 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeED-FAITH: Evaluating Dialogue Summarization on Faithfulness
Paper and Code
Nov 15, 2022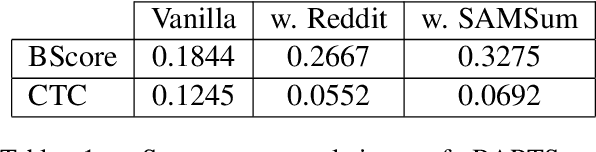

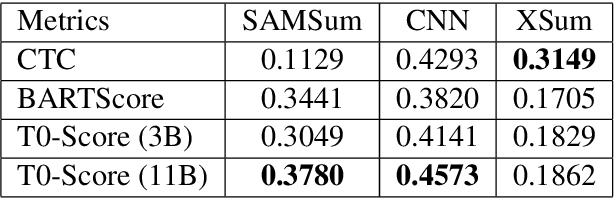
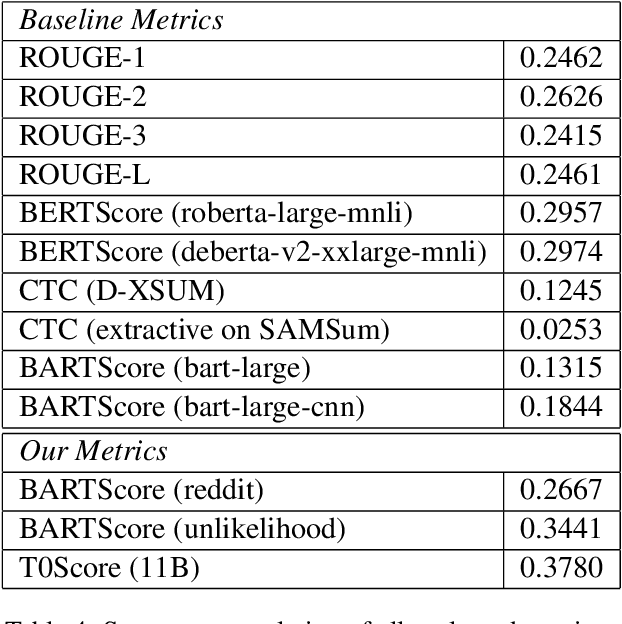
Abstractive summarization models typically generate content unfaithful to the input, thus highlighting the significance of evaluating the faithfulness of generated summaries. Most faithfulness metrics are only evaluated on news domain, can they be transferred to other summarization tasks? In this work, we first present a systematic study of faithfulness metrics for dialogue summarization. We evaluate common faithfulness metrics on dialogue datasets and observe that most metrics correlate poorly with human judgements despite performing well on news datasets. Given these findings, to improve existing metrics' performance on dialogue summarization, we first finetune on in-domain dataset, then apply unlikelihood training on negative samples, and show that they can successfully improve metric performance on dialogue data. Inspired by the strong zero-shot performance of the T0 language model, we further propose T0-Score -- a new metric for faithfulness evaluation, which shows consistent improvement against baseline metrics across multiple domains.