 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChemPile: A 250GB Diverse and Curated Dataset for Chemical Foundation Models
May 18, 2025



Foundation models have shown remarkable success across scientific domains, yet their impact in chemistry remains limited due to the absence of diverse, large-scale, high-quality datasets that reflect the field's multifaceted nature. We present the ChemPile, an open dataset containing over 75 billion tokens of curated chemical data, specifically built for training and evaluating general-purpose models in the chemical sciences. The dataset mirrors the human learning journey through chemistry -- from educational foundations to specialized expertise -- spanning multiple modalities and content types including structured data in diverse chemical representations (SMILES, SELFIES, IUPAC names, InChI, molecular renderings), scientific and educational text, executable code, and chemical images. ChemPile integrates foundational knowledge (textbooks, lecture notes), specialized expertise (scientific articles and language-interfaced data), visual understanding (molecular structures, diagrams), and advanced reasoning (problem-solving traces and code) -- mirroring how human chemists develop expertise through diverse learning materials and experiences. Constructed through hundreds of hours of expert curation, the ChemPile captures both foundational concepts and domain-specific complexity. We provide standardized training, validation, and test splits, enabling robust benchmarking. ChemPile is openly released via HuggingFace with a consistent API, permissive license, and detailed documentation. We hope the ChemPile will serve as a catalyst for chemical AI, enabling the development of the next generation of chemical foundation models.
Arabic Stable LM: Adapting Stable LM 2 1.6B to Arabic
Dec 05, 2024Large Language Models (LLMs) have shown impressive results in multiple domains of natural language processing (NLP) but are mainly focused on the English language. Recently, more LLMs have incorporated a larger proportion of multilingual text to represent low-resource languages. In Arabic NLP, several Arabic-centric LLMs have shown remarkable results on multiple benchmarks in the past two years. However, most Arabic LLMs have more than 7 billion parameters, which increases their hardware requirements and inference latency, when compared to smaller LLMs. This paper introduces Arabic Stable LM 1.6B in a base and chat version as a small but powerful Arabic-centric LLM. Our Arabic Stable LM 1.6B chat model achieves impressive results on several benchmarks beating multiple models with up to 8x the parameters. In addition, we show the benefit of mixing in synthetic instruction tuning data by augmenting our fine-tuning data with a large synthetic dialogue dataset.
Rephrasing natural text data with different languages and quality levels for Large Language Model pre-training
Oct 28, 2024



Recently published work on rephrasing natural text data for pre-training LLMs has shown promising results when combining the original dataset with the synthetically rephrased data. We build upon previous work by replicating existing results on C4 and extending them with our optimized rephrasing pipeline to the English, German, Italian, and Spanish Oscar subsets of CulturaX. Our pipeline leads to increased performance on standard evaluation benchmarks in both the mono- and multilingual setup. In addition, we provide a detailed study of our pipeline, investigating the choice of the base dataset and LLM for the rephrasing, as well as the relationship between the model size and the performance after pre-training. By exploring data with different perceived quality levels, we show that gains decrease with higher quality. Furthermore, we find the difference in performance between model families to be bigger than between different model sizes. This highlights the necessity for detailed tests before choosing an LLM to rephrase large amounts of data. Moreover, we investigate the effect of pre-training with synthetic data on supervised fine-tuning. Here, we find increasing but inconclusive results that highly depend on the used benchmark. These results (again) highlight the need for better benchmarking setups. In summary, we show that rephrasing multilingual and low-quality data is a very promising direction to extend LLM pre-training data.
Are large language models superhuman chemists?
Apr 01, 2024Large language models (LLMs) have gained widespread interest due to their ability to process human language and perform tasks on which they have not been explicitly trained. This is relevant for the chemical sciences, which face the problem of small and diverse datasets that are frequently in the form of text. LLMs have shown promise in addressing these issues and are increasingly being harnessed to predict chemical properties, optimize reactions, and even design and conduct experiments autonomously. However, we still have only a very limited systematic understanding of the chemical reasoning capabilities of LLMs, which would be required to improve models and mitigate potential harms. Here, we introduce "ChemBench," an automated framework designed to rigorously evaluate the chemical knowledge and reasoning abilities of state-of-the-art LLMs against the expertise of human chemists. We curated more than 7,000 question-answer pairs for a wide array of subfields of the chemical sciences, evaluated leading open and closed-source LLMs, and found that the best models outperformed the best human chemists in our study on average. The models, however, struggle with some chemical reasoning tasks that are easy for human experts and provide overconfident, misleading predictions, such as about chemicals' safety profiles. These findings underscore the dual reality that, although LLMs demonstrate remarkable proficiency in chemical tasks, further research is critical to enhancing their safety and utility in chemical sciences. Our findings also indicate a need for adaptations to chemistry curricula and highlight the importance of continuing to develop evaluation frameworks to improve safe and useful LLMs.
Stable LM 2 1.6B Technical Report
Feb 27, 2024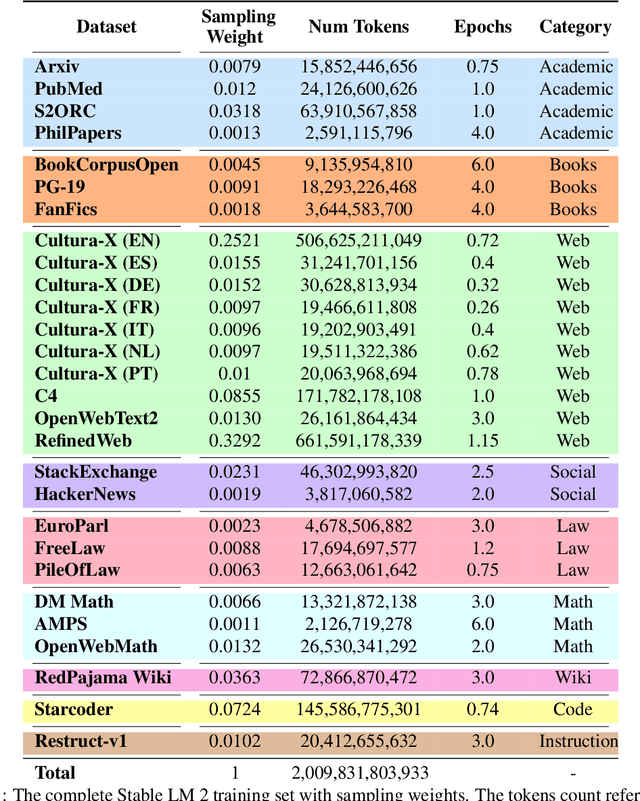
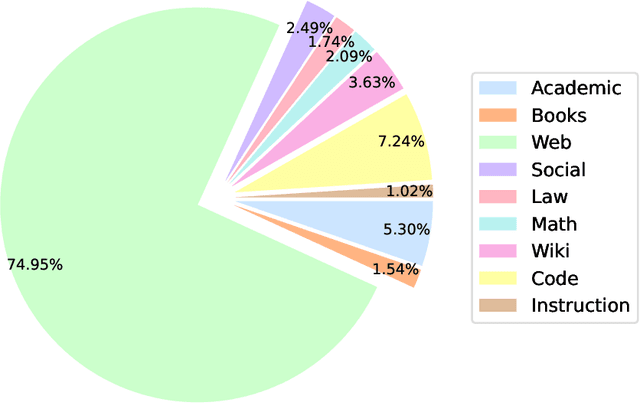
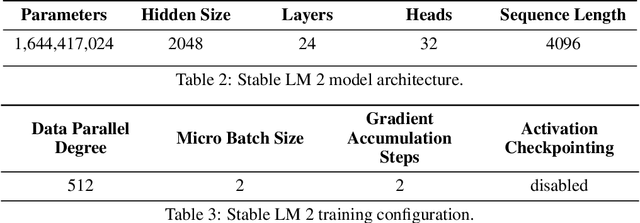
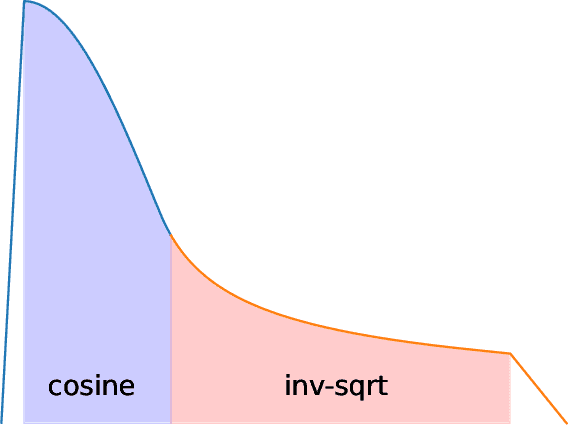
We introduce StableLM 2 1.6B, the first in a new generation of our language model series. In this technical report, we present in detail the data and training procedure leading to the base and instruction-tuned versions of StableLM 2 1.6B. The weights for both models are available via Hugging Face for anyone to download and use. The report contains thorough evaluations of these models, including zero- and few-shot benchmarks, multilingual benchmarks, and the MT benchmark focusing on multi-turn dialogues. At the time of publishing this report, StableLM 2 1.6B was the state-of-the-art open model under 2B parameters by a significant margin. Given its appealing small size, we also provide throughput measurements on a number of edge devices. In addition, we open source several quantized checkpoints and provide their performance metrics compared to the original model.
Inverse Scaling: When Bigger Isn't Better
Jun 15, 2023



Work on scaling laws has found that large language models (LMs) show predictable improvements to overall loss with increased scale (model size, training data, and compute). Here, we present evidence for the claim that LMs may show inverse scaling, or worse task performance with increased scale, e.g., due to flaws in the training objective and data. We present empirical evidence of inverse scaling on 11 datasets collected by running a public contest, the Inverse Scaling Prize, with a substantial prize pool. Through analysis of the datasets, along with other examples found in the literature, we identify four potential causes of inverse scaling: (i) preference to repeat memorized sequences over following in-context instructions, (ii) imitation of undesirable patterns in the training data, (iii) tasks containing an easy distractor task which LMs could focus on, rather than the harder real task, and (iv) correct but misleading few-shot demonstrations of the task. We release the winning datasets at https://inversescaling.com/data to allow for further investigation of inverse scaling. Our tasks have helped drive the discovery of U-shaped and inverted-U scaling trends, where an initial trend reverses, suggesting that scaling trends are less reliable at predicting the behavior of larger-scale models than previously understood. Overall, our results suggest that there are tasks for which increased model scale alone may not lead to progress, and that more careful thought needs to go into the data and objectives for training language models.
14 Examples of How LLMs Can Transform Materials Science and Chemistry: A Reflection on a Large Language Model Hackathon
Jun 13, 2023



Chemistry and materials science are complex. Recently, there have been great successes in addressing this complexity using data-driven or computational techniques. Yet, the necessity of input structured in very specific forms and the fact that there is an ever-growing number of tools creates usability and accessibility challenges. Coupled with the reality that much data in these disciplines is unstructured, the effectiveness of these tools is limited. Motivated by recent works that indicated that large language models (LLMs) might help address some of these issues, we organized a hackathon event on the applications of LLMs in chemistry, materials science, and beyond. This article chronicles the projects built as part of this hackathon. Participants employed LLMs for various applications, including predicting properties of molecules and materials, designing novel interfaces for tools, extracting knowledge from unstructured data, and developing new educational applications. The diverse topics and the fact that working prototypes could be generated in less than two days highlight that LLMs will profoundly impact the future of our fields. The rich collection of ideas and projects also indicates that the applications of LLMs are not limited to materials science and chemistry but offer potential benefits to a wide range of scientific disciplines.
Robust Preference Learning for Storytelling via Contrastive Reinforcement Learning
Oct 14, 2022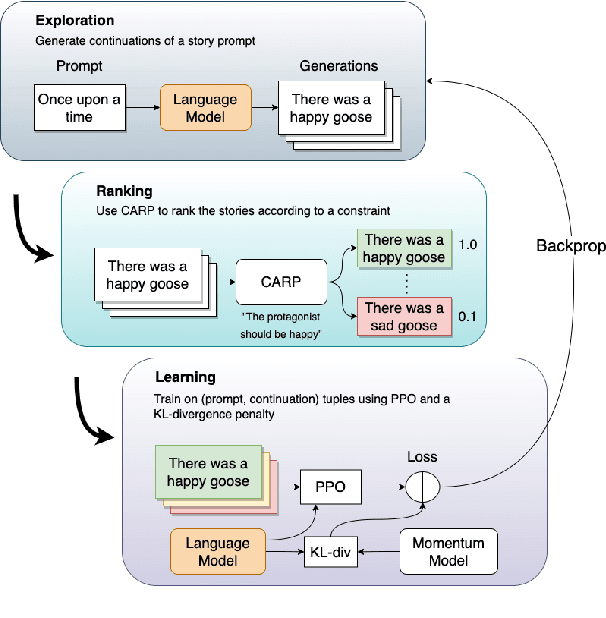

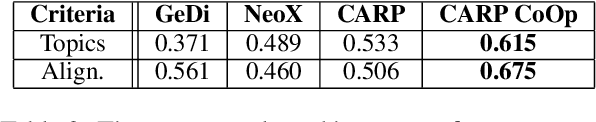
Controlled automated story generation seeks to generate natural language stories satisfying constraints from natural language critiques or preferences. Existing methods to control for story preference utilize prompt engineering which is labor intensive and often inconsistent. They may also use logit-manipulation methods which require annotated datasets to exist for the desired attributes. To address these issues, we first train a contrastive bi-encoder model to align stories with corresponding human critiques, named CARP, building a general purpose preference model. This is subsequently used as a reward function to fine-tune a generative language model via reinforcement learning. However, simply fine-tuning a generative language model with a contrastive reward model does not always reliably result in a story generation system capable of generating stories that meet user preferences. To increase story generation robustness we further fine-tune the contrastive reward model using a prompt-learning technique. A human participant study is then conducted comparing generations from our full system, ablations, and two baselines. We show that the full fine-tuning pipeline results in a story generator preferred over a LLM 20x as large as well as logit-based methods. This motivates the use of contrastive learning for general purpose human preference modeling.
Few-shot Adaptation Works with UnpredicTable Data
Aug 08, 2022
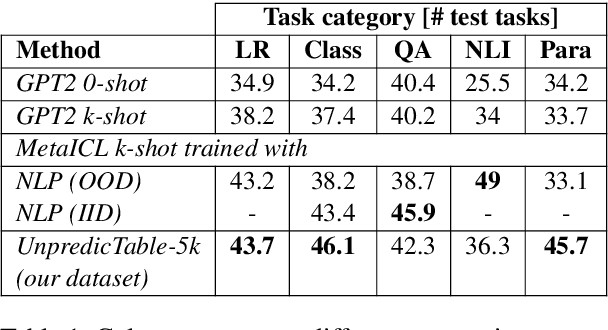
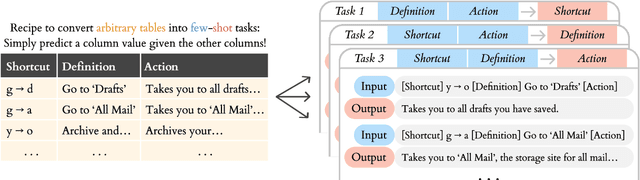

Prior work on language models (LMs) shows that training on a large number of diverse tasks improves few-shot learning (FSL) performance on new tasks. We take this to the extreme, automatically extracting 413,299 tasks from internet tables - orders of magnitude more than the next-largest public datasets. Finetuning on the resulting dataset leads to improved FSL performance on Natural Language Processing (NLP) tasks, but not proportionally to dataset scale. In fact, we find that narrow subsets of our dataset sometimes outperform more diverse datasets. For example, finetuning on software documentation from support.google.com raises FSL performance by a mean of +7.5% on 52 downstream tasks, which beats training on 40 human-curated NLP datasets (+6.7%). Finetuning on various narrow datasets leads to similar broad improvements across test tasks, suggesting that the gains are not from domain adaptation but adapting to FSL in general. We do not observe clear patterns between the datasets that lead to FSL gains, leaving open questions about why certain data helps with FSL.
GPT-NeoX-20B: An Open-Source Autoregressive Language Model
Apr 14, 2022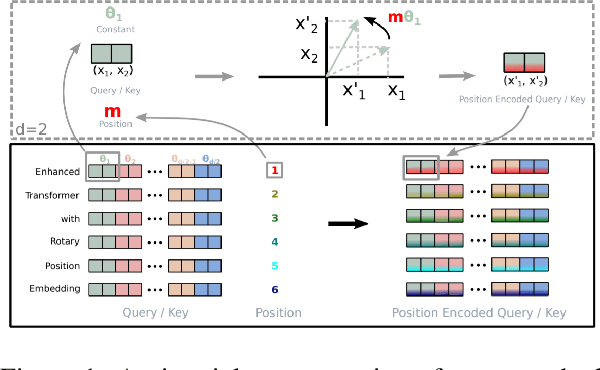
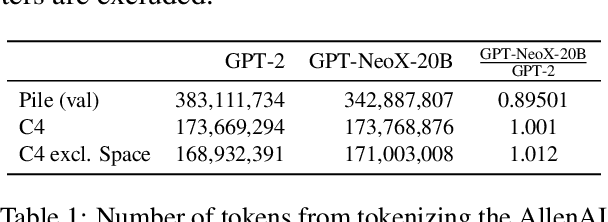
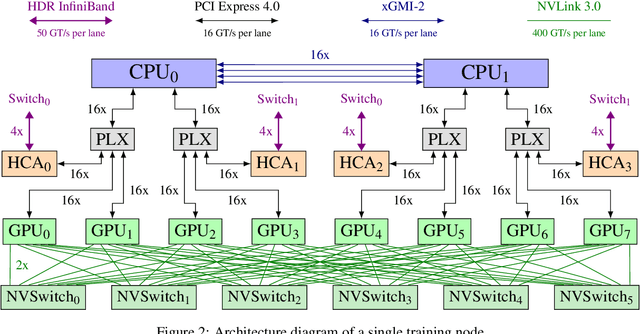

We introduce GPT-NeoX-20B, a 20 billion parameter autoregressive language model trained on the Pile, whose weights will be made freely and openly available to the public through a permissive license. It is, to the best of our knowledge, the largest dense autoregressive model that has publicly available weights at the time of submission. In this work, we describe \model{}'s architecture and training and evaluate its performance on a range of language-understanding, mathematics, and knowledge-based tasks. We find that GPT-NeoX-20B is a particularly powerful few-shot reasoner and gains far more in performance when evaluated five-shot than similarly sized GPT-3 and FairSeq models. We open-source the training and evaluation code, as well as the model weights, at https://github.com/EleutherAI/gpt-neox.