 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDigital Life Project: Autonomous 3D Characters with Social Intelligence
Dec 07, 2023



In this work, we present Digital Life Project, a framework utilizing language as the universal medium to build autonomous 3D characters, who are capable of engaging in social interactions and expressing with articulated body motions, thereby simulating life in a digital environment. Our framework comprises two primary components: 1) SocioMind: a meticulously crafted digital brain that models personalities with systematic few-shot exemplars, incorporates a reflection process based on psychology principles, and emulates autonomy by initiating dialogue topics; 2) MoMat-MoGen: a text-driven motion synthesis paradigm for controlling the character's digital body. It integrates motion matching, a proven industry technique to ensure motion quality, with cutting-edge advancements in motion generation for diversity. Extensive experiments demonstrate that each module achieves state-of-the-art performance in its respective domain. Collectively, they enable virtual characters to initiate and sustain dialogues autonomously, while evolving their socio-psychological states. Concurrently, these characters can perform contextually relevant bodily movements. Additionally, a motion captioning module further allows the virtual character to recognize and appropriately respond to human players' actions. Homepage: https://digital-life-project.com/
Story-to-Motion: Synthesizing Infinite and Controllable Character Animation from Long Text
Nov 13, 2023Generating natural human motion from a story has the potential to transform the landscape of animation, gaming, and film industries. A new and challenging task, Story-to-Motion, arises when characters are required to move to various locations and perform specific motions based on a long text description. This task demands a fusion of low-level control (trajectories) and high-level control (motion semantics). Previous works in character control and text-to-motion have addressed related aspects, yet a comprehensive solution remains elusive: character control methods do not handle text description, whereas text-to-motion methods lack position constraints and often produce unstable motions. In light of these limitations, we propose a novel system that generates controllable, infinitely long motions and trajectories aligned with the input text. (1) We leverage contemporary Large Language Models to act as a text-driven motion scheduler to extract a series of (text, position, duration) pairs from long text. (2) We develop a text-driven motion retrieval scheme that incorporates motion matching with motion semantic and trajectory constraints. (3) We design a progressive mask transformer that addresses common artifacts in the transition motion such as unnatural pose and foot sliding. Beyond its pioneering role as the first comprehensive solution for Story-to-Motion, our system undergoes evaluation across three distinct sub-tasks: trajectory following, temporal action composition, and motion blending, where it outperforms previous state-of-the-art motion synthesis methods across the board. Homepage: https://story2motion.github.io/.
SynBody: Synthetic Dataset with Layered Human Models for 3D Human Perception and Modeling
Mar 30, 2023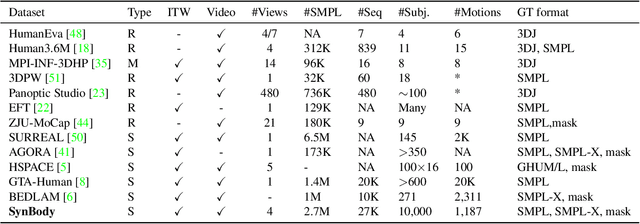
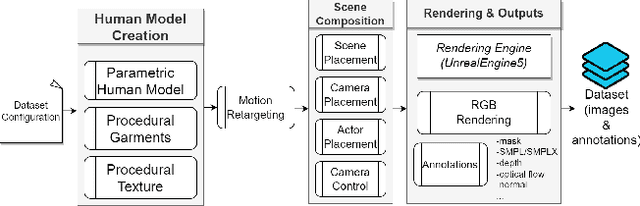
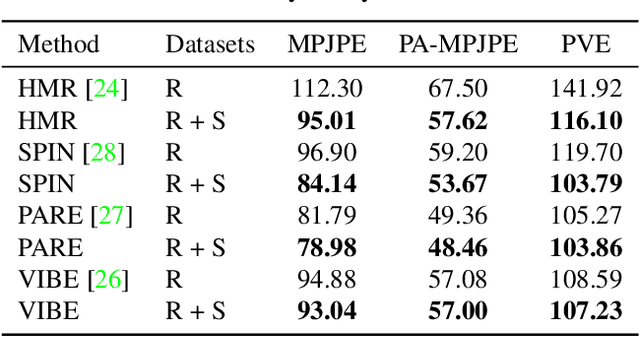
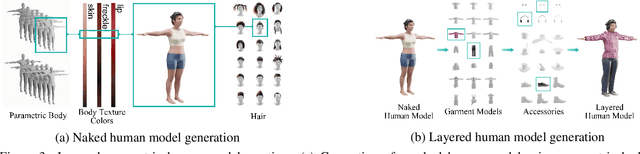
Synthetic data has emerged as a promising source for 3D human research as it offers low-cost access to large-scale human datasets. To advance the diversity and annotation quality of human models, we introduce a new synthetic dataset, Synbody, with three appealing features: 1) a clothed parametric human model that can generate a diverse range of subjects; 2) the layered human representation that naturally offers high-quality 3D annotations to support multiple tasks; 3) a scalable system for producing realistic data to facilitate real-world tasks. The dataset comprises 1.7M images with corresponding accurate 3D annotations, covering 10,000 human body models, 1000 actions, and various viewpoints. The dataset includes two subsets for human mesh recovery as well as human neural rendering. Extensive experiments on SynBody indicate that it substantially enhances both SMPL and SMPL-X estimation. Furthermore, the incorporation of layered annotations offers a valuable training resource for investigating the Human Neural Radiance Fields (NeRF).