 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhased DMD: Few-step Distribution Matching Distillation via Score Matching within Subintervals
Oct 31, 2025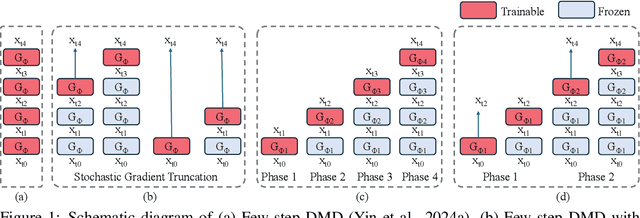

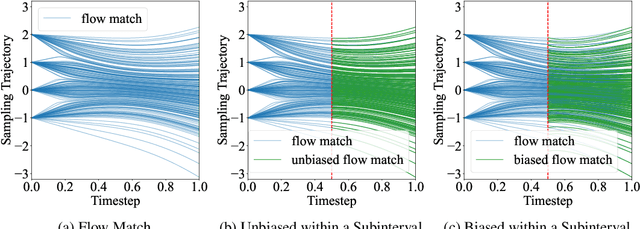
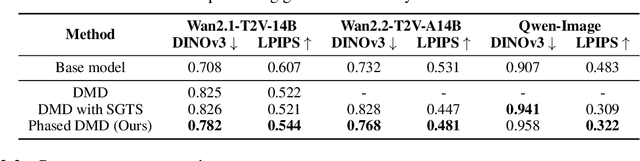
Distribution Matching Distillation (DMD) distills score-based generative models into efficient one-step generators, without requiring a one-to-one correspondence with the sampling trajectories of their teachers. However, limited model capacity causes one-step distilled models underperform on complex generative tasks, e.g., synthesizing intricate object motions in text-to-video generation. Directly extending DMD to multi-step distillation increases memory usage and computational depth, leading to instability and reduced efficiency. While prior works propose stochastic gradient truncation as a potential solution, we observe that it substantially reduces the generation diversity of multi-step distilled models, bringing it down to the level of their one-step counterparts. To address these limitations, we propose Phased DMD, a multi-step distillation framework that bridges the idea of phase-wise distillation with Mixture-of-Experts (MoE), reducing learning difficulty while enhancing model capacity. Phased DMD is built upon two key ideas: progressive distribution matching and score matching within subintervals. First, our model divides the SNR range into subintervals, progressively refining the model to higher SNR levels, to better capture complex distributions. Next, to ensure the training objective within each subinterval is accurate, we have conducted rigorous mathematical derivations. We validate Phased DMD by distilling state-of-the-art image and video generation models, including Qwen-Image (20B parameters) and Wan2.2 (28B parameters). Experimental results demonstrate that Phased DMD preserves output diversity better than DMD while retaining key generative capabilities. We will release our code and models.
SOLAMI: Social Vision-Language-Action Modeling for Immersive Interaction with 3D Autonomous Characters
Nov 29, 2024Human beings are social animals. How to equip 3D autonomous characters with similar social intelligence that can perceive, understand and interact with humans remains an open yet foundamental problem. In this paper, we introduce SOLAMI, the first end-to-end Social vision-Language-Action (VLA) Modeling framework for Immersive interaction with 3D autonomous characters. Specifically, SOLAMI builds 3D autonomous characters from three aspects: (1) Social VLA Architecture: We propose a unified social VLA framework to generate multimodal response (speech and motion) based on the user's multimodal input to drive the character for social interaction. (2) Interactive Multimodal Data: We present SynMSI, a synthetic multimodal social interaction dataset generated by an automatic pipeline using only existing motion datasets to address the issue of data scarcity. (3) Immersive VR Interface: We develop a VR interface that enables users to immersively interact with these characters driven by various architectures. Extensive quantitative experiments and user studies demonstrate that our framework leads to more precise and natural character responses (in both speech and motion) that align with user expectations with lower latency.
Digital Life Project: Autonomous 3D Characters with Social Intelligence
Dec 07, 2023



In this work, we present Digital Life Project, a framework utilizing language as the universal medium to build autonomous 3D characters, who are capable of engaging in social interactions and expressing with articulated body motions, thereby simulating life in a digital environment. Our framework comprises two primary components: 1) SocioMind: a meticulously crafted digital brain that models personalities with systematic few-shot exemplars, incorporates a reflection process based on psychology principles, and emulates autonomy by initiating dialogue topics; 2) MoMat-MoGen: a text-driven motion synthesis paradigm for controlling the character's digital body. It integrates motion matching, a proven industry technique to ensure motion quality, with cutting-edge advancements in motion generation for diversity. Extensive experiments demonstrate that each module achieves state-of-the-art performance in its respective domain. Collectively, they enable virtual characters to initiate and sustain dialogues autonomously, while evolving their socio-psychological states. Concurrently, these characters can perform contextually relevant bodily movements. Additionally, a motion captioning module further allows the virtual character to recognize and appropriately respond to human players' actions. Homepage: https://digital-life-project.com/
Motion-R3: Fast and Accurate Motion Annotation via Representation-based Representativeness Ranking
Apr 04, 2023



In this paper, we follow a data-centric philosophy and propose a novel motion annotation method based on the inherent representativeness of motion data in a given dataset. Specifically, we propose a Representation-based Representativeness Ranking R3 method that ranks all motion data in a given dataset according to their representativeness in a learned motion representation space. We further propose a novel dual-level motion constrastive learning method to learn the motion representation space in a more informative way. Thanks to its high efficiency, our method is particularly responsive to frequent requirements change and enables agile development of motion annotation models. Experimental results on the HDM05 dataset against state-of-the-art methods demonstrate the superiority of our method.
Diverse Motion In-betweening with Dual Posture Stitching
Mar 25, 2023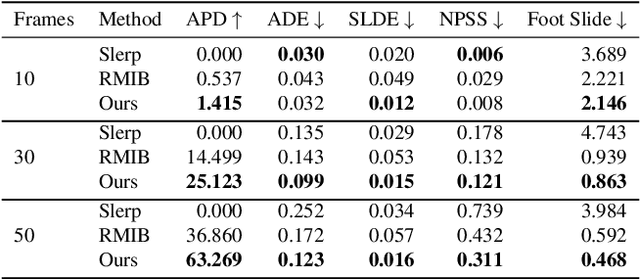
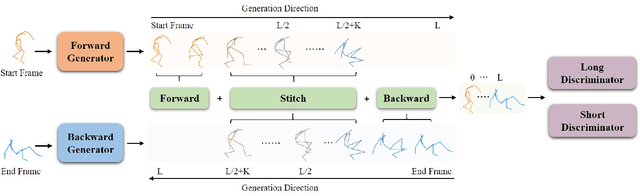
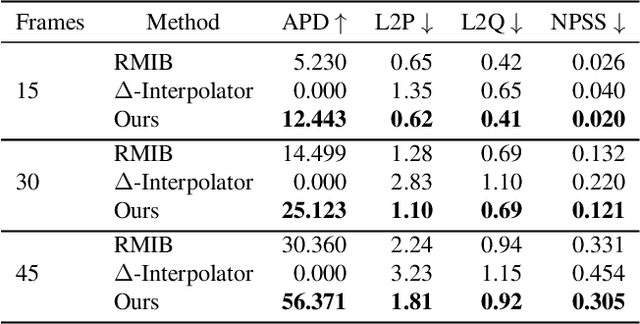
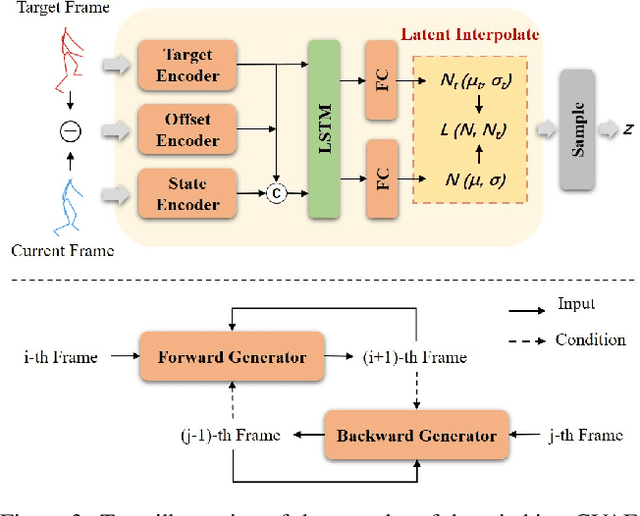
In-betweening is a technique for generating transitions given initial and target character states. The majority of existing works require multiple (often $>$10) frames as input, which are not always accessible. Our work deals with a focused yet challenging problem: to generate the transition when given exactly two frames (only the first and last). To cope with this challenging scenario, we implement our bi-directional scheme which generates forward and backward transitions from the start and end frames with two adversarial autoregressive networks, and stitches them in the middle of the transition where there is no strict ground truth. The autoregressive networks based on conditional variational autoencoders (CVAE) are optimized by searching for a pair of optimal latent codes that minimize a novel stitching loss between their outputs. Results show that our method achieves higher motion quality and more diverse results than existing methods on both the LaFAN1 and Human3.6m datasets.