 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChameleon: Episodic Memory for Long-Horizon Robotic Manipulation
Mar 25, 2026Robotic manipulation often requires memory: occlusion and state changes can make decision-time observations perceptually aliased, making action selection non-Markovian at the observation level because the same observation may arise from different interaction histories. Most embodied agents implement memory via semantically compressed traces and similarity-based retrieval, which discards disambiguating fine-grained perceptual cues and can return perceptually similar but decision-irrelevant episodes. Inspired by human episodic memory, we propose Chameleon, which writes geometry-grounded multimodal tokens to preserve disambiguating context and produces goal-directed recall through a differentiable memory stack. We also introduce Camo-Dataset, a real-robot UR5e dataset spanning episodic recall, spatial tracking, and sequential manipulation under perceptual aliasing. Across tasks, Chameleon consistently improves decision reliability and long-horizon control over strong baselines in perceptually confusable settings.
Action-to-Action Flow Matching
Feb 07, 2026Diffusion-based policies have recently achieved remarkable success in robotics by formulating action prediction as a conditional denoising process. However, the standard practice of sampling from random Gaussian noise often requires multiple iterative steps to produce clean actions, leading to high inference latency that incurs a major bottleneck for real-time control. In this paper, we challenge the necessity of uninformed noise sampling and propose Action-to-Action flow matching (A2A), a novel policy paradigm that shifts from random sampling to initialization informed by the previous action. Unlike existing methods that treat proprioceptive action feedback as static conditions, A2A leverages historical proprioceptive sequences, embedding them into a high-dimensional latent space as the starting point for action generation. This design bypasses costly iterative denoising while effectively capturing the robot's physical dynamics and temporal continuity. Extensive experiments demonstrate that A2A exhibits high training efficiency, fast inference speed, and improved generalization. Notably, A2A enables high-quality action generation in as few as a single inference step (0.56 ms latency), and exhibits superior robustness to visual perturbations and enhanced generalization to unseen configurations. Lastly, we also extend A2A to video generation, demonstrating its broader versatility in temporal modeling. Project site: https://lorenzo-0-0.github.io/A2A_Flow_Matching.
Open-Sora 2.0: Training a Commercial-Level Video Generation Model in $200k
Mar 12, 2025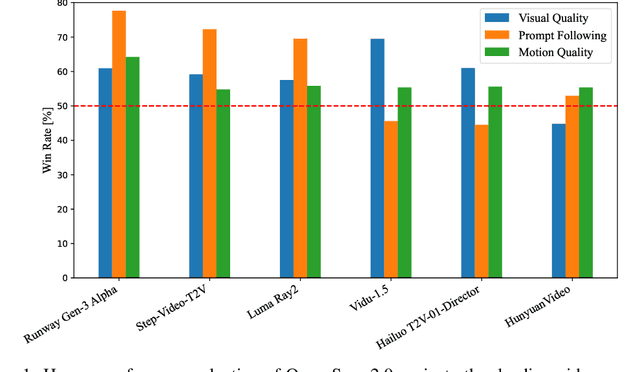

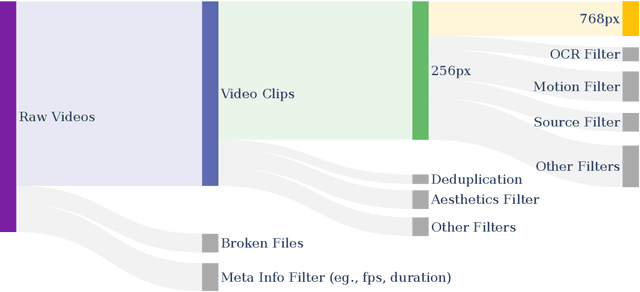

Video generation models have achieved remarkable progress in the past year. The quality of AI video continues to improve, but at the cost of larger model size, increased data quantity, and greater demand for training compute. In this report, we present Open-Sora 2.0, a commercial-level video generation model trained for only $200k. With this model, we demonstrate that the cost of training a top-performing video generation model is highly controllable. We detail all techniques that contribute to this efficiency breakthrough, including data curation, model architecture, training strategy, and system optimization. According to human evaluation results and VBench scores, Open-Sora 2.0 is comparable to global leading video generation models including the open-source HunyuanVideo and the closed-source Runway Gen-3 Alpha. By making Open-Sora 2.0 fully open-source, we aim to democratize access to advanced video generation technology, fostering broader innovation and creativity in content creation. All resources are publicly available at: https://github.com/hpcaitech/Open-Sora.
CrowdMoGen: Zero-Shot Text-Driven Collective Motion Generation
Jul 08, 2024



Crowd Motion Generation is essential in entertainment industries such as animation and games as well as in strategic fields like urban simulation and planning. This new task requires an intricate integration of control and generation to realistically synthesize crowd dynamics under specific spatial and semantic constraints, whose challenges are yet to be fully explored. On the one hand, existing human motion generation models typically focus on individual behaviors, neglecting the complexities of collective behaviors. On the other hand, recent methods for multi-person motion generation depend heavily on pre-defined scenarios and are limited to a fixed, small number of inter-person interactions, thus hampering their practicality. To overcome these challenges, we introduce CrowdMoGen, a zero-shot text-driven framework that harnesses the power of Large Language Model (LLM) to incorporate the collective intelligence into the motion generation framework as guidance, thereby enabling generalizable planning and generation of crowd motions without paired training data. Our framework consists of two key components: 1) Crowd Scene Planner that learns to coordinate motions and dynamics according to specific scene contexts or introduced perturbations, and 2) Collective Motion Generator that efficiently synthesizes the required collective motions based on the holistic plans. Extensive quantitative and qualitative experiments have validated the effectiveness of our framework, which not only fills a critical gap by providing scalable and generalizable solutions for Crowd Motion Generation task but also achieves high levels of realism and flexibility.
Large Motion Model for Unified Multi-Modal Motion Generation
Apr 01, 2024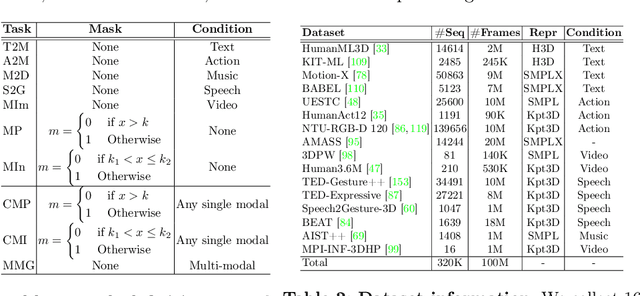
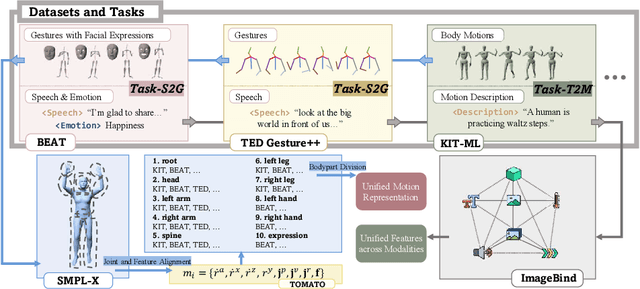
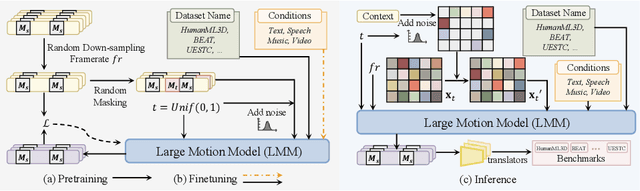
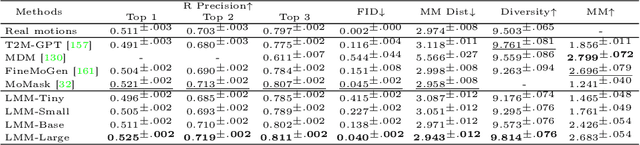
Human motion generation, a cornerstone technique in animation and video production, has widespread applications in various tasks like text-to-motion and music-to-dance. Previous works focus on developing specialist models tailored for each task without scalability. In this work, we present Large Motion Model (LMM), a motion-centric, multi-modal framework that unifies mainstream motion generation tasks into a generalist model. A unified motion model is appealing since it can leverage a wide range of motion data to achieve broad generalization beyond a single task. However, it is also challenging due to the heterogeneous nature of substantially different motion data and tasks. LMM tackles these challenges from three principled aspects: 1) Data: We consolidate datasets with different modalities, formats and tasks into a comprehensive yet unified motion generation dataset, MotionVerse, comprising 10 tasks, 16 datasets, a total of 320k sequences, and 100 million frames. 2) Architecture: We design an articulated attention mechanism ArtAttention that incorporates body part-aware modeling into Diffusion Transformer backbone. 3) Pre-Training: We propose a novel pre-training strategy for LMM, which employs variable frame rates and masking forms, to better exploit knowledge from diverse training data. Extensive experiments demonstrate that our generalist LMM achieves competitive performance across various standard motion generation tasks over state-of-the-art specialist models. Notably, LMM exhibits strong generalization capabilities and emerging properties across many unseen tasks. Additionally, our ablation studies reveal valuable insights about training and scaling up large motion models for future research.
Digital Life Project: Autonomous 3D Characters with Social Intelligence
Dec 07, 2023



In this work, we present Digital Life Project, a framework utilizing language as the universal medium to build autonomous 3D characters, who are capable of engaging in social interactions and expressing with articulated body motions, thereby simulating life in a digital environment. Our framework comprises two primary components: 1) SocioMind: a meticulously crafted digital brain that models personalities with systematic few-shot exemplars, incorporates a reflection process based on psychology principles, and emulates autonomy by initiating dialogue topics; 2) MoMat-MoGen: a text-driven motion synthesis paradigm for controlling the character's digital body. It integrates motion matching, a proven industry technique to ensure motion quality, with cutting-edge advancements in motion generation for diversity. Extensive experiments demonstrate that each module achieves state-of-the-art performance in its respective domain. Collectively, they enable virtual characters to initiate and sustain dialogues autonomously, while evolving their socio-psychological states. Concurrently, these characters can perform contextually relevant bodily movements. Additionally, a motion captioning module further allows the virtual character to recognize and appropriately respond to human players' actions. Homepage: https://digital-life-project.com/
ReMoDiffuse: Retrieval-Augmented Motion Diffusion Model
Apr 03, 20233D human motion generation is crucial for creative industry. Recent advances rely on generative models with domain knowledge for text-driven motion generation, leading to substantial progress in capturing common motions. However, the performance on more diverse motions remains unsatisfactory. In this work, we propose ReMoDiffuse, a diffusion-model-based motion generation framework that integrates a retrieval mechanism to refine the denoising process. ReMoDiffuse enhances the generalizability and diversity of text-driven motion generation with three key designs: 1) Hybrid Retrieval finds appropriate references from the database in terms of both semantic and kinematic similarities. 2) Semantic-Modulated Transformer selectively absorbs retrieval knowledge, adapting to the difference between retrieved samples and the target motion sequence. 3) Condition Mixture better utilizes the retrieval database during inference, overcoming the scale sensitivity in classifier-free guidance. Extensive experiments demonstrate that ReMoDiffuse outperforms state-of-the-art methods by balancing both text-motion consistency and motion quality, especially for more diverse motion generation.
MotionDiffuse: Text-Driven Human Motion Generation with Diffusion Model
Aug 31, 2022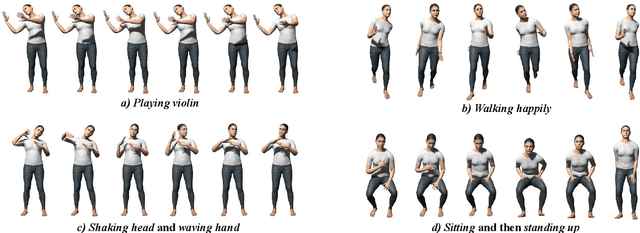

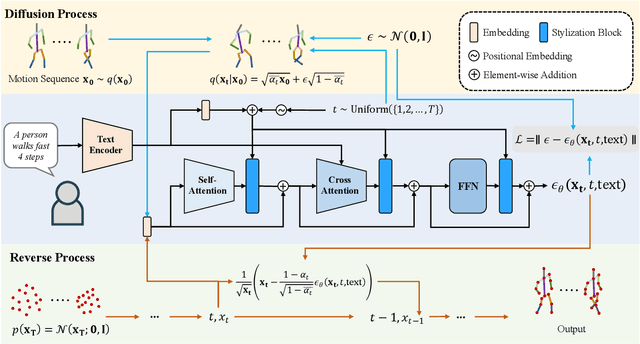

Human motion modeling is important for many modern graphics applications, which typically require professional skills. In order to remove the skill barriers for laymen, recent motion generation methods can directly generate human motions conditioned on natural languages. However, it remains challenging to achieve diverse and fine-grained motion generation with various text inputs. To address this problem, we propose MotionDiffuse, the first diffusion model-based text-driven motion generation framework, which demonstrates several desired properties over existing methods. 1) Probabilistic Mapping. Instead of a deterministic language-motion mapping, MotionDiffuse generates motions through a series of denoising steps in which variations are injected. 2) Realistic Synthesis. MotionDiffuse excels at modeling complicated data distribution and generating vivid motion sequences. 3) Multi-Level Manipulation. MotionDiffuse responds to fine-grained instructions on body parts, and arbitrary-length motion synthesis with time-varied text prompts. Our experiments show MotionDiffuse outperforms existing SoTA methods by convincing margins on text-driven motion generation and action-conditioned motion generation. A qualitative analysis further demonstrates MotionDiffuse's controllability for comprehensive motion generation. Homepage: https://mingyuan-zhang.github.io/projects/MotionDiffuse.html