 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAiOS: All-in-One-Stage Expressive Human Pose and Shape Estimation
Paper and Code
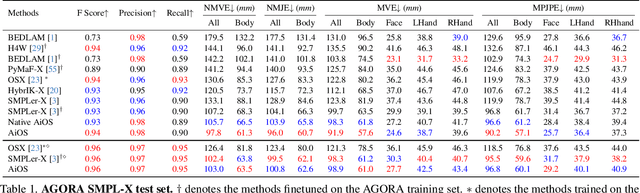
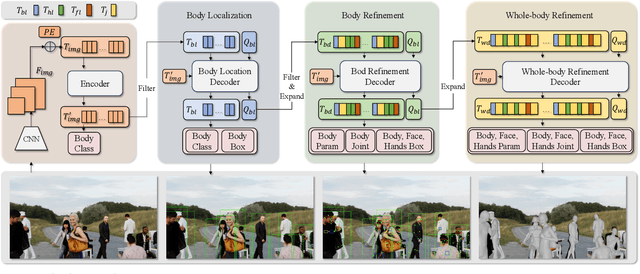
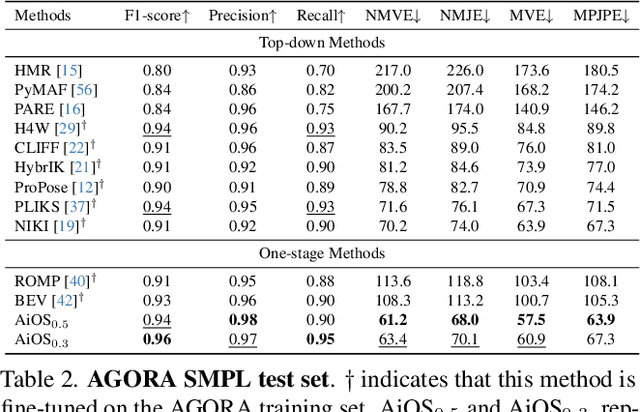
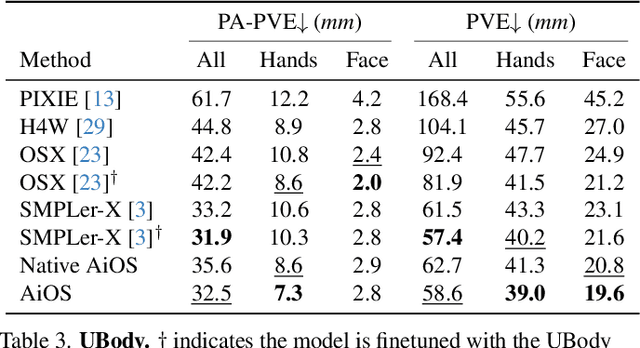
Expressive human pose and shape estimation (a.k.a. 3D whole-body mesh recovery) involves the human body, hand, and expression estimation. Most existing methods have tackled this task in a two-stage manner, first detecting the human body part with an off-the-shelf detection model and inferring the different human body parts individually. Despite the impressive results achieved, these methods suffer from 1) loss of valuable contextual information via cropping, 2) introducing distractions, and 3) lacking inter-association among different persons and body parts, inevitably causing performance degradation, especially for crowded scenes. To address these issues, we introduce a novel all-in-one-stage framework, AiOS, for multiple expressive human pose and shape recovery without an additional human detection step. Specifically, our method is built upon DETR, which treats multi-person whole-body mesh recovery task as a progressive set prediction problem with various sequential detection. We devise the decoder tokens and extend them to our task. Specifically, we first employ a human token to probe a human location in the image and encode global features for each instance, which provides a coarse location for the later transformer block. Then, we introduce a joint-related token to probe the human joint in the image and encoder a fine-grained local feature, which collaborates with the global feature to regress the whole-body mesh. This straightforward but effective model outperforms previous state-of-the-art methods by a 9% reduction in NMVE on AGORA, a 30% reduction in PVE on EHF, a 10% reduction in PVE on ARCTIC, and a 3% reduction in PVE on EgoBody.