 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReranking Laws for Language Generation: A Communication-Theoretic Perspective
Sep 11, 2024



To ensure large language models (LLMs) are used safely, one must reduce their propensity to hallucinate or to generate unacceptable answers. A simple and often used strategy is to first let the LLM generate multiple hypotheses and then employ a reranker to choose the best one. In this paper, we draw a parallel between this strategy and the use of redundancy to decrease the error rate in noisy communication channels. We conceptualize the generator as a sender transmitting multiple descriptions of a message through parallel noisy channels. The receiver decodes the message by ranking the (potentially corrupted) descriptions and selecting the one found to be most reliable. We provide conditions under which this protocol is asymptotically error-free (i.e., yields an acceptable answer almost surely) even in scenarios where the reranker is imperfect (governed by Mallows or Zipf-Mandelbrot models) and the channel distributions are statistically dependent. We use our framework to obtain reranking laws which we validate empirically on two real-world tasks using LLMs: text-to-code generation with DeepSeek-Coder 7B and machine translation of medical data with TowerInstruct 13B.
DOCE: Finding the Sweet Spot for Execution-Based Code Generation
Aug 25, 2024



Recently, a diverse set of decoding and reranking procedures have been shown effective for LLM-based code generation. However, a comprehensive framework that links and experimentally compares these methods is missing. We address this by proposing Decoding Objectives for Code Execution, a comprehensive framework that includes candidate generation, $n$-best reranking, minimum Bayes risk (MBR) decoding, and self-debugging as the core components. We then study the contributions of these components through execution-based evaluation metrics. Our findings highlight the importance of execution-based methods and the difference gap between execution-based and execution-free methods. Furthermore, we assess the impact of filtering based on trial unit tests, a simple and effective strategy that has been often overlooked in prior works. We also propose self-debugging on multiple candidates, obtaining state-of-the-art performance on reranking for code generation. We expect our framework to provide a solid guideline for future research on code generation.
Uncertainty in Natural Language Generation: From Theory to Applications
Jul 28, 2023

Recent advances of powerful Language Models have allowed Natural Language Generation (NLG) to emerge as an important technology that can not only perform traditional tasks like summarisation or translation, but also serve as a natural language interface to a variety of applications. As such, it is crucial that NLG systems are trustworthy and reliable, for example by indicating when they are likely to be wrong; and supporting multiple views, backgrounds and writing styles -- reflecting diverse human sub-populations. In this paper, we argue that a principled treatment of uncertainty can assist in creating systems and evaluation protocols better aligned with these goals. We first present the fundamental theory, frameworks and vocabulary required to represent uncertainty. We then characterise the main sources of uncertainty in NLG from a linguistic perspective, and propose a two-dimensional taxonomy that is more informative and faithful than the popular aleatoric/epistemic dichotomy. Finally, we move from theory to applications and highlight exciting research directions that exploit uncertainty to power decoding, controllable generation, self-assessment, selective answering, active learning and more.
Asking Clarification Questions for Code Generation in General-Purpose Programming Language
Dec 19, 2022Code generation from text requires understanding the user's intent from a natural language description (NLD) and generating an executable program code snippet that satisfies this intent. While recent pretrained language models (PLMs) demonstrate remarkable performance for this task, these models fail when the given NLD is ambiguous due to the lack of enough specifications for generating a high-quality code snippet. In this work, we introduce a novel and more realistic setup for this task. We hypothesize that ambiguities in the specifications of an NLD are resolved by asking clarification questions (CQs). Therefore, we collect and introduce a new dataset named CodeClarQA containing NLD-Code pairs with created CQAs. We evaluate the performance of PLMs for code generation on our dataset. The empirical results support our hypothesis that clarifications result in more precise generated code, as shown by an improvement of 17.52 in BLEU, 12.72 in CodeBLEU, and 7.7\% in the exact match. Alongside this, our task and dataset introduce new challenges to the community, including when and what CQs should be asked.
When Do You Need Billions of Words of Pretraining Data?
Nov 10, 2020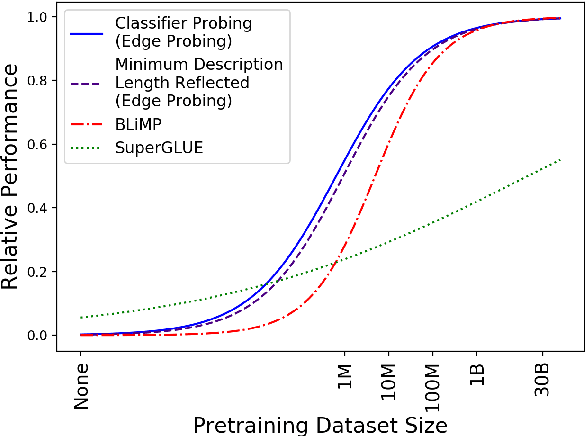


NLP is currently dominated by general-purpose pretrained language models like RoBERTa, which achieve strong performance on NLU tasks through pretraining on billions of words. But what exact knowledge or skills do Transformer LMs learn from large-scale pretraining that they cannot learn from less data? We adopt four probing methods---classifier probing, information-theoretic probing, unsupervised relative acceptability judgment, and fine-tuning on NLU tasks---and draw learning curves that track the growth of these different measures of linguistic ability with respect to pretraining data volume using the MiniBERTas, a group of RoBERTa models pretrained on 1M, 10M, 100M and 1B words. We find that LMs require only about 10M or 100M words to learn representations that reliably encode most syntactic and semantic features we test. A much larger quantity of data is needed in order to acquire enough commonsense knowledge and other skills required to master typical downstream NLU tasks. The results suggest that, while the ability to encode linguistic features is almost certainly necessary for language understanding, it is likely that other forms of knowledge are the major drivers of recent improvements in language understanding among large pretrained models.
Learning Which Features Matter: RoBERTa Acquires a Preference for Linguistic Generalizations (Eventually)
Oct 11, 2020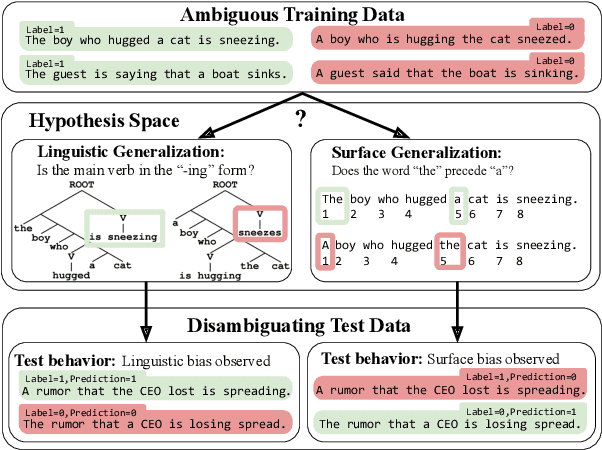


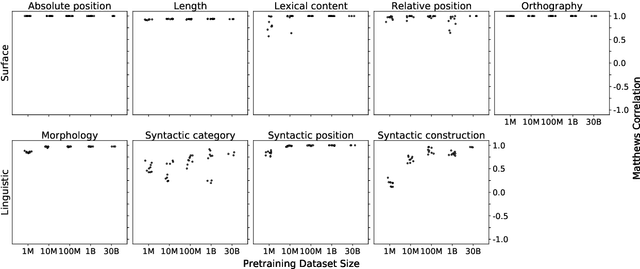
One reason pretraining on self-supervised linguistic tasks is effective is that it teaches models features that are helpful for language understanding. However, we want pretrained models to learn not only to represent linguistic features, but also to use those features preferentially during fine-turning. With this goal in mind, we introduce a new English-language diagnostic set called MSGS (the Mixed Signals Generalization Set), which consists of 20 ambiguous binary classification tasks that we use to test whether a pretrained model prefers linguistic or surface generalizations during fine-tuning. We pretrain RoBERTa models from scratch on quantities of data ranging from 1M to 1B words and compare their performance on MSGS to the publicly available RoBERTa-base. We find that models can learn to represent linguistic features with little pretraining data, but require far more data to learn to prefer linguistic generalizations over surface ones. Eventually, with about 30B words of pretraining data, RoBERTa-base does demonstrate a linguistic bias with some regularity. We conclude that while self-supervised pretraining is an effective way to learn helpful inductive biases, there is likely room to improve the rate at which models learn which features matter.