 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMPLest-X: Ultimate Scaling for Expressive Human Pose and Shape Estimation
Jan 16, 2025Expressive human pose and shape estimation (EHPS) unifies body, hands, and face motion capture with numerous applications. Despite encouraging progress, current state-of-the-art methods focus on training innovative architectural designs on confined datasets. In this work, we investigate the impact of scaling up EHPS towards a family of generalist foundation models. 1) For data scaling, we perform a systematic investigation on 40 EHPS datasets, encompassing a wide range of scenarios that a model trained on any single dataset cannot handle. More importantly, capitalizing on insights obtained from the extensive benchmarking process, we optimize our training scheme and select datasets that lead to a significant leap in EHPS capabilities. Ultimately, we achieve diminishing returns at 10M training instances from diverse data sources. 2) For model scaling, we take advantage of vision transformers (up to ViT-Huge as the backbone) to study the scaling law of model sizes in EHPS. To exclude the influence of algorithmic design, we base our experiments on two minimalist architectures: SMPLer-X, which consists of an intermediate step for hand and face localization, and SMPLest-X, an even simpler version that reduces the network to its bare essentials and highlights significant advances in the capture of articulated hands. With big data and the large model, the foundation models exhibit strong performance across diverse test benchmarks and excellent transferability to even unseen environments. Moreover, our finetuning strategy turns the generalist into specialist models, allowing them to achieve further performance boosts. Notably, our foundation models consistently deliver state-of-the-art results on seven benchmarks such as AGORA, UBody, EgoBody, and our proposed SynHand dataset for comprehensive hand evaluation. (Code is available at: https://github.com/wqyin/SMPLest-X).
Differentiable Convex Polyhedra Optimization from Multi-view Images
Jul 22, 2024This paper presents a novel approach for the differentiable rendering of convex polyhedra, addressing the limitations of recent methods that rely on implicit field supervision. Our technique introduces a strategy that combines non-differentiable computation of hyperplane intersection through duality transform with differentiable optimization for vertex positioning with three-plane intersection, enabling gradient-based optimization without the need for 3D implicit fields. This allows for efficient shape representation across a range of applications, from shape parsing to compact mesh reconstruction. This work not only overcomes the challenges of previous approaches but also sets a new standard for representing shapes with convex polyhedra.
AiOS: All-in-One-Stage Expressive Human Pose and Shape Estimation
Mar 26, 2024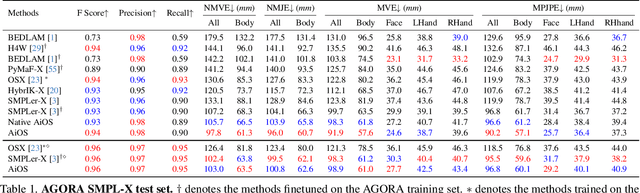
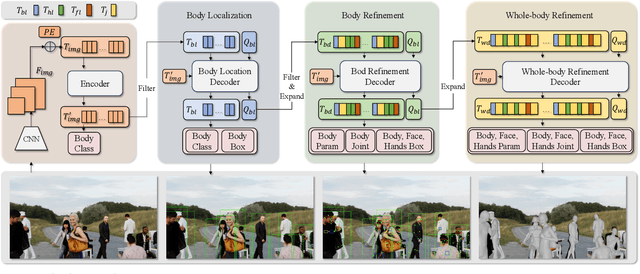
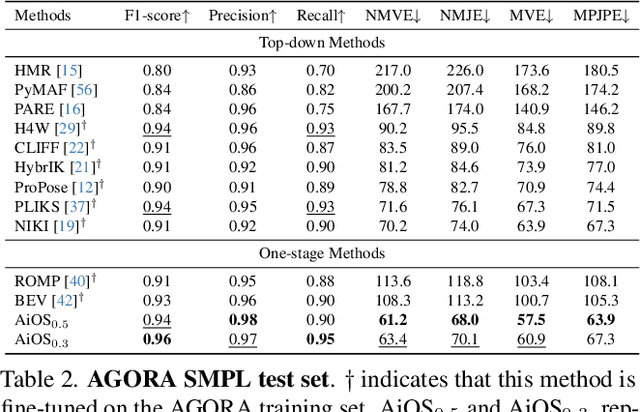
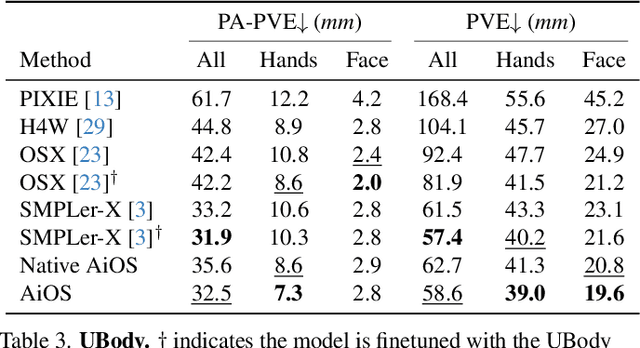
Expressive human pose and shape estimation (a.k.a. 3D whole-body mesh recovery) involves the human body, hand, and expression estimation. Most existing methods have tackled this task in a two-stage manner, first detecting the human body part with an off-the-shelf detection model and inferring the different human body parts individually. Despite the impressive results achieved, these methods suffer from 1) loss of valuable contextual information via cropping, 2) introducing distractions, and 3) lacking inter-association among different persons and body parts, inevitably causing performance degradation, especially for crowded scenes. To address these issues, we introduce a novel all-in-one-stage framework, AiOS, for multiple expressive human pose and shape recovery without an additional human detection step. Specifically, our method is built upon DETR, which treats multi-person whole-body mesh recovery task as a progressive set prediction problem with various sequential detection. We devise the decoder tokens and extend them to our task. Specifically, we first employ a human token to probe a human location in the image and encode global features for each instance, which provides a coarse location for the later transformer block. Then, we introduce a joint-related token to probe the human joint in the image and encoder a fine-grained local feature, which collaborates with the global feature to regress the whole-body mesh. This straightforward but effective model outperforms previous state-of-the-art methods by a 9% reduction in NMVE on AGORA, a 30% reduction in PVE on EHF, a 10% reduction in PVE on ARCTIC, and a 3% reduction in PVE on EgoBody.
WHAC: World-grounded Humans and Cameras
Mar 19, 2024



Estimating human and camera trajectories with accurate scale in the world coordinate system from a monocular video is a highly desirable yet challenging and ill-posed problem. In this study, we aim to recover expressive parametric human models (i.e., SMPL-X) and corresponding camera poses jointly, by leveraging the synergy between three critical players: the world, the human, and the camera. Our approach is founded on two key observations. Firstly, camera-frame SMPL-X estimation methods readily recover absolute human depth. Secondly, human motions inherently provide absolute spatial cues. By integrating these insights, we introduce a novel framework, referred to as WHAC, to facilitate world-grounded expressive human pose and shape estimation (EHPS) alongside camera pose estimation, without relying on traditional optimization techniques. Additionally, we present a new synthetic dataset, WHAC-A-Mole, which includes accurately annotated humans and cameras, and features diverse interactive human motions as well as realistic camera trajectories. Extensive experiments on both standard and newly established benchmarks highlight the superiority and efficacy of our framework. We will make the code and dataset publicly available.
Digital Life Project: Autonomous 3D Characters with Social Intelligence
Dec 07, 2023



In this work, we present Digital Life Project, a framework utilizing language as the universal medium to build autonomous 3D characters, who are capable of engaging in social interactions and expressing with articulated body motions, thereby simulating life in a digital environment. Our framework comprises two primary components: 1) SocioMind: a meticulously crafted digital brain that models personalities with systematic few-shot exemplars, incorporates a reflection process based on psychology principles, and emulates autonomy by initiating dialogue topics; 2) MoMat-MoGen: a text-driven motion synthesis paradigm for controlling the character's digital body. It integrates motion matching, a proven industry technique to ensure motion quality, with cutting-edge advancements in motion generation for diversity. Extensive experiments demonstrate that each module achieves state-of-the-art performance in its respective domain. Collectively, they enable virtual characters to initiate and sustain dialogues autonomously, while evolving their socio-psychological states. Concurrently, these characters can perform contextually relevant bodily movements. Additionally, a motion captioning module further allows the virtual character to recognize and appropriately respond to human players' actions. Homepage: https://digital-life-project.com/
PrimDiffusion: Volumetric Primitives Diffusion for 3D Human Generation
Dec 07, 2023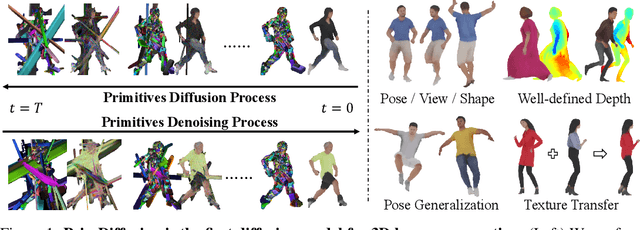

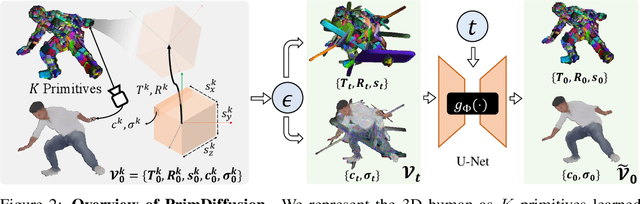

We present PrimDiffusion, the first diffusion-based framework for 3D human generation. Devising diffusion models for 3D human generation is difficult due to the intensive computational cost of 3D representations and the articulated topology of 3D humans. To tackle these challenges, our key insight is operating the denoising diffusion process directly on a set of volumetric primitives, which models the human body as a number of small volumes with radiance and kinematic information. This volumetric primitives representation marries the capacity of volumetric representations with the efficiency of primitive-based rendering. Our PrimDiffusion framework has three appealing properties: 1) compact and expressive parameter space for the diffusion model, 2) flexible 3D representation that incorporates human prior, and 3) decoder-free rendering for efficient novel-view and novel-pose synthesis. Extensive experiments validate that PrimDiffusion outperforms state-of-the-art methods in 3D human generation. Notably, compared to GAN-based methods, our PrimDiffusion supports real-time rendering of high-quality 3D humans at a resolution of $512\times512$ once the denoising process is done. We also demonstrate the flexibility of our framework on training-free conditional generation such as texture transfer and 3D inpainting.
SMPLer-X: Scaling Up Expressive Human Pose and Shape Estimation
Sep 29, 2023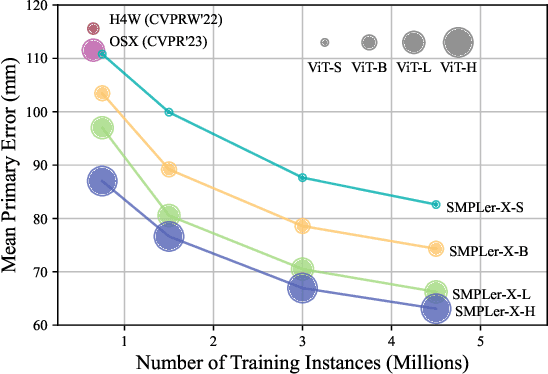
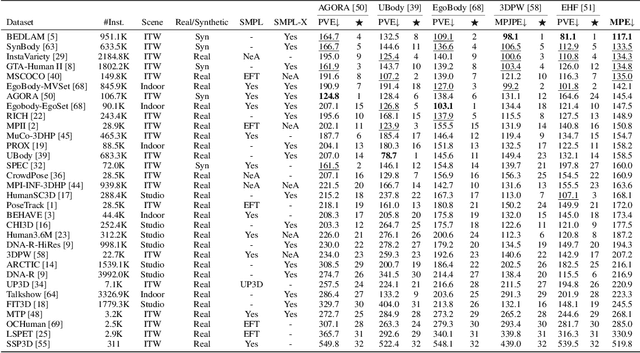
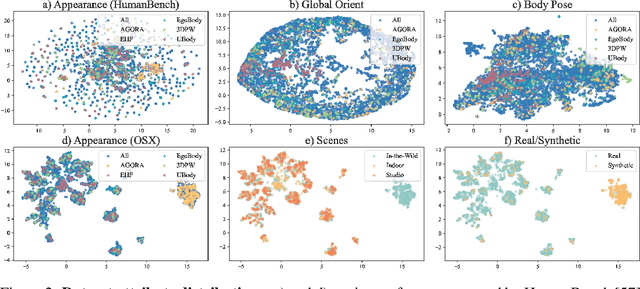
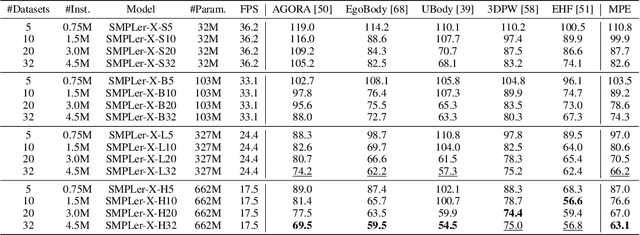
Expressive human pose and shape estimation (EHPS) unifies body, hands, and face motion capture with numerous applications. Despite encouraging progress, current state-of-the-art methods still depend largely on confined training datasets. In this work, we investigate scaling up EHPS towards the first generalist foundation model (dubbed SMPLer-X), with up to ViT-Huge as the backbone and training with up to 4.5M instances from diverse data sources. With big data and the large model, SMPLer-X exhibits strong performance across diverse test benchmarks and excellent transferability to even unseen environments. 1) For the data scaling, we perform a systematic investigation on 32 EHPS datasets, encompassing a wide range of scenarios that a model trained on any single dataset cannot handle. More importantly, capitalizing on insights obtained from the extensive benchmarking process, we optimize our training scheme and select datasets that lead to a significant leap in EHPS capabilities. 2) For the model scaling, we take advantage of vision transformers to study the scaling law of model sizes in EHPS. Moreover, our finetuning strategy turn SMPLer-X into specialist models, allowing them to achieve further performance boosts. Notably, our foundation model SMPLer-X consistently delivers state-of-the-art results on seven benchmarks such as AGORA (107.2 mm NMVE), UBody (57.4 mm PVE), EgoBody (63.6 mm PVE), and EHF (62.3 mm PVE without finetuning).
HumanLiff: Layer-wise 3D Human Generation with Diffusion Model
Aug 18, 2023



3D human generation from 2D images has achieved remarkable progress through the synergistic utilization of neural rendering and generative models. Existing 3D human generative models mainly generate a clothed 3D human as an undetectable 3D model in a single pass, while rarely considering the layer-wise nature of a clothed human body, which often consists of the human body and various clothes such as underwear, outerwear, trousers, shoes, etc. In this work, we propose HumanLiff, the first layer-wise 3D human generative model with a unified diffusion process. Specifically, HumanLiff firstly generates minimal-clothed humans, represented by tri-plane features, in a canonical space, and then progressively generates clothes in a layer-wise manner. In this way, the 3D human generation is thus formulated as a sequence of diffusion-based 3D conditional generation. To reconstruct more fine-grained 3D humans with tri-plane representation, we propose a tri-plane shift operation that splits each tri-plane into three sub-planes and shifts these sub-planes to enable feature grid subdivision. To further enhance the controllability of 3D generation with 3D layered conditions, HumanLiff hierarchically fuses tri-plane features and 3D layered conditions to facilitate the 3D diffusion model learning. Extensive experiments on two layer-wise 3D human datasets, SynBody (synthetic) and TightCap (real-world), validate that HumanLiff significantly outperforms state-of-the-art methods in layer-wise 3D human generation. Our code will be available at https://skhu101.github.io/HumanLiff.
SynBody: Synthetic Dataset with Layered Human Models for 3D Human Perception and Modeling
Mar 30, 2023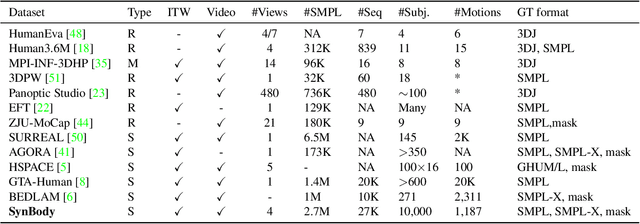
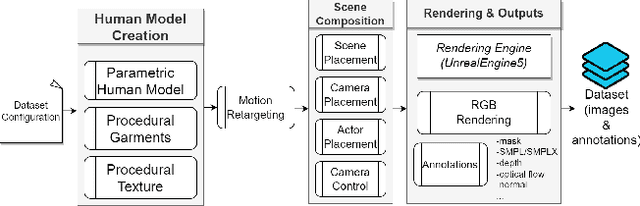
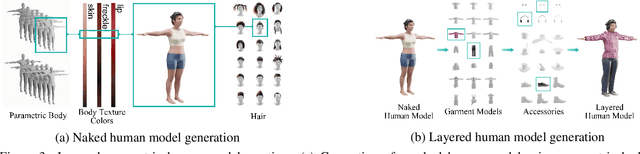
Synthetic data has emerged as a promising source for 3D human research as it offers low-cost access to large-scale human datasets. To advance the diversity and annotation quality of human models, we introduce a new synthetic dataset, Synbody, with three appealing features: 1) a clothed parametric human model that can generate a diverse range of subjects; 2) the layered human representation that naturally offers high-quality 3D annotations to support multiple tasks; 3) a scalable system for producing realistic data to facilitate real-world tasks. The dataset comprises 1.7M images with corresponding accurate 3D annotations, covering 10,000 human body models, 1000 actions, and various viewpoints. The dataset includes two subsets for human mesh recovery as well as human neural rendering. Extensive experiments on SynBody indicate that it substantially enhances both SMPL and SMPL-X estimation. Furthermore, the incorporation of layered annotations offers a valuable training resource for investigating the Human Neural Radiance Fields (NeRF).
Zolly: Zoom Focal Length Correctly for Perspective-Distorted Human Mesh Reconstruction
Mar 24, 2023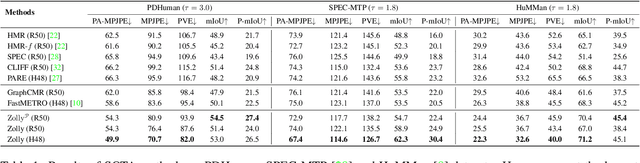
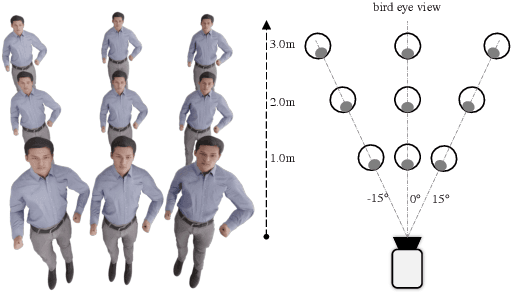
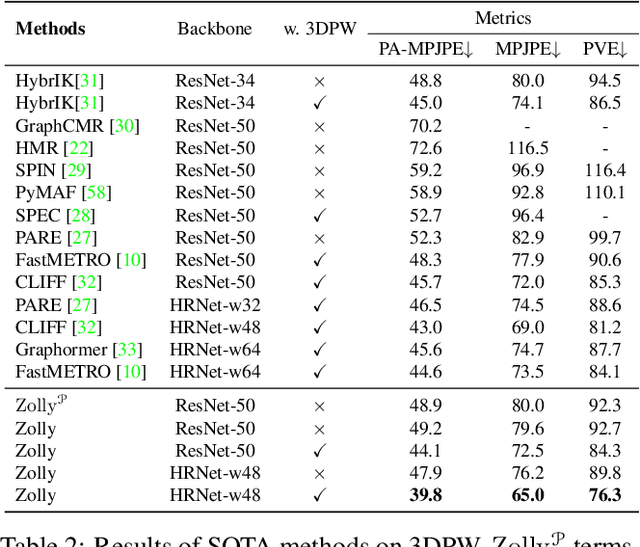
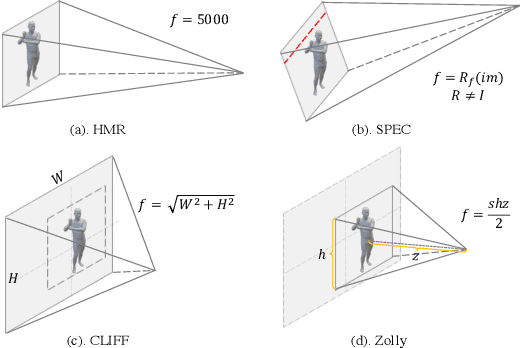
As it is hard to calibrate single-view RGB images in the wild, existing 3D human mesh reconstruction (3DHMR) methods either use a constant large focal length or estimate one based on the background environment context, which can not tackle the problem of the torso, limb, hand or face distortion caused by perspective camera projection when the camera is close to the human body. The naive focal length assumptions can harm this task with the incorrectly formulated projection matrices. To solve this, we propose Zolly, the first 3DHMR method focusing on perspective-distorted images. Our approach begins with analysing the reason for perspective distortion, which we find is mainly caused by the relative location of the human body to the camera center. We propose a new camera model and a novel 2D representation, termed distortion image, which describes the 2D dense distortion scale of the human body. We then estimate the distance from distortion scale features rather than environment context features. Afterwards, we integrate the distortion feature with image features to reconstruct the body mesh. To formulate the correct projection matrix and locate the human body position, we simultaneously use perspective and weak-perspective projection loss. Since existing datasets could not handle this task, we propose the first synthetic dataset PDHuman and extend two real-world datasets tailored for this task, all containing perspective-distorted human images. Extensive experiments show that Zolly outperforms existing state-of-the-art methods on both perspective-distorted datasets and the standard benchmark (3DPW).