 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedPath: Multi-Domain Cross-Vocabulary Hierarchical Paths for Biomedical Entity Linking
Nov 14, 2025Progress in biomedical Named Entity Recognition (NER) and Entity Linking (EL) is currently hindered by a fragmented data landscape, a lack of resources for building explainable models, and the limitations of semantically-blind evaluation metrics. To address these challenges, we present MedPath, a large-scale and multi-domain biomedical EL dataset that builds upon nine existing expert-annotated EL datasets. In MedPath, all entities are 1) normalized using the latest version of the Unified Medical Language System (UMLS), 2) augmented with mappings to 62 other biomedical vocabularies and, crucially, 3) enriched with full ontological paths -- i.e., from general to specific -- in up to 11 biomedical vocabularies. MedPath directly enables new research frontiers in biomedical NLP, facilitating training and evaluation of semantic-rich and interpretable EL systems, and the development of the next generation of interoperable and explainable clinical NLP models.
Teaching Language Models to Faithfully Express their Uncertainty
Oct 14, 2025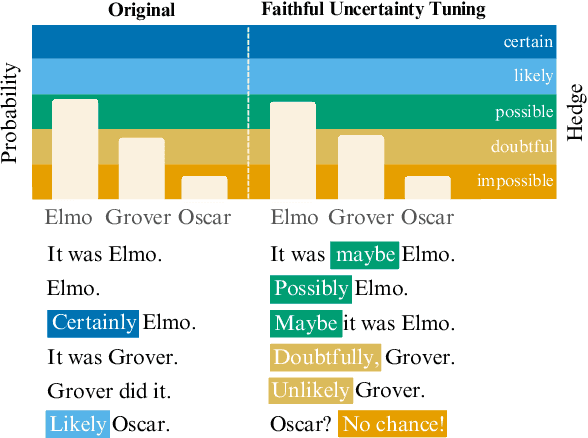
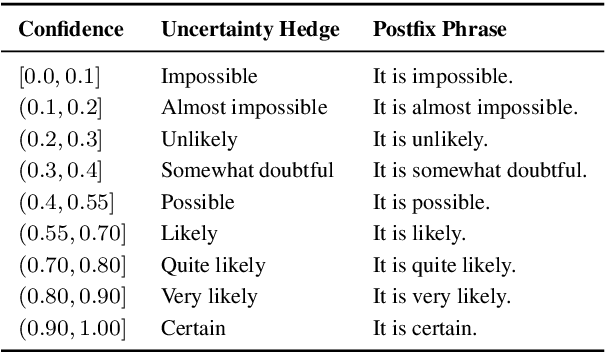
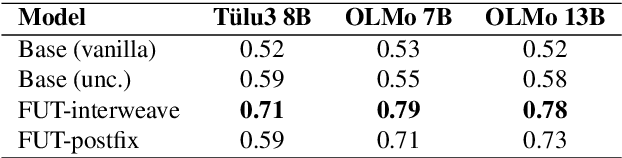
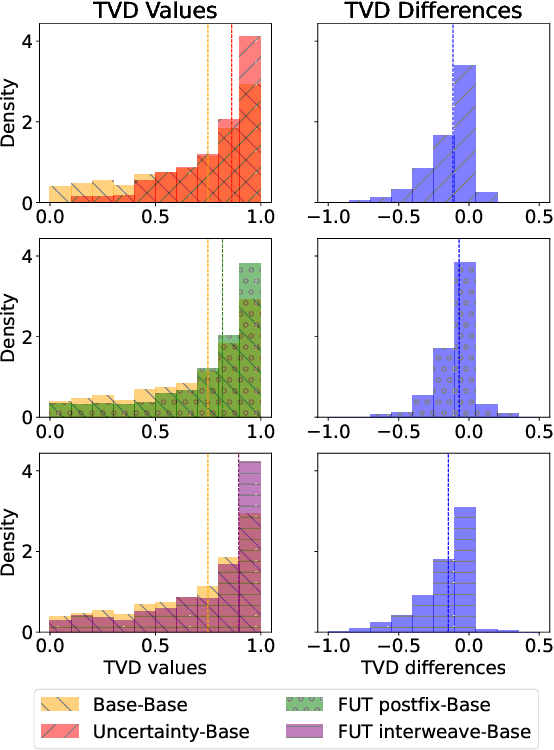
Large language models (LLMs) often miscommunicate their uncertainty: repeated queries can produce divergent answers, yet generated responses are typically unhedged or hedged in ways that do not reflect this variability. This conveys unfaithful information about the uncertain state of the LLMs' knowledge, creating a faithfulness gap that affects even strong LLMs. We introduce Faithful Uncertainty Tuning (FUT): a fine-tuning approach that teaches instruction-tuned LLMs to express uncertainty faithfully without altering their underlying answer distribution. We construct training data by augmenting model samples with uncertainty hedges (i.e. verbal cues such as 'possibly' or 'likely') aligned with sample consistency, requiring no supervision beyond the model and a set of prompts. We evaluate FUT on open-domain question answering (QA) across multiple models and datasets. Our results show that FUT substantially reduces the faithfulness gap, while preserving QA accuracy and introducing minimal semantic distribution shift. Further analyses demonstrate robustness across decoding strategies, choice of hedgers, and other forms of uncertainty expression (i.e. numerical). These findings establish FUT as a simple and effective way to teach LLMs to communicate uncertainty faithfully.
Truthful or Fabricated? Using Causal Attribution to Mitigate Reward Hacking in Explanations
Apr 07, 2025



Chain-of-thought explanations are widely used to inspect the decision process of large language models (LLMs) and to evaluate the trustworthiness of model outputs, making them important for effective collaboration between LLMs and humans. We demonstrate that preference optimization - a key step in the alignment phase - can inadvertently reduce the faithfulness of these explanations. This occurs because the reward model (RM), which guides alignment, is tasked with optimizing both the expected quality of the response and the appropriateness of the explanations (e.g., minimizing bias or adhering to safety standards), creating potential conflicts. The RM lacks a mechanism to assess the consistency between the model's internal decision process and the generated explanation. Consequently, the LLM may engage in "reward hacking" by producing a final response that scores highly while giving an explanation tailored to maximize reward rather than accurately reflecting its reasoning. To address this issue, we propose enriching the RM's input with a causal attribution of the prediction, allowing the RM to detect discrepancies between the generated self-explanation and the model's decision process. In controlled settings, we show that this approach reduces the tendency of the LLM to generate misleading explanations.
Variability Need Not Imply Error: The Case of Adequate but Semantically Distinct Responses
Dec 20, 2024With the broader use of language models (LMs) comes the need to estimate their ability to respond reliably to prompts (e.g., are generated responses likely to be correct?). Uncertainty quantification tools (notions of confidence and entropy, i.a.) can be used to that end (e.g., to reject a response when the model is `uncertain'). For example, Kuhn et al. (semantic entropy; 2022b) regard semantic variation amongst sampled responses as evidence that the model `struggles' with the prompt and that the LM is likely to err. We argue that semantic variability need not imply error--this being especially intuitive in open-ended settings, where prompts elicit multiple adequate but semantically distinct responses. Hence, we propose to annotate sampled responses for their adequacy to the prompt (e.g., using a classifier) and estimate the Probability the model assigns to Adequate Responses (PROBAR), which we then regard as an indicator of the model's reliability at the instance level. We evaluate PROBAR as a measure of confidence in selective prediction with OPT models (in two QA datasets and in next-word prediction, for English) and find PROBAR to outperform semantic entropy across prompts with varying degrees of ambiguity/open-endedness.
Explanation Regularisation through the Lens of Attributions
Jul 23, 2024Explanation regularisation (ER) has been introduced as a way to guide models to make their predictions in a manner more akin to humans, i.e., making their attributions "plausible". This is achieved by introducing an auxiliary explanation loss, that measures how well the output of an input attribution technique for the model agrees with relevant human-annotated rationales. One positive outcome of using ER appears to be improved performance in out-of-domain (OOD) settings, presumably due to an increased reliance on "plausible" tokens. However, previous work has under-explored the impact of the ER objective on model attributions, in particular when obtained with techniques other than the one used to train ER. In this work, we contribute a study of ER's effectiveness at informing classification decisions on plausible tokens, and the relationship between increased plausibility and robustness to OOD conditions. Through a series of analyses, we find that the connection between ER and the ability of a classifier to rely on plausible features has been overstated and that a stronger reliance on plausible tokens does not seem to be the cause for any perceived OOD improvements.
Predict the Next Word: <Humans exhibit uncertainty in this task and language models _____>
Feb 27, 2024Language models (LMs) are statistical models trained to assign probability to human-generated text. As such, it is reasonable to question whether they approximate linguistic variability exhibited by humans well. This form of statistical assessment is difficult to perform at the passage level, for it requires acceptability judgements (i.e., human evaluation) or a robust automated proxy (which is non-trivial). At the word level, however, given some context, samples from an LM can be assessed via exact matching against a prerecorded dataset of alternative single-word continuations of the available context. We exploit this fact and evaluate the LM's ability to reproduce variability that humans (in particular, a population of English speakers) exhibit in the 'next word prediction' task. This can be seen as assessing a form of calibration, which, in the context of text classification, Baan et al. (2022) termed calibration to human uncertainty. We assess GPT2, BLOOM and ChatGPT and find that they exhibit fairly low calibration to human uncertainty. We also verify the failure of expected calibration error (ECE) to reflect this, and as such, advise the community against relying on it in this setting.
Interpreting Predictive Probabilities: Model Confidence or Human Label Variation?
Feb 25, 2024With the rise of increasingly powerful and user-facing NLP systems, there is growing interest in assessing whether they have a good representation of uncertainty by evaluating the quality of their predictive distribution over outcomes. We identify two main perspectives that drive starkly different evaluation protocols. The first treats predictive probability as an indication of model confidence; the second as an indication of human label variation. We discuss their merits and limitations, and take the position that both are crucial for trustworthy and fair NLP systems, but that exploiting a single predictive distribution is limiting. We recommend tools and highlight exciting directions towards models with disentangled representations of uncertainty about predictions and uncertainty about human labels.
Uncertainty in Natural Language Generation: From Theory to Applications
Jul 28, 2023

Recent advances of powerful Language Models have allowed Natural Language Generation (NLG) to emerge as an important technology that can not only perform traditional tasks like summarisation or translation, but also serve as a natural language interface to a variety of applications. As such, it is crucial that NLG systems are trustworthy and reliable, for example by indicating when they are likely to be wrong; and supporting multiple views, backgrounds and writing styles -- reflecting diverse human sub-populations. In this paper, we argue that a principled treatment of uncertainty can assist in creating systems and evaluation protocols better aligned with these goals. We first present the fundamental theory, frameworks and vocabulary required to represent uncertainty. We then characterise the main sources of uncertainty in NLG from a linguistic perspective, and propose a two-dimensional taxonomy that is more informative and faithful than the popular aleatoric/epistemic dichotomy. Finally, we move from theory to applications and highlight exciting research directions that exploit uncertainty to power decoding, controllable generation, self-assessment, selective answering, active learning and more.
What Comes Next? Evaluating Uncertainty in Neural Text Generators Against Human Production Variability
May 19, 2023



In Natural Language Generation (NLG) tasks, for any input, multiple communicative goals are plausible, and any goal can be put into words, or produced, in multiple ways. We characterise the extent to which human production varies lexically, syntactically, and semantically across four NLG tasks, connecting human production variability to aleatoric or data uncertainty. We then inspect the space of output strings shaped by a generation system's predicted probability distribution and decoding algorithm to probe its uncertainty. For each test input, we measure the generator's calibration to human production variability. Following this instance-level approach, we analyse NLG models and decoding strategies, demonstrating that probing a generator with multiple samples and, when possible, multiple references, provides the level of detail necessary to gain understanding of a model's representation of uncertainty.
VISION DIFFMASK: Faithful Interpretation of Vision Transformers with Differentiable Patch Masking
Apr 13, 2023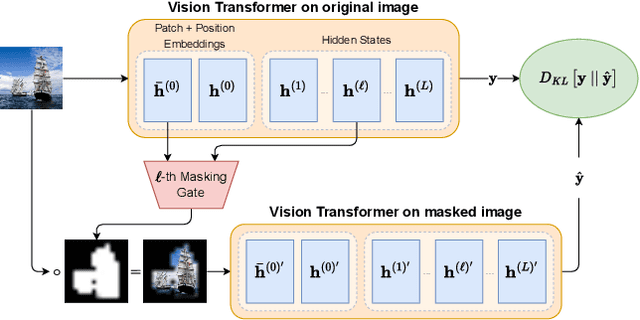
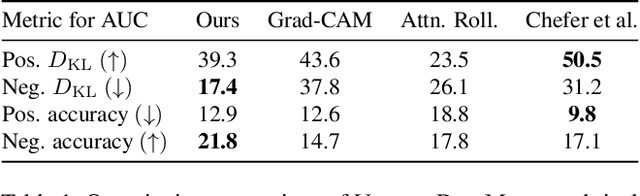


The lack of interpretability of the Vision Transformer may hinder its use in critical real-world applications despite its effectiveness. To overcome this issue, we propose a post-hoc interpretability method called VISION DIFFMASK, which uses the activations of the model's hidden layers to predict the relevant parts of the input that contribute to its final predictions. Our approach uses a gating mechanism to identify the minimal subset of the original input that preserves the predicted distribution over classes. We demonstrate the faithfulness of our method, by introducing a faithfulness task, and comparing it to other state-of-the-art attribution methods on CIFAR-10 and ImageNet-1K, achieving compelling results. To aid reproducibility and further extension of our work, we open source our implementation: https://github.com/AngelosNal/Vision-DiffMask