 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBio-inspired fine-tuning for selective transfer learning in image classification
Jan 16, 2026Deep learning has significantly advanced image analysis across diverse domains but often depends on large, annotated datasets for success. Transfer learning addresses this challenge by utilizing pre-trained models to tackle new tasks with limited labeled data. However, discrepancies between source and target domains can hinder effective transfer learning. We introduce BioTune, a novel adaptive fine-tuning technique utilizing evolutionary optimization. BioTune enhances transfer learning by optimally choosing which layers to freeze and adjusting learning rates for unfrozen layers. Through extensive evaluation on nine image classification datasets, spanning natural and specialized domains such as medical imaging, BioTune demonstrates superior accuracy and efficiency over state-of-the-art fine-tuning methods, including AutoRGN and LoRA, highlighting its adaptability to various data characteristics and distribution changes. Additionally, BioTune consistently achieves top performance across four different CNN architectures, underscoring its flexibility. Ablation studies provide valuable insights into the impact of BioTune's key components on overall performance. The source code is available at https://github.com/davilac/BioTune.
Development of a Compliant Gripper for Safe Robot-Assisted Trouser Dressing-Undressing
Dec 10, 2025In recent years, many countries, including Japan, have rapidly aging populations, making the preservation of seniors' quality of life a significant concern. For elderly people with impaired physical abilities, support for toileting is one of the most important issues. This paper details the design, development, experimental assessment, and potential application of the gripper system, with a focus on the unique requirements and obstacles involved in aiding elderly or hemiplegic individuals in dressing and undressing trousers. The gripper we propose seeks to find the right balance between compliance and grasping forces, ensuring precise manipulation while maintaining a safe and compliant interaction with the users. The gripper's integration into a custom--built robotic manipulator system provides a comprehensive solution for assisting hemiplegic individuals in their dressing and undressing tasks. Experimental evaluations and comparisons with existing studies demonstrate the gripper's ability to successfully assist in both dressing and dressing of trousers in confined spaces with a high success rate. This research contributes to the advancement of assistive robotics, empowering elderly, and physically impaired individuals to maintain their independence and improve their quality of life.
Affordance-Based Disambiguation of Surgical Instructions for Collaborative Robot-Assisted Surgery
Sep 18, 2025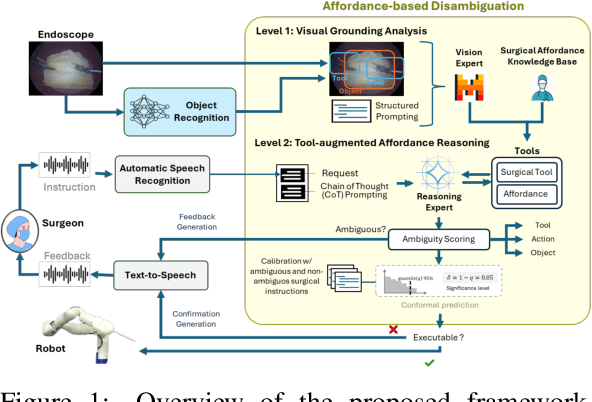
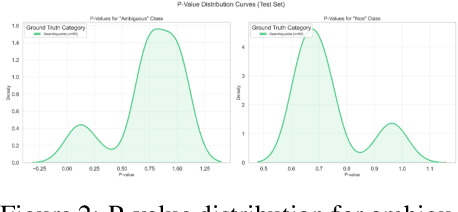
Effective human-robot collaboration in surgery is affected by the inherent ambiguity of verbal communication. This paper presents a framework for a robotic surgical assistant that interprets and disambiguates verbal instructions from a surgeon by grounding them in the visual context of the operating field. The system employs a two-level affordance-based reasoning process that first analyzes the surgical scene using a multimodal vision-language model and then reasons about the instruction using a knowledge base of tool capabilities. To ensure patient safety, a dual-set conformal prediction method is used to provide a statistically rigorous confidence measure for robot decisions, allowing it to identify and flag ambiguous commands. We evaluated our framework on a curated dataset of ambiguous surgical requests from cholecystectomy videos, demonstrating a general disambiguation rate of 60% and presenting a method for safer human-robot interaction in the operating room.
Assessing the Value of Visual Input: A Benchmark of Multimodal Large Language Models for Robotic Path Planning
Jul 16, 2025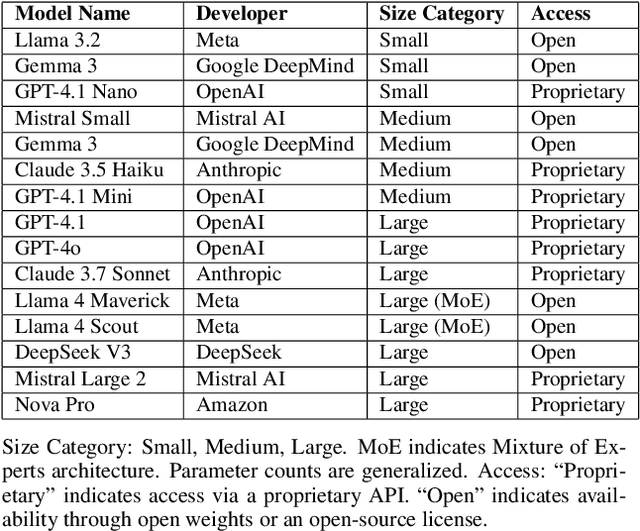

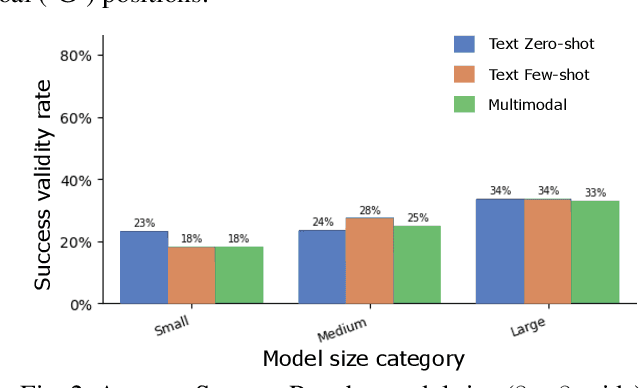

Large Language Models (LLMs) show potential for enhancing robotic path planning. This paper assesses visual input's utility for multimodal LLMs in such tasks via a comprehensive benchmark. We evaluated 15 multimodal LLMs on generating valid and optimal paths in 2D grid environments, simulating simplified robotic planning, comparing text-only versus text-plus-visual inputs across varying model sizes and grid complexities. Our results indicate moderate success rates on simpler small grids, where visual input or few-shot text prompting offered some benefits. However, performance significantly degraded on larger grids, highlighting a scalability challenge. While larger models generally achieved higher average success, the visual modality was not universally dominant over well-structured text for these multimodal systems, and successful paths on simpler grids were generally of high quality. These results indicate current limitations in robust spatial reasoning, constraint adherence, and scalable multimodal integration, identifying areas for future LLM development in robotic path planning.
* Accepted at the 2025 SICE Festival with Annual Conference (SICE FES)
Beyond Single Models: Enhancing LLM Detection of Ambiguity in Requests through Debate
Jul 16, 2025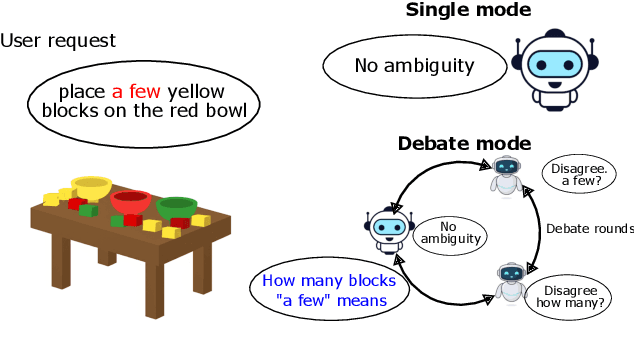
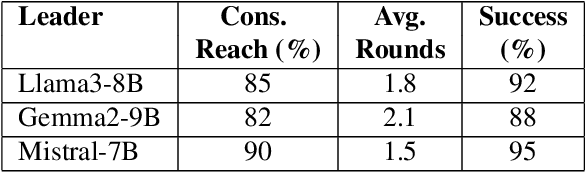
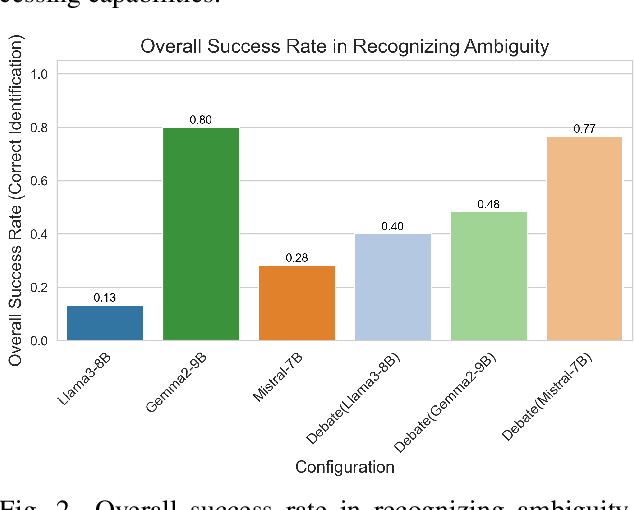
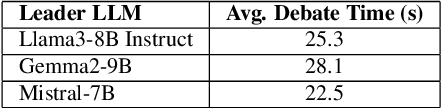
Large Language Models (LLMs) have demonstrated significant capabilities in understanding and generating human language, contributing to more natural interactions with complex systems. However, they face challenges such as ambiguity in user requests processed by LLMs. To address these challenges, this paper introduces and evaluates a multi-agent debate framework designed to enhance detection and resolution capabilities beyond single models. The framework consists of three LLM architectures (Llama3-8B, Gemma2-9B, and Mistral-7B variants) and a dataset with diverse ambiguities. The debate framework markedly enhanced the performance of Llama3-8B and Mistral-7B variants over their individual baselines, with Mistral-7B-led debates achieving a notable 76.7% success rate and proving particularly effective for complex ambiguities and efficient consensus. While acknowledging varying model responses to collaborative strategies, these findings underscore the debate framework's value as a targeted method for augmenting LLM capabilities. This work offers important insights for developing more robust and adaptive language understanding systems by showing how structured debates can lead to improved clarity in interactive systems.
* Accepted at the 2025 SICE Festival with Annual Conference (SICE FES)
LLM-based ambiguity detection in natural language instructions for collaborative surgical robots
Jul 15, 2025Ambiguity in natural language instructions poses significant risks in safety-critical human-robot interaction, particularly in domains such as surgery. To address this, we propose a framework that uses Large Language Models (LLMs) for ambiguity detection specifically designed for collaborative surgical scenarios. Our method employs an ensemble of LLM evaluators, each configured with distinct prompting techniques to identify linguistic, contextual, procedural, and critical ambiguities. A chain-of-thought evaluator is included to systematically analyze instruction structure for potential issues. Individual evaluator assessments are synthesized through conformal prediction, which yields non-conformity scores based on comparison to a labeled calibration dataset. Evaluating Llama 3.2 11B and Gemma 3 12B, we observed classification accuracy exceeding 60% in differentiating ambiguous from unambiguous surgical instructions. Our approach improves the safety and reliability of human-robot collaboration in surgery by offering a mechanism to identify potentially ambiguous instructions before robot action.
* Accepted at 2025 IEEE International Conference on Robot and Human Interactive Communication (ROMAN)
Human-Robot collaboration in surgery: Advances and challenges towards autonomous surgical assistants
Jul 15, 2025Human-robot collaboration in surgery represents a significant area of research, driven by the increasing capability of autonomous robotic systems to assist surgeons in complex procedures. This systematic review examines the advancements and persistent challenges in the development of autonomous surgical robotic assistants (ASARs), focusing specifically on scenarios where robots provide meaningful and active support to human surgeons. Adhering to the PRISMA guidelines, a comprehensive literature search was conducted across the IEEE Xplore, Scopus, and Web of Science databases, resulting in the selection of 32 studies for detailed analysis. Two primary collaborative setups were identified: teleoperation-based assistance and direct hands-on interaction. The findings reveal a growing research emphasis on ASARs, with predominant applications currently in endoscope guidance, alongside emerging progress in autonomous tool manipulation. Several key challenges hinder wider adoption, including the alignment of robotic actions with human surgeon preferences, the necessity for procedural awareness within autonomous systems, the establishment of seamless human-robot information exchange, and the complexities of skill acquisition in shared workspaces. This review synthesizes current trends, identifies critical limitations, and outlines future research directions essential to improve the reliability, safety, and effectiveness of human-robot collaboration in surgical environments.
* Accepted at 2025 IEEE International Conference on Robot and Human Interactive Communication (ROMAN)
Embedded Image-to-Image Translation for Efficient Sim-to-Real Transfer in Learning-based Robot-Assisted Soft Manipulation
Sep 16, 2024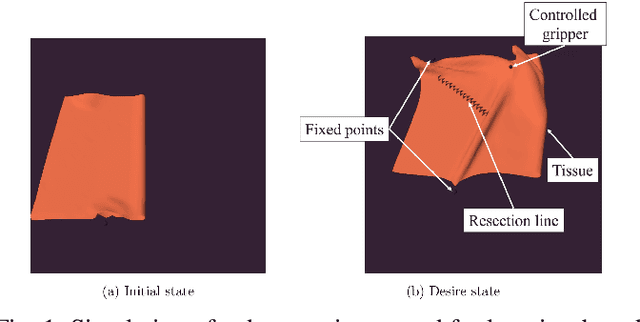


Recent advances in robotic learning in simulation have shown impressive results in accelerating learning complex manipulation skills. However, the sim-to-real gap, caused by discrepancies between simulation and reality, poses significant challenges for the effective deployment of autonomous surgical systems. We propose a novel approach utilizing image translation models to mitigate domain mismatches and facilitate efficient robot skill learning in a simulated environment. Our method involves the use of contrastive unpaired Image-to-image translation, allowing for the acquisition of embedded representations from these transformed images. Subsequently, these embeddings are used to improve the efficiency of training surgical manipulation models. We conducted experiments to evaluate the performance of our approach, demonstrating that it significantly enhances task success rates and reduces the steps required for task completion compared to traditional methods. The results indicate that our proposed system effectively bridges the sim-to-real gap, providing a robust framework for advancing the autonomy of surgical robots in minimally invasive procedures.
A hierarchical framework for collision avoidance in robot-assisted minimally invasive surgery
Sep 16, 2024
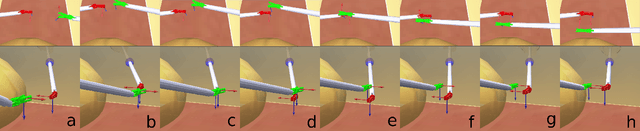
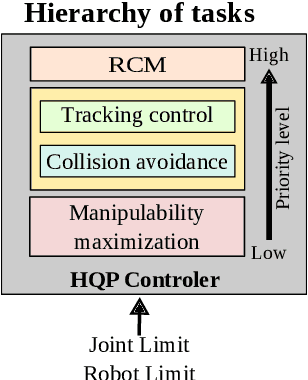
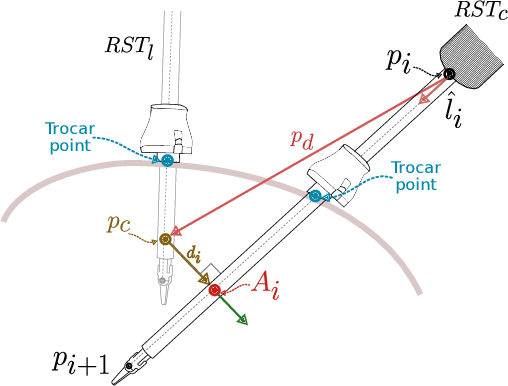
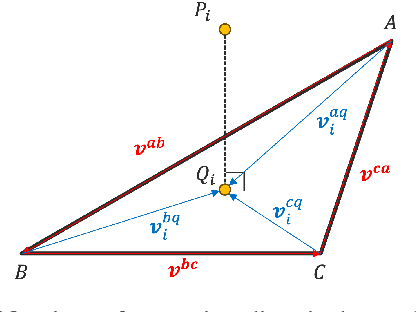
Minimally invasive surgery (MIS) procedures benefit significantly from robotic systems due to their improved precision and dexterity. However, ensuring safety in these dynamic and cluttered environments is an ongoing challenge. This paper proposes a novel hierarchical framework for collision avoidance in MIS. This framework integrates multiple tasks, including maintaining the Remote Center of Motion (RCM) constraint, tracking desired tool poses, avoiding collisions, optimizing manipulability, and adhering to joint limits. The proposed approach utilizes Hierarchical Quadratic Programming (HQP) to seamlessly manage these constraints while enabling smooth transitions between task priorities for collision avoidance. Experimental validation through simulated scenarios demonstrates the framework's robustness and effectiveness in handling diverse scenarios involving static and dynamic obstacles, as well as inter-tool collisions.
Voice control interface for surgical robot assistants
Sep 16, 2024Traditional control interfaces for robotic-assisted minimally invasive surgery impose a significant cognitive load on surgeons. To improve surgical efficiency, surgeon-robot collaboration capabilities, and reduce surgeon burden, we present a novel voice control interface for surgical robotic assistants. Our system integrates Whisper, state-of-the-art speech recognition, within the ROS framework to enable real-time interpretation and execution of voice commands for surgical manipulator control. The proposed system consists of a speech recognition module, an action mapping module, and a robot control module. Experimental results demonstrate the system's high accuracy and inference speed, and demonstrates its feasibility for surgical applications in a tissue triangulation task. Future work will focus on further improving its robustness and clinical applicability.