 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Graph Foundation Models on Riemannian Graph-of-Graphs
May 11, 2026Graph foundation models (GFMs), pretrained on massive graph data, have transformed graph machine learning by supporting general-purpose reasoning across diverse graph tasks and domains. Existing GFMs pretrained with fixed-hop subgraph sampling impose a fixed receptive field, causing scale mismatch on diverse tasks, which often require heterogeneous and unknown structural contexts beyond a fixed sampling scale. We propose R-GFM, a Riemannian Graph-of-Graphs (GoG) based foundation model, that treats structural scale as a first-class citizen in modeling. R-GFM constructs a multi-scale GoG over-sampled subgraphs at different hop distances and learns geometry-adaptive representations from Riemannian manifolds. Theoretical analysis shows that R-GFM reduces structural domain generalization error compared to fixed-scale GFMs. Experiments on various datasets demonstrate that R-GFM achieves state-of-the-art performance, with up to a 49% relative improvement on downstream tasks. Our code is available at https://github.com/USTC-DataDarknessLab/R-GFM.
CoFL: Continuous Flow Fields for Language-Conditioned Navigation
Mar 03, 2026Language-conditioned navigation pipelines often rely on brittle modular components or costly action-sequence generation. To address these limitations, we present CoFL, an end-to-end policy that directly maps a bird's-eye view (BEV) observation and a language instruction to a continuous flow field for navigation. Instead of predicting discrete action tokens or sampling action chunks via iterative denoising, CoFL outputs instantaneous velocities that can be queried at arbitrary 2D projected locations. Trajectories are obtained by numerical integration of the predicted field, producing smooth motion that remains reactive under closed-loop execution. To enable large-scale training, we build a dataset of over 500k BEV image-instruction pairs, each procedurally annotated with a flow field and a trajectory derived from BEV semantic maps built on Matterport3D and ScanNet. By training on a mixed distribution, CoFL significantly outperforms modular Vision-Language Model (VLM)-based planners and generative policy baselines on strictly unseen scenes. Finally, we deploy CoFL zero-shot in real-world experiments with overhead BEV observations across multiple layouts, maintaining reliable closed-loop control and a high success rate.
Learning Agile and Robust Omnidirectional Aerial Motion on Overactuated Tiltable-Quadrotors
Feb 25, 2026Tilt-rotor aerial robots enable omnidirectional maneuvering through thrust vectoring, but introduce significant control challenges due to the strong coupling between joint and rotor dynamics. While model-based controllers can achieve high motion accuracy under nominal conditions, their robustness and responsiveness often degrade in the presence of disturbances and modeling uncertainties. This work investigates reinforcement learning for omnidirectional aerial motion control on over-actuated tiltable quadrotors that prioritizes robustness and agility. We present a learning-based control framework that enables efficient acquisition of coordinated rotor-joint behaviors for reaching target poses in the $SE(3)$ space. To achieve reliable sim-to-real transfer while preserving motion accuracy, we integrate system identification with minimal and physically consistent domain randomization. Compared with a state-of-the-art NMPC controller, the proposed method achieves comparable six-degree-of-freedom pose tracking accuracy, while demonstrating superior robustness and generalization across diverse tasks, enabling zero-shot deployment on real hardware.
Hierarchical Trajectory Planning of Floating-Base Multi-Link Robot for Maneuvering in Confined Environments
Feb 25, 2026Floating-base multi-link robots can change their shape during flight, making them well-suited for applications in confined environments such as autonomous inspection and search and rescue. However, trajectory planning for such systems remains an open challenge because the problem lies in a high-dimensional, constraint-rich space where collision avoidance must be addressed together with kinematic limits and dynamic feasibility. This work introduces a hierarchical trajectory planning framework that integrates global guidance with configuration-aware local optimization. First, we exploit the dual nature of these robots - the root link as a rigid body for guidance and the articulated joints for flexibility - to generate global anchor states that decompose the planning problem into tractable segments. Second, we design a local trajectory planner that optimizes each segment in parallel with differentiable objectives and constraints, systematically enforcing kinematic feasibility and maintaining dynamic feasibility by avoiding control singularities. Third, we implement a complete system that directly processes point-cloud data, eliminating the need for handcrafted obstacle models. Extensive simulations and real-world experiments confirm that this framework enables an articulated aerial robot to exploit its morphology for maneuvering that rigid robots cannot achieve. To the best of our knowledge, this is the first planning framework for floating-base multi-link robots that has been demonstrated on a real robot to generate continuous, collision-free, and dynamically feasible trajectories directly from raw point-cloud inputs, without relying on handcrafted obstacle models.
The Appeal and Reality of Recycling LoRAs with Adaptive Merging
Feb 12, 2026The widespread availability of fine-tuned LoRA modules for open pre-trained models has led to an interest in methods that can adaptively merge LoRAs to improve performance. These methods typically include some way of selecting LoRAs from a pool and tune merging coefficients based on a task-specific dataset. While adaptive merging methods have demonstrated improvements in some settings, no past work has attempted to recycle LoRAs found "in the wild" on model repositories like the Hugging Face Hub. To address this gap, we consider recycling from a pool of nearly 1,000 user-contributed LoRAs trained from the Llama 3.1 8B-Instruct language model. Our empirical study includes a range of adaptive and non-adaptive merging methods in addition to a new method designed via a wide search over the methodological design space. We demonstrate that adaptive merging methods can improve performance over the base model but provide limited benefit over training a new LoRA on the same data used to set merging coefficients. We additionally find not only that the specific choice of LoRAs to merge has little importance, but that using LoRAs with randomly initialized parameter values yields similar performance. This raises the possibility that adaptive merging from recycled LoRAs primarily works via some kind of regularization effect, rather than by enabling positive cross-task transfer. To better understand why past work has proven successful, we confirm that positive transfer is indeed possible when there are highly relevant LoRAs in the pool. We release the model checkpoints and code online.
Hierarchical Language Models for Semantic Navigation and Manipulation in an Aerial-Ground Robotic System
Jun 05, 2025Heterogeneous multi-robot systems show great potential in complex tasks requiring coordinated hybrid cooperation. However, traditional approaches relying on static models often struggle with task diversity and dynamic environments. This highlights the need for generalizable intelligence that can bridge high-level reasoning with low-level execution across heterogeneous agents. To address this, we propose a hierarchical framework integrating a prompted Large Language Model (LLM) and a GridMask-enhanced fine-tuned Vision Language Model (VLM). The LLM performs task decomposition and global semantic map construction, while the VLM extracts task-specified semantic labels and 2D spatial information from aerial images to support local planning. Within this framework, the aerial robot follows a globally optimized semantic path and continuously provides bird-view images, guiding the ground robot's local semantic navigation and manipulation, including target-absent scenarios where implicit alignment is maintained. Experiments on a real-world letter-cubes arrangement task demonstrate the framework's adaptability and robustness in dynamic environments. To the best of our knowledge, this is the first demonstration of an aerial-ground heterogeneous system integrating VLM-based perception with LLM-driven task reasoning and motion planning.
Enhancing Training Data Attribution with Representational Optimization
May 24, 2025Training data attribution (TDA) methods aim to measure how training data impacts a model's predictions. While gradient-based attribution methods, such as influence functions, offer theoretical grounding, their computational costs make them impractical for large-scale applications. Representation-based approaches are far more scalable, but typically rely on heuristic embeddings that are not optimized for attribution, limiting their fidelity. To address these challenges, we propose AirRep, a scalable, representation-based approach that closes this gap by learning task-specific and model-aligned representations optimized explicitly for TDA. AirRep introduces two key innovations: a trainable encoder tuned for attribution quality, and an attention-based pooling mechanism that enables accurate estimation of group-wise influence. We train AirRep using a ranking objective over automatically constructed training subsets labeled by their empirical effect on target predictions. Experiments on instruction-tuned LLMs demonstrate that AirRep achieves performance on par with state-of-the-art gradient-based approaches while being nearly two orders of magnitude more efficient at inference time. Further analysis highlights its robustness and generalization across tasks and models. Our code is available at https://github.com/sunnweiwei/AirRep.
HypoBench: Towards Systematic and Principled Benchmarking for Hypothesis Generation
Apr 15, 2025There is growing interest in hypothesis generation with large language models (LLMs). However, fundamental questions remain: what makes a good hypothesis, and how can we systematically evaluate methods for hypothesis generation? To address this, we introduce HypoBench, a novel benchmark designed to evaluate LLMs and hypothesis generation methods across multiple aspects, including practical utility, generalizability, and hypothesis discovery rate. HypoBench includes 7 real-world tasks and 5 synthetic tasks with 194 distinct datasets. We evaluate four state-of-the-art LLMs combined with six existing hypothesis-generation methods. Overall, our results suggest that existing methods are capable of discovering valid and novel patterns in the data. However, the results from synthetic datasets indicate that there is still significant room for improvement, as current hypothesis generation methods do not fully uncover all relevant or meaningful patterns. Specifically, in synthetic settings, as task difficulty increases, performance significantly drops, with best models and methods only recovering 38.8% of the ground-truth hypotheses. These findings highlight challenges in hypothesis generation and demonstrate that HypoBench serves as a valuable resource for improving AI systems designed to assist scientific discovery.
Explore the Reasoning Capability of LLMs in the Chess Testbed
Nov 11, 2024



Reasoning is a central capability of human intelligence. In recent years, with the advent of large-scale datasets, pretrained large language models have emerged with new capabilities, including reasoning. However, these models still struggle with long-term, complex reasoning tasks, such as playing chess. Based on the observation that expert chess players employ a dual approach combining long-term strategic play with short-term tactical play along with language explanation, we propose improving the reasoning capability of large language models in chess by integrating annotated strategy and tactic. Specifically, we collect a dataset named MATE, which consists of 1 million chess positions with candidate moves annotated by chess experts for strategy and tactics. We finetune the LLaMA-3-8B model and compare it against state-of-the-art commercial language models in the task of selecting better chess moves. Our experiments show that our models perform better than GPT, Claude, and Gemini models. We find that language explanations can enhance the reasoning capability of large language models.
Literature Meets Data: A Synergistic Approach to Hypothesis Generation
Oct 22, 2024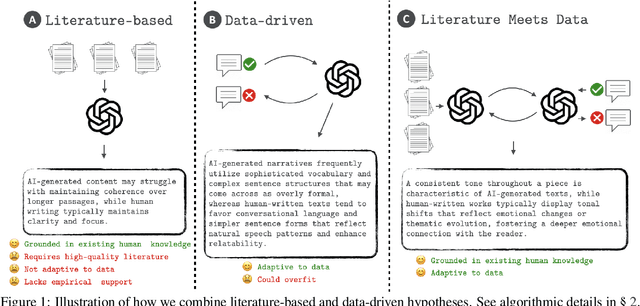
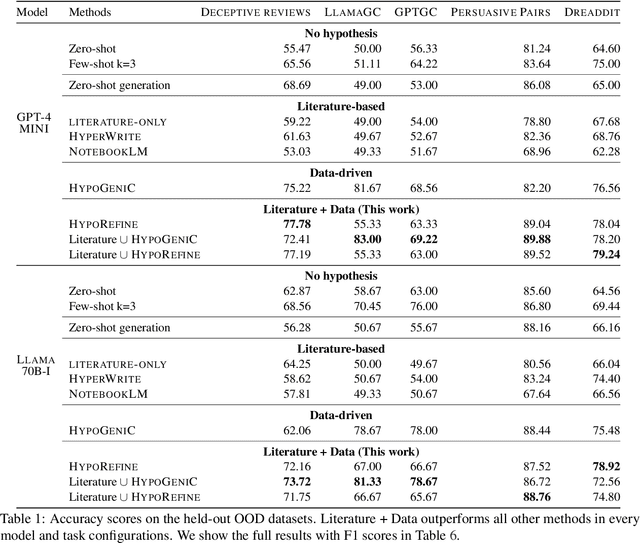
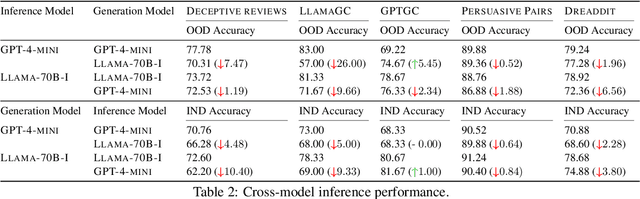
AI holds promise for transforming scientific processes, including hypothesis generation. Prior work on hypothesis generation can be broadly categorized into theory-driven and data-driven approaches. While both have proven effective in generating novel and plausible hypotheses, it remains an open question whether they can complement each other. To address this, we develop the first method that combines literature-based insights with data to perform LLM-powered hypothesis generation. We apply our method on five different datasets and demonstrate that integrating literature and data outperforms other baselines (8.97\% over few-shot, 15.75\% over literature-based alone, and 3.37\% over data-driven alone). Additionally, we conduct the first human evaluation to assess the utility of LLM-generated hypotheses in assisting human decision-making on two challenging tasks: deception detection and AI generated content detection. Our results show that human accuracy improves significantly by 7.44\% and 14.19\% on these tasks, respectively. These findings suggest that integrating literature-based and data-driven approaches provides a comprehensive and nuanced framework for hypothesis generation and could open new avenues for scientific inquiry.