to the need for marginalization over large or combinatorial sets. To circumvent this issue, one typically resorts to sampling-based approximations of the true marginal, requiring noisy gradient estimators (e.g., score function estimator) or continuous relaxations with lower-variance reparameterized gradients (e.g., Gumbel-Softmax). In this paper, we propose a new training strategy which replaces these estimators by an exact yet efficient marginalization. To achieve this, we parameterize discrete distributions over latent assignments using differentiable sparse mappings: sparsemax and its structured counterparts. In effect, the support of these distributions is greatly reduced, which enables efficient marginalization. We report successful results in three tasks covering a range of latent variable modeling applications: a semisupervised deep generative model, a latent communication game, and a generative model with a bit vector latent representation. In all cases, we obtain good performance while still achieving the practicality of sampling-based approximations.
Adaptively Sparse Transformers
Sep 06, 2019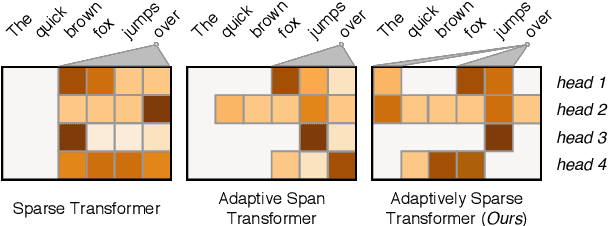

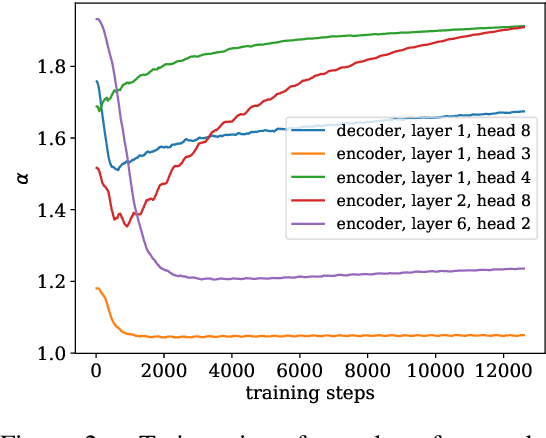
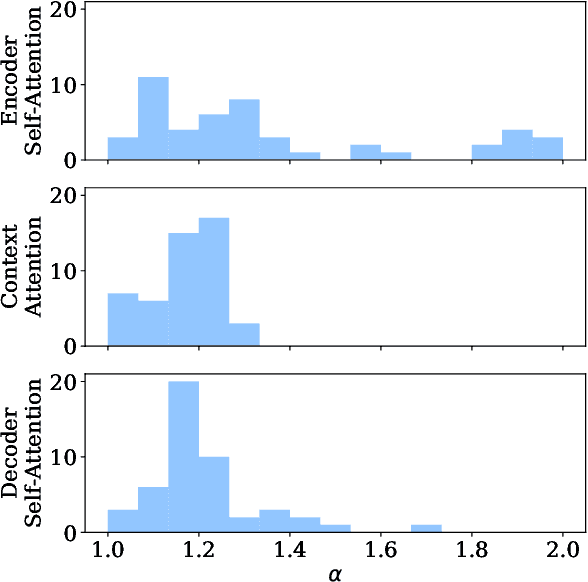
Attention mechanisms have become ubiquitous in NLP. Recent architectures, notably the Transformer, learn powerful context-aware word representations through layered, multi-headed attention. The multiple heads learn diverse types of word relationships. However, with standard softmax attention, all attention heads are dense, assigning a non-zero weight to all context words. In this work, we introduce the adaptively sparse Transformer, wherein attention heads have flexible, context-dependent sparsity patterns. This sparsity is accomplished by replacing softmax with $\alpha$-entmax: a differentiable generalization of softmax that allows low-scoring words to receive precisely zero weight. Moreover, we derive a method to automatically learn the $\alpha$ parameter -- which controls the shape and sparsity of $\alpha$-entmax -- allowing attention heads to choose between focused or spread-out behavior. Our adaptively sparse Transformer improves interpretability and head diversity when compared to softmax Transformers on machine translation datasets. Findings of the quantitative and qualitative analysis of our approach include that heads in different layers learn different sparsity preferences and tend to be more diverse in their attention distributions than softmax Transformers. Furthermore, at no cost in accuracy, sparsity in attention heads helps to uncover different head specializations.
A Simple and Effective Approach to Automatic Post-Editing with Transfer Learning
Jun 14, 2019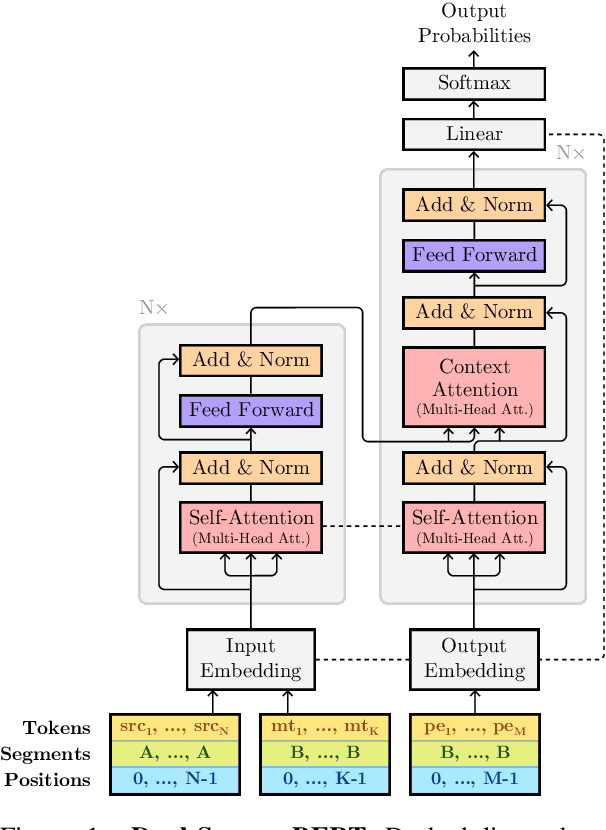

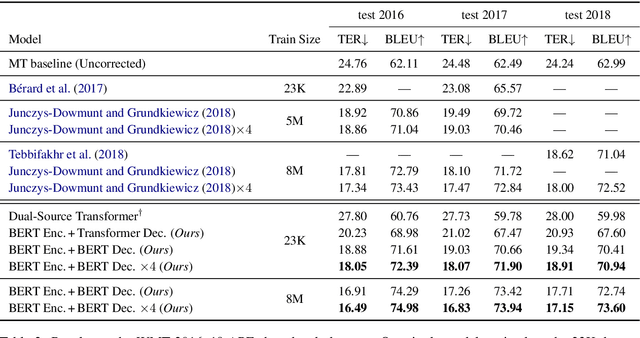
Automatic post-editing (APE) seeks to automatically refine the output of a black-box machine translation (MT) system through human post-edits. APE systems are usually trained by complementing human post-edited data with large, artificial data generated through back-translations, a time-consuming process often no easier than training an MT system from scratch. In this paper, we propose an alternative where we fine-tune pre-trained BERT models on both the encoder and decoder of an APE system, exploring several parameter sharing strategies. By only training on a dataset of 23K sentences for 3 hours on a single GPU, we obtain results that are competitive with systems that were trained on 5M artificial sentences. When we add this artificial data, our method obtains state-of-the-art results.
Unbabel's Submission to the WMT2019 APE Shared Task: BERT-based Encoder-Decoder for Automatic Post-Editing
May 30, 2019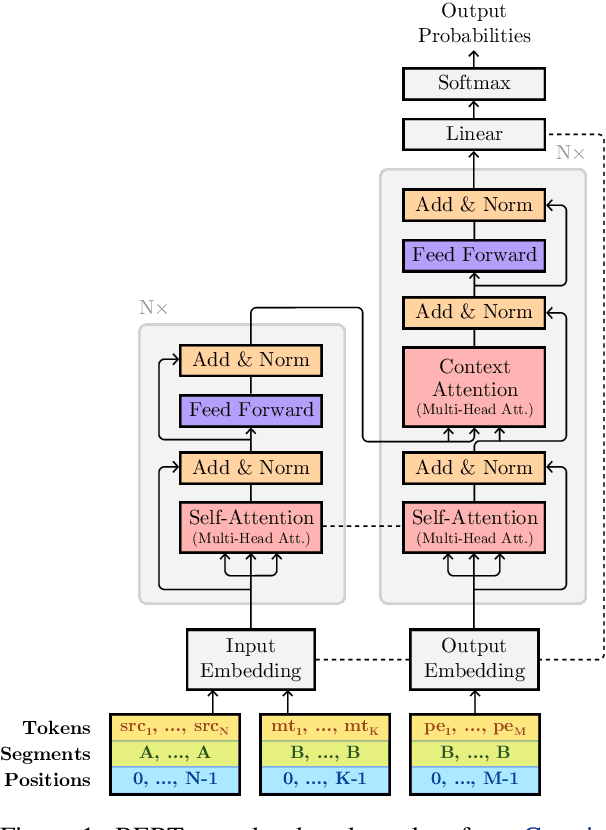
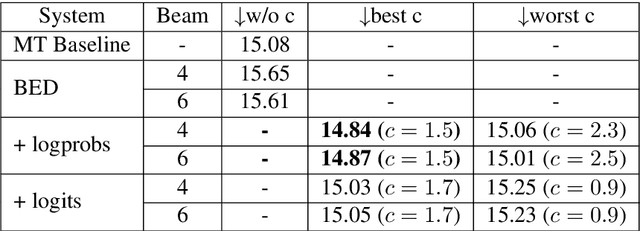
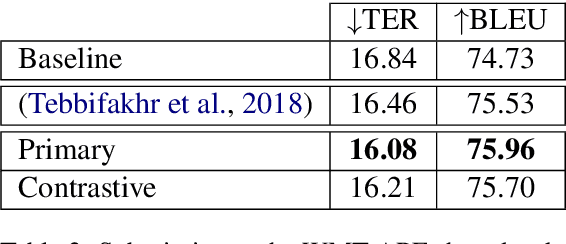
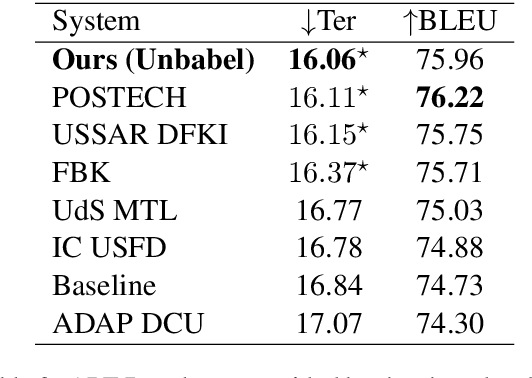
This paper describes Unbabel's submission to the WMT2019 APE Shared Task for the English-German language pair. Following the recent rise of large, powerful, pre-trained models, we adapt the BERT pretrained model to perform Automatic Post-Editing in an encoder-decoder framework. Analogously to dual-encoder architectures we develop a BERT-based encoder-decoder (BED) model in which a single pretrained BERT encoder receives both the source src and machine translation tgt strings. Furthermore, we explore a conservativeness factor to constrain the APE system to perform fewer edits. As the official results show, when trained on a weighted combination of in-domain and artificial training data, our BED system with the conservativeness penalty improves significantly the translations of a strong Neural Machine Translation system by $-0.78$ and $+1.23$ in terms of TER and BLEU, respectively.