 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSOP-Agent: Empower General Purpose AI Agent with Domain-Specific SOPs
Jan 16, 2025


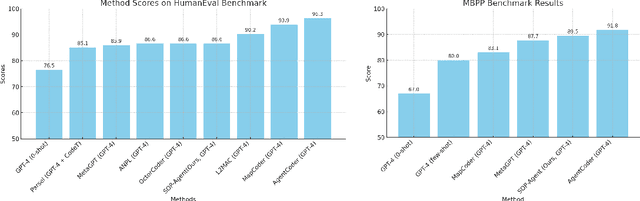
Despite significant advancements in general-purpose AI agents, several challenges still hinder their practical application in real-world scenarios. First, the limited planning capabilities of Large Language Models (LLM) restrict AI agents from effectively solving complex tasks that require long-horizon planning. Second, general-purpose AI agents struggle to efficiently utilize domain-specific knowledge and human expertise. In this paper, we introduce the Standard Operational Procedure-guided Agent (SOP-agent), a novel framework for constructing domain-specific agents through pseudocode-style Standard Operational Procedures (SOPs) written in natural language. Formally, we represent a SOP as a decision graph, which is traversed to guide the agent in completing tasks specified by the SOP. We conduct extensive experiments across tasks in multiple domains, including decision-making, search and reasoning, code generation, data cleaning, and grounded customer service. The SOP-agent demonstrates excellent versatility, achieving performance superior to general-purpose agent frameworks and comparable to domain-specific agent systems. Additionally, we introduce the Grounded Customer Service Benchmark, the first benchmark designed to evaluate the grounded decision-making capabilities of AI agents in customer service scenarios based on SOPs.
Towards Efficient and Scalable Sharpness-Aware Minimization
Mar 05, 2022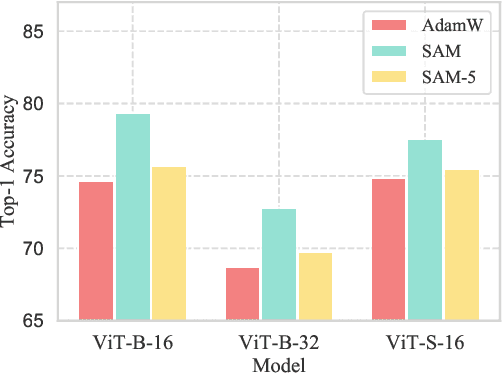

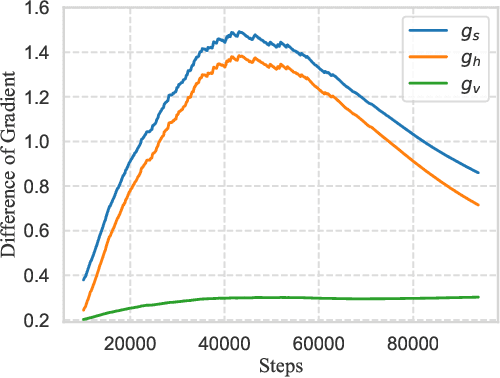

Recently, Sharpness-Aware Minimization (SAM), which connects the geometry of the loss landscape and generalization, has demonstrated significant performance boosts on training large-scale models such as vision transformers. However, the update rule of SAM requires two sequential (non-parallelizable) gradient computations at each step, which can double the computational overhead. In this paper, we propose a novel algorithm LookSAM - that only periodically calculates the inner gradient ascent, to significantly reduce the additional training cost of SAM. The empirical results illustrate that LookSAM achieves similar accuracy gains to SAM while being tremendously faster - it enjoys comparable computational complexity with first-order optimizers such as SGD or Adam. To further evaluate the performance and scalability of LookSAM, we incorporate a layer-wise modification and perform experiments in the large-batch training scenario, which is more prone to converge to sharp local minima. We are the first to successfully scale up the batch size when training Vision Transformers (ViTs). With a 64k batch size, we are able to train ViTs from scratch in minutes while maintaining competitive performance.