 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Spatial Intelligence with Multimodal Foundation Models
Nov 17, 2025
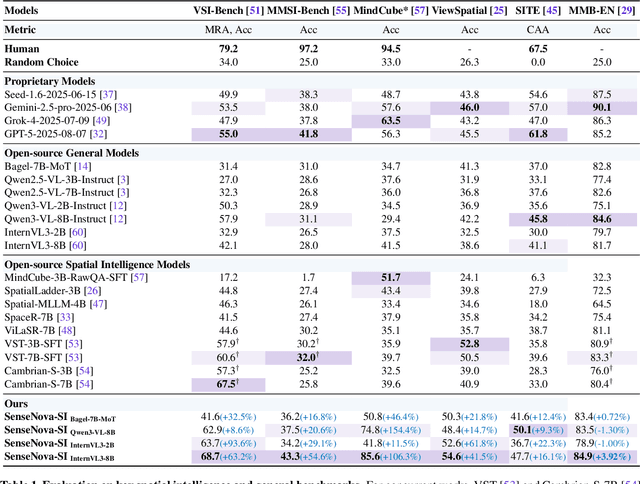


Despite remarkable progress, multimodal foundation models still exhibit surprising deficiencies in spatial intelligence. In this work, we explore scaling up multimodal foundation models to cultivate spatial intelligence within the SenseNova-SI family, built upon established multimodal foundations including visual understanding models (i.e., Qwen3-VL and InternVL3) and unified understanding and generation models (i.e., Bagel). We take a principled approach to constructing high-performing and robust spatial intelligence by systematically curating SenseNova-SI-8M: eight million diverse data samples under a rigorous taxonomy of spatial capabilities. SenseNova-SI demonstrates unprecedented performance across a broad range of spatial intelligence benchmarks: 68.7% on VSI-Bench, 43.3% on MMSI, 85.6% on MindCube, 54.6% on ViewSpatial, and 50.1% on SITE, while maintaining strong general multimodal understanding (e.g., 84.9% on MMBench-En). More importantly, we analyze the impact of data scaling, discuss early signs of emergent generalization capabilities enabled by diverse data training, analyze the risk of overfitting and language shortcuts, present a preliminary study on spatial chain-of-thought reasoning, and validate the potential downstream application. SenseNova-SI is an ongoing project, and this report will be updated continuously. All newly trained multimodal foundation models are publicly released to facilitate further research in this direction.
Phased DMD: Few-step Distribution Matching Distillation via Score Matching within Subintervals
Oct 31, 2025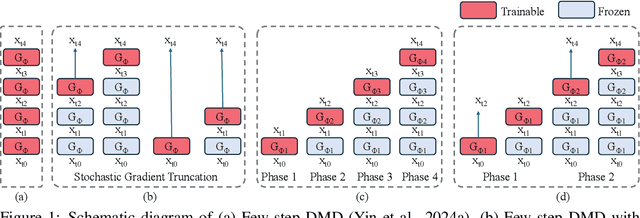

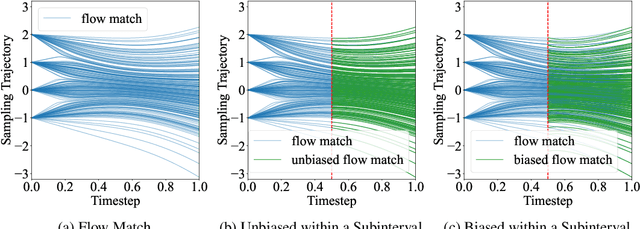
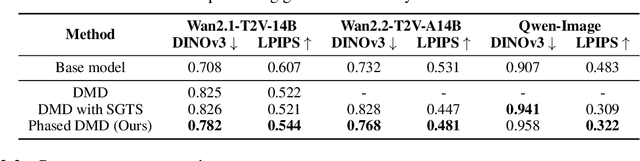
Distribution Matching Distillation (DMD) distills score-based generative models into efficient one-step generators, without requiring a one-to-one correspondence with the sampling trajectories of their teachers. However, limited model capacity causes one-step distilled models underperform on complex generative tasks, e.g., synthesizing intricate object motions in text-to-video generation. Directly extending DMD to multi-step distillation increases memory usage and computational depth, leading to instability and reduced efficiency. While prior works propose stochastic gradient truncation as a potential solution, we observe that it substantially reduces the generation diversity of multi-step distilled models, bringing it down to the level of their one-step counterparts. To address these limitations, we propose Phased DMD, a multi-step distillation framework that bridges the idea of phase-wise distillation with Mixture-of-Experts (MoE), reducing learning difficulty while enhancing model capacity. Phased DMD is built upon two key ideas: progressive distribution matching and score matching within subintervals. First, our model divides the SNR range into subintervals, progressively refining the model to higher SNR levels, to better capture complex distributions. Next, to ensure the training objective within each subinterval is accurate, we have conducted rigorous mathematical derivations. We validate Phased DMD by distilling state-of-the-art image and video generation models, including Qwen-Image (20B parameters) and Wan2.2 (28B parameters). Experimental results demonstrate that Phased DMD preserves output diversity better than DMD while retaining key generative capabilities. We will release our code and models.
Has GPT-5 Achieved Spatial Intelligence? An Empirical Study
Aug 18, 2025



Multi-modal models have achieved remarkable progress in recent years. Nevertheless, they continue to exhibit notable limitations in spatial understanding and reasoning, which are fundamental capabilities to achieving artificial general intelligence. With the recent release of GPT-5, allegedly the most powerful AI model to date, it is timely to examine where the leading models stand on the path toward spatial intelligence. First, we propose a comprehensive taxonomy of spatial tasks that unifies existing benchmarks and discuss the challenges in ensuring fair evaluation. We then evaluate state-of-the-art proprietary and open-source models on eight key benchmarks, at a cost exceeding one billion total tokens. Our empirical study reveals that (1) GPT-5 demonstrates unprecedented strength in spatial intelligence, yet (2) still falls short of human performance across a broad spectrum of tasks. Moreover, we (3) identify the more challenging spatial intelligence problems for multi-modal models, and (4) proprietary models do not exhibit a decisive advantage when facing the most difficult problems. In addition, we conduct a qualitative evaluation across a diverse set of scenarios that are intuitive for humans yet fail even the most advanced multi-modal models.
SOLAMI: Social Vision-Language-Action Modeling for Immersive Interaction with 3D Autonomous Characters
Nov 29, 2024Human beings are social animals. How to equip 3D autonomous characters with similar social intelligence that can perceive, understand and interact with humans remains an open yet foundamental problem. In this paper, we introduce SOLAMI, the first end-to-end Social vision-Language-Action (VLA) Modeling framework for Immersive interaction with 3D autonomous characters. Specifically, SOLAMI builds 3D autonomous characters from three aspects: (1) Social VLA Architecture: We propose a unified social VLA framework to generate multimodal response (speech and motion) based on the user's multimodal input to drive the character for social interaction. (2) Interactive Multimodal Data: We present SynMSI, a synthetic multimodal social interaction dataset generated by an automatic pipeline using only existing motion datasets to address the issue of data scarcity. (3) Immersive VR Interface: We develop a VR interface that enables users to immersively interact with these characters driven by various architectures. Extensive quantitative experiments and user studies demonstrate that our framework leads to more precise and natural character responses (in both speech and motion) that align with user expectations with lower latency.
UniTalker: Scaling up Audio-Driven 3D Facial Animation through A Unified Model
Aug 01, 2024



Audio-driven 3D facial animation aims to map input audio to realistic facial motion. Despite significant progress, limitations arise from inconsistent 3D annotations, restricting previous models to training on specific annotations and thereby constraining the training scale. In this work, we present UniTalker, a unified model featuring a multi-head architecture designed to effectively leverage datasets with varied annotations. To enhance training stability and ensure consistency among multi-head outputs, we employ three training strategies, namely, PCA, model warm-up, and pivot identity embedding. To expand the training scale and diversity, we assemble A2F-Bench, comprising five publicly available datasets and three newly curated datasets. These datasets contain a wide range of audio domains, covering multilingual speech voices and songs, thereby scaling the training data from commonly employed datasets, typically less than 1 hour, to 18.5 hours. With a single trained UniTalker model, we achieve substantial lip vertex error reductions of 9.2% for BIWI dataset and 13.7% for Vocaset. Additionally, the pre-trained UniTalker exhibits promise as the foundation model for audio-driven facial animation tasks. Fine-tuning the pre-trained UniTalker on seen datasets further enhances performance on each dataset, with an average error reduction of 6.3% on A2F-Bench. Moreover, fine-tuning UniTalker on an unseen dataset with only half the data surpasses prior state-of-the-art models trained on the full dataset. The code and dataset are available at the project page https://github.com/X-niper/UniTalker.
High-Quality 3D Face Reconstruction with Affine Convolutional Networks
Oct 22, 2023



Recent works based on convolutional encoder-decoder architecture and 3DMM parameterization have shown great potential for canonical view reconstruction from a single input image. Conventional CNN architectures benefit from exploiting the spatial correspondence between the input and output pixels. However, in 3D face reconstruction, the spatial misalignment between the input image (e.g. face) and the canonical/UV output makes the feature encoding-decoding process quite challenging. In this paper, to tackle this problem, we propose a new network architecture, namely the Affine Convolution Networks, which enables CNN based approaches to handle spatially non-corresponding input and output images and maintain high-fidelity quality output at the same time. In our method, an affine transformation matrix is learned from the affine convolution layer for each spatial location of the feature maps. In addition, we represent 3D human heads in UV space with multiple components, including diffuse maps for texture representation, position maps for geometry representation, and light maps for recovering more complex lighting conditions in the real world. All the components can be trained without any manual annotations. Our method is parametric-free and can generate high-quality UV maps at resolution of 512 x 512 pixels, while previous approaches normally generate 256 x 256 pixels or smaller. Our code will be released once the paper got accepted.