 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-Sora 2.0: Training a Commercial-Level Video Generation Model in $200k
Mar 12, 2025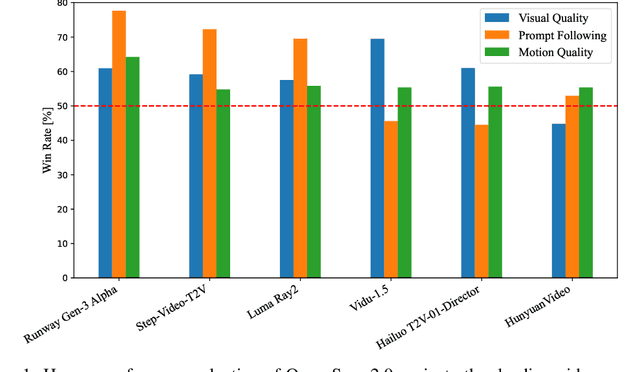

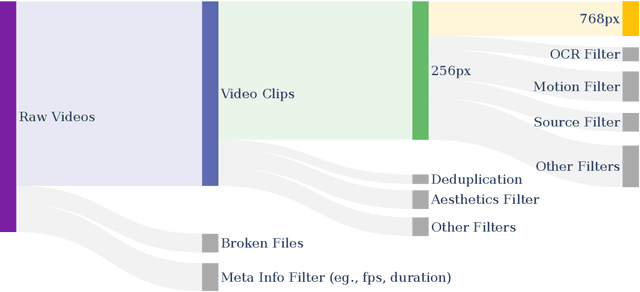

Video generation models have achieved remarkable progress in the past year. The quality of AI video continues to improve, but at the cost of larger model size, increased data quantity, and greater demand for training compute. In this report, we present Open-Sora 2.0, a commercial-level video generation model trained for only $200k. With this model, we demonstrate that the cost of training a top-performing video generation model is highly controllable. We detail all techniques that contribute to this efficiency breakthrough, including data curation, model architecture, training strategy, and system optimization. According to human evaluation results and VBench scores, Open-Sora 2.0 is comparable to global leading video generation models including the open-source HunyuanVideo and the closed-source Runway Gen-3 Alpha. By making Open-Sora 2.0 fully open-source, we aim to democratize access to advanced video generation technology, fostering broader innovation and creativity in content creation. All resources are publicly available at: https://github.com/hpcaitech/Open-Sora.
SOP-Agent: Empower General Purpose AI Agent with Domain-Specific SOPs
Jan 16, 2025


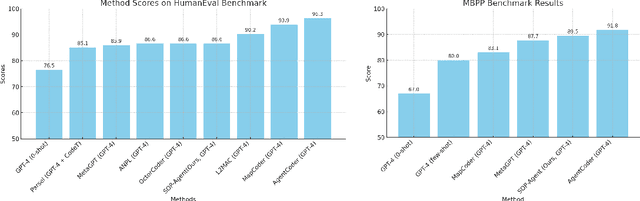
Despite significant advancements in general-purpose AI agents, several challenges still hinder their practical application in real-world scenarios. First, the limited planning capabilities of Large Language Models (LLM) restrict AI agents from effectively solving complex tasks that require long-horizon planning. Second, general-purpose AI agents struggle to efficiently utilize domain-specific knowledge and human expertise. In this paper, we introduce the Standard Operational Procedure-guided Agent (SOP-agent), a novel framework for constructing domain-specific agents through pseudocode-style Standard Operational Procedures (SOPs) written in natural language. Formally, we represent a SOP as a decision graph, which is traversed to guide the agent in completing tasks specified by the SOP. We conduct extensive experiments across tasks in multiple domains, including decision-making, search and reasoning, code generation, data cleaning, and grounded customer service. The SOP-agent demonstrates excellent versatility, achieving performance superior to general-purpose agent frameworks and comparable to domain-specific agent systems. Additionally, we introduce the Grounded Customer Service Benchmark, the first benchmark designed to evaluate the grounded decision-making capabilities of AI agents in customer service scenarios based on SOPs.
Neural Story Planning
Dec 16, 2022



Automated plot generation is the challenge of generating a sequence of events that will be perceived by readers as the plot of a coherent story. Traditional symbolic planners plan a story from a goal state and guarantee logical causal plot coherence but rely on a library of hand-crafted actions with their preconditions and effects. This closed world setting limits the length and diversity of what symbolic planners can generate. On the other hand, pre-trained neural language models can generate stories with great diversity, while being generally incapable of ending a story in a specified manner and can have trouble maintaining coherence. In this paper, we present an approach to story plot generation that unifies causal planning with neural language models. We propose to use commonsense knowledge extracted from large language models to recursively expand a story plot in a backward chaining fashion. Specifically, our system infers the preconditions for events in the story and then events that will cause those conditions to become true. We performed automatic evaluation to measure narrative coherence as indicated by the ability to answer questions about whether different events in the story are causally related to other events. Results indicate that our proposed method produces more coherent plotlines than several strong baselines.
Robust Preference Learning for Storytelling via Contrastive Reinforcement Learning
Oct 14, 2022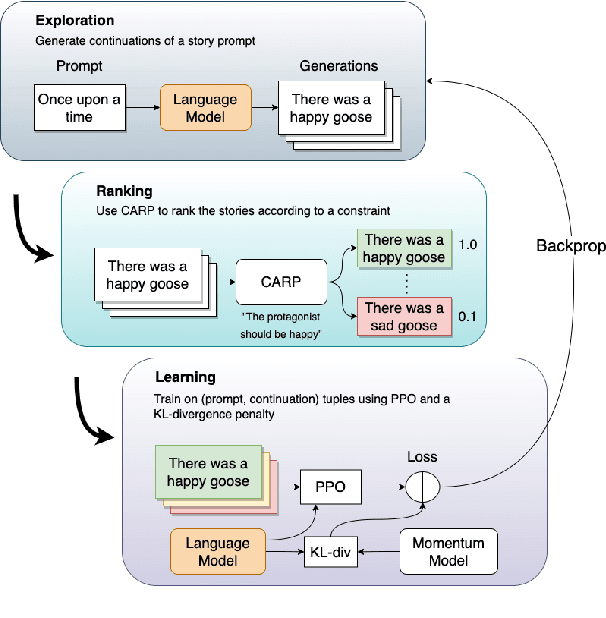

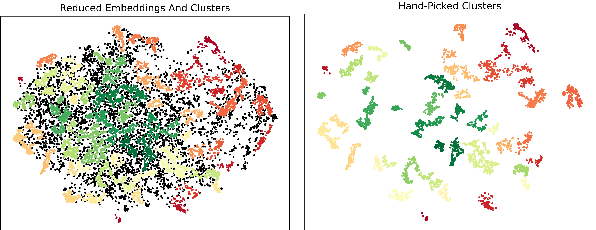
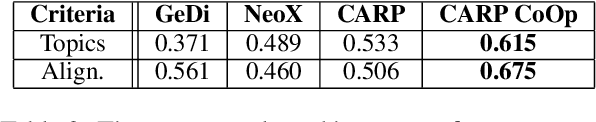
Controlled automated story generation seeks to generate natural language stories satisfying constraints from natural language critiques or preferences. Existing methods to control for story preference utilize prompt engineering which is labor intensive and often inconsistent. They may also use logit-manipulation methods which require annotated datasets to exist for the desired attributes. To address these issues, we first train a contrastive bi-encoder model to align stories with corresponding human critiques, named CARP, building a general purpose preference model. This is subsequently used as a reward function to fine-tune a generative language model via reinforcement learning. However, simply fine-tuning a generative language model with a contrastive reward model does not always reliably result in a story generation system capable of generating stories that meet user preferences. To increase story generation robustness we further fine-tune the contrastive reward model using a prompt-learning technique. A human participant study is then conducted comparing generations from our full system, ablations, and two baselines. We show that the full fine-tuning pipeline results in a story generator preferred over a LLM 20x as large as well as logit-based methods. This motivates the use of contrastive learning for general purpose human preference modeling.