 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSOLAMI: Social Vision-Language-Action Modeling for Immersive Interaction with 3D Autonomous Characters
Nov 29, 2024Human beings are social animals. How to equip 3D autonomous characters with similar social intelligence that can perceive, understand and interact with humans remains an open yet foundamental problem. In this paper, we introduce SOLAMI, the first end-to-end Social vision-Language-Action (VLA) Modeling framework for Immersive interaction with 3D autonomous characters. Specifically, SOLAMI builds 3D autonomous characters from three aspects: (1) Social VLA Architecture: We propose a unified social VLA framework to generate multimodal response (speech and motion) based on the user's multimodal input to drive the character for social interaction. (2) Interactive Multimodal Data: We present SynMSI, a synthetic multimodal social interaction dataset generated by an automatic pipeline using only existing motion datasets to address the issue of data scarcity. (3) Immersive VR Interface: We develop a VR interface that enables users to immersively interact with these characters driven by various architectures. Extensive quantitative experiments and user studies demonstrate that our framework leads to more precise and natural character responses (in both speech and motion) that align with user expectations with lower latency.
UniTalker: Scaling up Audio-Driven 3D Facial Animation through A Unified Model
Aug 01, 2024



Audio-driven 3D facial animation aims to map input audio to realistic facial motion. Despite significant progress, limitations arise from inconsistent 3D annotations, restricting previous models to training on specific annotations and thereby constraining the training scale. In this work, we present UniTalker, a unified model featuring a multi-head architecture designed to effectively leverage datasets with varied annotations. To enhance training stability and ensure consistency among multi-head outputs, we employ three training strategies, namely, PCA, model warm-up, and pivot identity embedding. To expand the training scale and diversity, we assemble A2F-Bench, comprising five publicly available datasets and three newly curated datasets. These datasets contain a wide range of audio domains, covering multilingual speech voices and songs, thereby scaling the training data from commonly employed datasets, typically less than 1 hour, to 18.5 hours. With a single trained UniTalker model, we achieve substantial lip vertex error reductions of 9.2% for BIWI dataset and 13.7% for Vocaset. Additionally, the pre-trained UniTalker exhibits promise as the foundation model for audio-driven facial animation tasks. Fine-tuning the pre-trained UniTalker on seen datasets further enhances performance on each dataset, with an average error reduction of 6.3% on A2F-Bench. Moreover, fine-tuning UniTalker on an unseen dataset with only half the data surpasses prior state-of-the-art models trained on the full dataset. The code and dataset are available at the project page https://github.com/X-niper/UniTalker.
WHAC: World-grounded Humans and Cameras
Mar 19, 2024



Estimating human and camera trajectories with accurate scale in the world coordinate system from a monocular video is a highly desirable yet challenging and ill-posed problem. In this study, we aim to recover expressive parametric human models (i.e., SMPL-X) and corresponding camera poses jointly, by leveraging the synergy between three critical players: the world, the human, and the camera. Our approach is founded on two key observations. Firstly, camera-frame SMPL-X estimation methods readily recover absolute human depth. Secondly, human motions inherently provide absolute spatial cues. By integrating these insights, we introduce a novel framework, referred to as WHAC, to facilitate world-grounded expressive human pose and shape estimation (EHPS) alongside camera pose estimation, without relying on traditional optimization techniques. Additionally, we present a new synthetic dataset, WHAC-A-Mole, which includes accurately annotated humans and cameras, and features diverse interactive human motions as well as realistic camera trajectories. Extensive experiments on both standard and newly established benchmarks highlight the superiority and efficacy of our framework. We will make the code and dataset publicly available.
Deep Geometrized Cartoon Line Inbetweening
Sep 28, 2023



We aim to address a significant but understudied problem in the anime industry, namely the inbetweening of cartoon line drawings. Inbetweening involves generating intermediate frames between two black-and-white line drawings and is a time-consuming and expensive process that can benefit from automation. However, existing frame interpolation methods that rely on matching and warping whole raster images are unsuitable for line inbetweening and often produce blurring artifacts that damage the intricate line structures. To preserve the precision and detail of the line drawings, we propose a new approach, AnimeInbet, which geometrizes raster line drawings into graphs of endpoints and reframes the inbetweening task as a graph fusion problem with vertex repositioning. Our method can effectively capture the sparsity and unique structure of line drawings while preserving the details during inbetweening. This is made possible via our novel modules, i.e., vertex geometric embedding, a vertex correspondence Transformer, an effective mechanism for vertex repositioning and a visibility predictor. To train our method, we introduce MixamoLine240, a new dataset of line drawings with ground truth vectorization and matching labels. Our experiments demonstrate that AnimeInbet synthesizes high-quality, clean, and complete intermediate line drawings, outperforming existing methods quantitatively and qualitatively, especially in cases with large motions. Data and code are available at https://github.com/lisiyao21/AnimeInbet.
HumanLiff: Layer-wise 3D Human Generation with Diffusion Model
Aug 18, 2023



3D human generation from 2D images has achieved remarkable progress through the synergistic utilization of neural rendering and generative models. Existing 3D human generative models mainly generate a clothed 3D human as an undetectable 3D model in a single pass, while rarely considering the layer-wise nature of a clothed human body, which often consists of the human body and various clothes such as underwear, outerwear, trousers, shoes, etc. In this work, we propose HumanLiff, the first layer-wise 3D human generative model with a unified diffusion process. Specifically, HumanLiff firstly generates minimal-clothed humans, represented by tri-plane features, in a canonical space, and then progressively generates clothes in a layer-wise manner. In this way, the 3D human generation is thus formulated as a sequence of diffusion-based 3D conditional generation. To reconstruct more fine-grained 3D humans with tri-plane representation, we propose a tri-plane shift operation that splits each tri-plane into three sub-planes and shifts these sub-planes to enable feature grid subdivision. To further enhance the controllability of 3D generation with 3D layered conditions, HumanLiff hierarchically fuses tri-plane features and 3D layered conditions to facilitate the 3D diffusion model learning. Extensive experiments on two layer-wise 3D human datasets, SynBody (synthetic) and TightCap (real-world), validate that HumanLiff significantly outperforms state-of-the-art methods in layer-wise 3D human generation. Our code will be available at https://skhu101.github.io/HumanLiff.
SynBody: Synthetic Dataset with Layered Human Models for 3D Human Perception and Modeling
Mar 30, 2023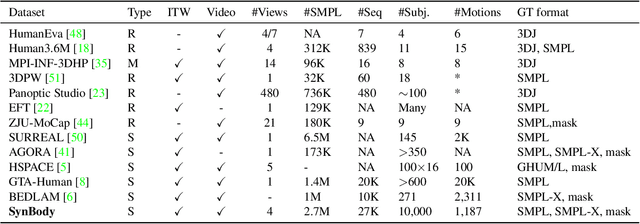
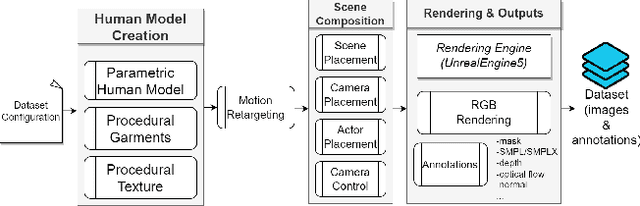
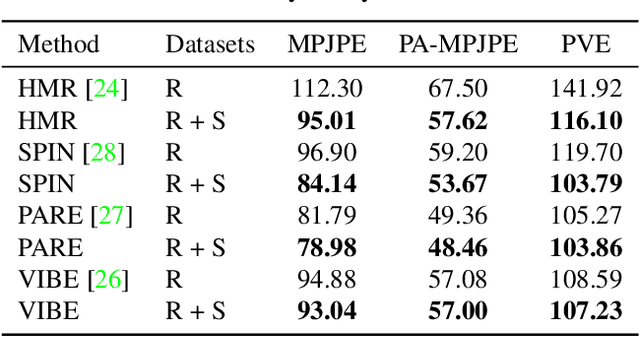
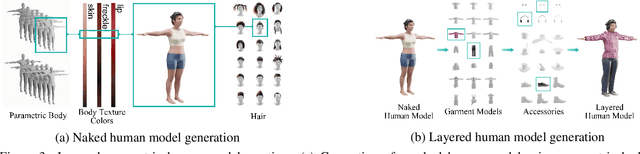
Synthetic data has emerged as a promising source for 3D human research as it offers low-cost access to large-scale human datasets. To advance the diversity and annotation quality of human models, we introduce a new synthetic dataset, Synbody, with three appealing features: 1) a clothed parametric human model that can generate a diverse range of subjects; 2) the layered human representation that naturally offers high-quality 3D annotations to support multiple tasks; 3) a scalable system for producing realistic data to facilitate real-world tasks. The dataset comprises 1.7M images with corresponding accurate 3D annotations, covering 10,000 human body models, 1000 actions, and various viewpoints. The dataset includes two subsets for human mesh recovery as well as human neural rendering. Extensive experiments on SynBody indicate that it substantially enhances both SMPL and SMPL-X estimation. Furthermore, the incorporation of layered annotations offers a valuable training resource for investigating the Human Neural Radiance Fields (NeRF).