 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUCSC at SemEval-2025 Task 3: Context, Models and Prompt Optimization for Automated Hallucination Detection in LLM Output
May 05, 2025Hallucinations pose a significant challenge for large language models when answering knowledge-intensive queries. As LLMs become more widely adopted, it is crucial not only to detect if hallucinations occur but also to pinpoint exactly where in the LLM output they occur. SemEval 2025 Task 3, Mu-SHROOM: Multilingual Shared-task on Hallucinations and Related Observable Overgeneration Mistakes, is a recent effort in this direction. This paper describes the UCSC system submission to the shared Mu-SHROOM task. We introduce a framework that first retrieves relevant context, next identifies false content from the answer, and finally maps them back to spans in the LLM output. The process is further enhanced by automatically optimizing prompts. Our system achieves the highest overall performance, ranking #1 in average position across all languages. We release our code and experiment results.
HypoBench: Towards Systematic and Principled Benchmarking for Hypothesis Generation
Apr 15, 2025There is growing interest in hypothesis generation with large language models (LLMs). However, fundamental questions remain: what makes a good hypothesis, and how can we systematically evaluate methods for hypothesis generation? To address this, we introduce HypoBench, a novel benchmark designed to evaluate LLMs and hypothesis generation methods across multiple aspects, including practical utility, generalizability, and hypothesis discovery rate. HypoBench includes 7 real-world tasks and 5 synthetic tasks with 194 distinct datasets. We evaluate four state-of-the-art LLMs combined with six existing hypothesis-generation methods. Overall, our results suggest that existing methods are capable of discovering valid and novel patterns in the data. However, the results from synthetic datasets indicate that there is still significant room for improvement, as current hypothesis generation methods do not fully uncover all relevant or meaningful patterns. Specifically, in synthetic settings, as task difficulty increases, performance significantly drops, with best models and methods only recovering 38.8% of the ground-truth hypotheses. These findings highlight challenges in hypothesis generation and demonstrate that HypoBench serves as a valuable resource for improving AI systems designed to assist scientific discovery.
ArterialNet: Reconstructing Arterial Blood Pressure Waveform with Wearable Pulsatile Signals, a Cohort-Aware Approach
Oct 24, 2024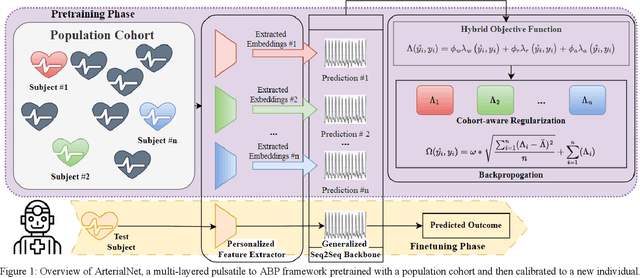


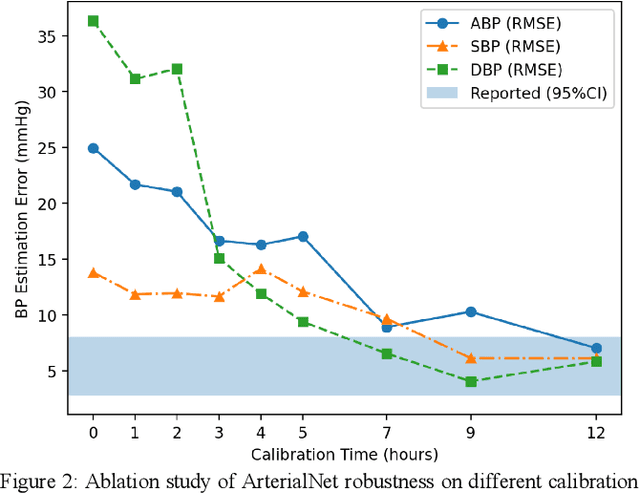
Continuous arterial blood pressure (ABP) monitoring is invasive but essential for hemodynamic monitoring. Recent techniques have reconstructed ABP non-invasively using pulsatile signals but produced inaccurate systolic and diastolic blood pressure (SBP and DBP) values and were sensitive to individual variability. ArterialNet integrates generalized pulsatile-to-ABP signal translation and personalized feature extraction using hybrid loss functions and regularization. We validated ArterialNet using the MIMIC-III dataset and achieved a root mean square error (RMSE) of 5.41 mmHg, with at least a 58% lower standard deviation. ArterialNet reconstructed ABP with an RMSE of 7.99 mmHg in remote health scenarios. ArterialNet achieved superior performance in ABP reconstruction and SBP and DBP estimations, with significantly reduced subject variance, demonstrating its potential in remote health settings. We also ablated ArterialNet architecture to investigate the contributions of each component and evaluated its translational impact and robustness by conducting a series of ablations on data quality and availability.
Rethinking Test-time Likelihood: The Likelihood Path Principle and Its Application to OOD Detection
Jan 10, 2024While likelihood is attractive in theory, its estimates by deep generative models (DGMs) are often broken in practice, and perform poorly for out of distribution (OOD) Detection. Various recent works started to consider alternative scores and achieved better performances. However, such recipes do not come with provable guarantees, nor is it clear that their choices extract sufficient information. We attempt to change this by conducting a case study on variational autoencoders (VAEs). First, we introduce the likelihood path (LPath) principle, generalizing the likelihood principle. This narrows the search for informative summary statistics down to the minimal sufficient statistics of VAEs' conditional likelihoods. Second, introducing new theoretic tools such as nearly essential support, essential distance and co-Lipschitzness, we obtain non-asymptotic provable OOD detection guarantees for certain distillation of the minimal sufficient statistics. The corresponding LPath algorithm demonstrates SOTA performances, even using simple and small VAEs with poor likelihood estimates. To our best knowledge, this is the first provable unsupervised OOD method that delivers excellent empirical results, better than any other VAEs based techniques. We use the same model as \cite{xiao2020likelihood}, open sourced from: https://github.com/XavierXiao/Likelihood-Regret
Inverse Scaling: When Bigger Isn't Better
Jun 15, 2023



Work on scaling laws has found that large language models (LMs) show predictable improvements to overall loss with increased scale (model size, training data, and compute). Here, we present evidence for the claim that LMs may show inverse scaling, or worse task performance with increased scale, e.g., due to flaws in the training objective and data. We present empirical evidence of inverse scaling on 11 datasets collected by running a public contest, the Inverse Scaling Prize, with a substantial prize pool. Through analysis of the datasets, along with other examples found in the literature, we identify four potential causes of inverse scaling: (i) preference to repeat memorized sequences over following in-context instructions, (ii) imitation of undesirable patterns in the training data, (iii) tasks containing an easy distractor task which LMs could focus on, rather than the harder real task, and (iv) correct but misleading few-shot demonstrations of the task. We release the winning datasets at https://inversescaling.com/data to allow for further investigation of inverse scaling. Our tasks have helped drive the discovery of U-shaped and inverted-U scaling trends, where an initial trend reverses, suggesting that scaling trends are less reliable at predicting the behavior of larger-scale models than previously understood. Overall, our results suggest that there are tasks for which increased model scale alone may not lead to progress, and that more careful thought needs to go into the data and objectives for training language models.
Improving Mutual Information Estimation with Annealed and Energy-Based Bounds
Mar 13, 2023Mutual information (MI) is a fundamental quantity in information theory and machine learning. However, direct estimation of MI is intractable, even if the true joint probability density for the variables of interest is known, as it involves estimating a potentially high-dimensional log partition function. In this work, we present a unifying view of existing MI bounds from the perspective of importance sampling, and propose three novel bounds based on this approach. Since accurate estimation of MI without density information requires a sample size exponential in the true MI, we assume either a single marginal or the full joint density information is known. In settings where the full joint density is available, we propose Multi-Sample Annealed Importance Sampling (AIS) bounds on MI, which we demonstrate can tightly estimate large values of MI in our experiments. In settings where only a single marginal distribution is known, we propose Generalized IWAE (GIWAE) and MINE-AIS bounds. Our GIWAE bound unifies variational and contrastive bounds in a single framework that generalizes InfoNCE, IWAE, and Barber-Agakov bounds. Our MINE-AIS method improves upon existing energy-based methods such as MINE-DV and MINE-F by directly optimizing a tighter lower bound on MI. MINE-AIS uses MCMC sampling to estimate gradients for training and Multi-Sample AIS for evaluating the bound. Our methods are particularly suitable for evaluating MI in deep generative models, since explicit forms of the marginal or joint densities are often available. We evaluate our bounds on estimating the MI of VAEs and GANs trained on the MNIST and CIFAR datasets, and showcase significant gains over existing bounds in these challenging settings with high ground truth MI.
Efficient Parametric Approximations of Neural Network Function Space Distance
Feb 07, 2023It is often useful to compactly summarize important properties of model parameters and training data so that they can be used later without storing and/or iterating over the entire dataset. As a specific case, we consider estimating the Function Space Distance (FSD) over a training set, i.e. the average discrepancy between the outputs of two neural networks. We propose a Linearized Activation Function TRick (LAFTR) and derive an efficient approximation to FSD for ReLU neural networks. The key idea is to approximate the architecture as a linear network with stochastic gating. Despite requiring only one parameter per unit of the network, our approach outcompetes other parametric approximations with larger memory requirements. Applied to continual learning, our parametric approximation is competitive with state-of-the-art nonparametric approximations, which require storing many training examples. Furthermore, we show its efficacy in estimating influence functions accurately and detecting mislabeled examples without expensive iterations over the entire dataset.
ED-FAITH: Evaluating Dialogue Summarization on Faithfulness
Nov 15, 2022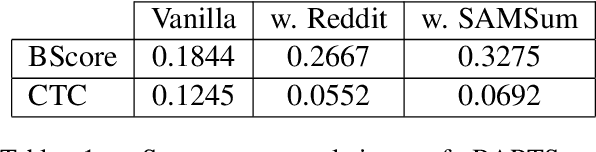

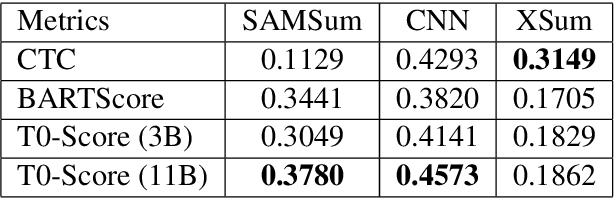
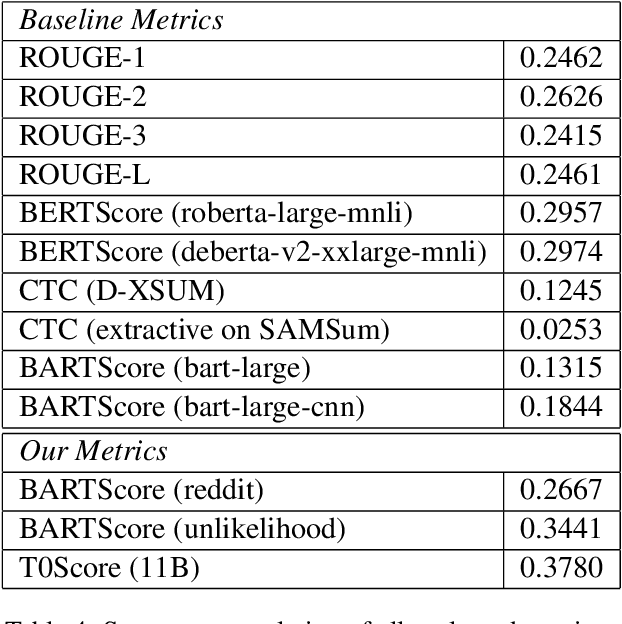
Abstractive summarization models typically generate content unfaithful to the input, thus highlighting the significance of evaluating the faithfulness of generated summaries. Most faithfulness metrics are only evaluated on news domain, can they be transferred to other summarization tasks? In this work, we first present a systematic study of faithfulness metrics for dialogue summarization. We evaluate common faithfulness metrics on dialogue datasets and observe that most metrics correlate poorly with human judgements despite performing well on news datasets. Given these findings, to improve existing metrics' performance on dialogue summarization, we first finetune on in-domain dataset, then apply unlikelihood training on negative samples, and show that they can successfully improve metric performance on dialogue data. Inspired by the strong zero-shot performance of the T0 language model, we further propose T0-Score -- a new metric for faithfulness evaluation, which shows consistent improvement against baseline metrics across multiple domains.
Evaluating Lossy Compression Rates of Deep Generative Models
Aug 15, 2020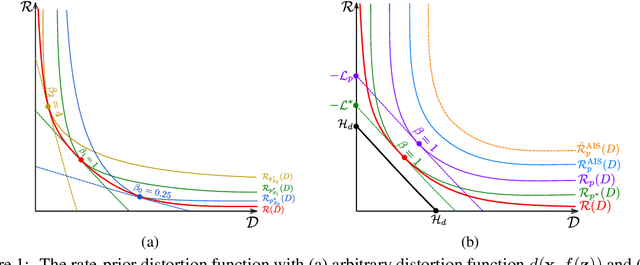

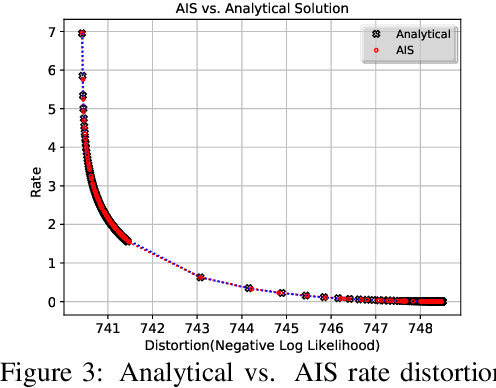
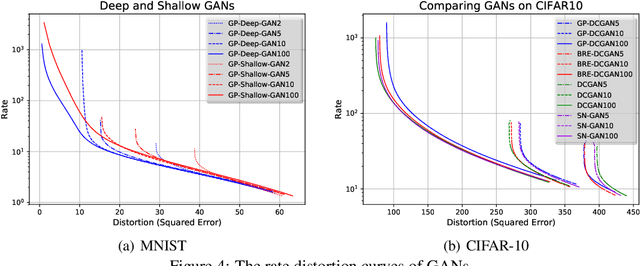
The field of deep generative modeling has succeeded in producing astonishingly realistic-seeming images and audio, but quantitative evaluation remains a challenge. Log-likelihood is an appealing metric due to its grounding in statistics and information theory, but it can be challenging to estimate for implicit generative models, and scalar-valued metrics give an incomplete picture of a model's quality. In this work, we propose to use rate distortion (RD) curves to evaluate and compare deep generative models. While estimating RD curves is seemingly even more computationally demanding than log-likelihood estimation, we show that we can approximate the entire RD curve using nearly the same computations as were previously used to achieve a single log-likelihood estimate. We evaluate lossy compression rates of VAEs, GANs, and adversarial autoencoders (AAEs) on the MNIST and CIFAR10 datasets. Measuring the entire RD curve gives a more complete picture than scalar-valued metrics, and we arrive at a number of insights not obtainable from log-likelihoods alone.
TimbreTron: A WaveNet(CycleGAN(CQT(Audio))) Pipeline for Musical Timbre Transfer
Nov 22, 2018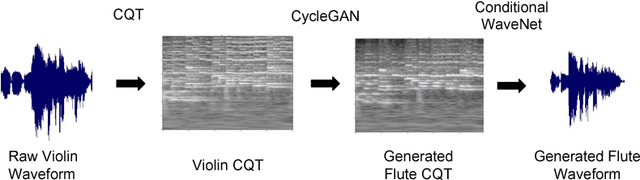

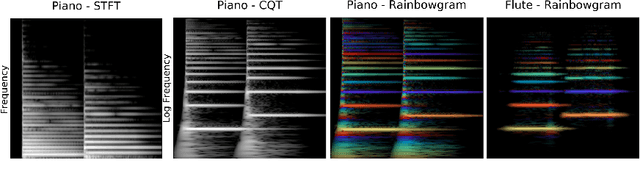
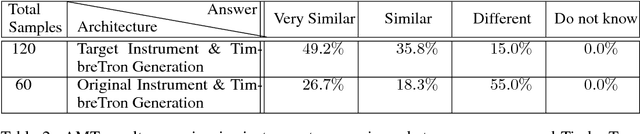
In this work, we address the problem of musical timbre transfer, where the goal is to manipulate the timbre of a sound sample from one instrument to match another instrument while preserving other musical content, such as pitch, rhythm, and loudness. In principle, one could apply image-based style transfer techniques to a time-frequency representation of an audio signal, but this depends on having a representation that allows independent manipulation of timbre as well as high-quality waveform generation. We introduce TimbreTron, a method for musical timbre transfer which applies "image" domain style transfer to a time-frequency representation of the audio signal, and then produces a high-quality waveform using a conditional WaveNet synthesizer. We show that the Constant Q Transform (CQT) representation is particularly well-suited to convolutional architectures due to its approximate pitch equivariance. Based on human perceptual evaluations, we confirmed that TimbreTron recognizably transferred the timbre while otherwise preserving the musical content, for both monophonic and polyphonic samples.