 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Quality 3D Face Reconstruction with Affine Convolutional Networks
Oct 22, 2023



Recent works based on convolutional encoder-decoder architecture and 3DMM parameterization have shown great potential for canonical view reconstruction from a single input image. Conventional CNN architectures benefit from exploiting the spatial correspondence between the input and output pixels. However, in 3D face reconstruction, the spatial misalignment between the input image (e.g. face) and the canonical/UV output makes the feature encoding-decoding process quite challenging. In this paper, to tackle this problem, we propose a new network architecture, namely the Affine Convolution Networks, which enables CNN based approaches to handle spatially non-corresponding input and output images and maintain high-fidelity quality output at the same time. In our method, an affine transformation matrix is learned from the affine convolution layer for each spatial location of the feature maps. In addition, we represent 3D human heads in UV space with multiple components, including diffuse maps for texture representation, position maps for geometry representation, and light maps for recovering more complex lighting conditions in the real world. All the components can be trained without any manual annotations. Our method is parametric-free and can generate high-quality UV maps at resolution of 512 x 512 pixels, while previous approaches normally generate 256 x 256 pixels or smaller. Our code will be released once the paper got accepted.
MeInGame: Create a Game Character Face from a Single Portrait
Feb 07, 2021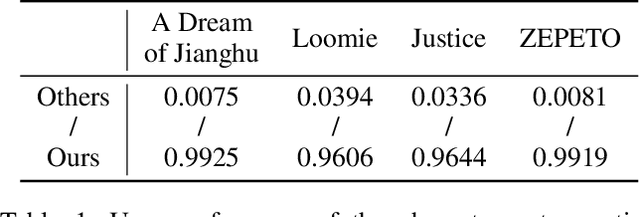
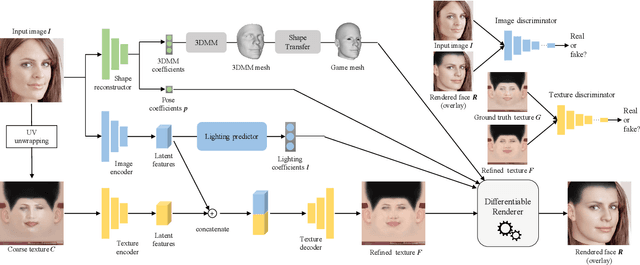

Many deep learning based 3D face reconstruction methods have been proposed recently, however, few of them have applications in games. Current game character customization systems either require players to manually adjust considerable face attributes to obtain the desired face, or have limited freedom of facial shape and texture. In this paper, we propose an automatic character face creation method that predicts both facial shape and texture from a single portrait, and it can be integrated into most existing 3D games. Although 3D Morphable Face Model (3DMM) based methods can restore accurate 3D faces from single images, the topology of 3DMM mesh is different from the meshes used in most games. To acquire fidelity texture, existing methods require a large amount of face texture data for training, while building such datasets is time-consuming and laborious. Besides, such a dataset collected under laboratory conditions may not generalized well to in-the-wild situations. To tackle these problems, we propose 1) a low-cost facial texture acquisition method, 2) a shape transfer algorithm that can transform the shape of a 3DMM mesh to games, and 3) a new pipeline for training 3D game face reconstruction networks. The proposed method not only can produce detailed and vivid game characters similar to the input portrait, but can also eliminate the influence of lighting and occlusions. Experiments show that our method outperforms state-of-the-art methods used in games.
Towards High-Fidelity 3D Face Reconstruction from In-the-Wild Images Using Graph Convolutional Networks
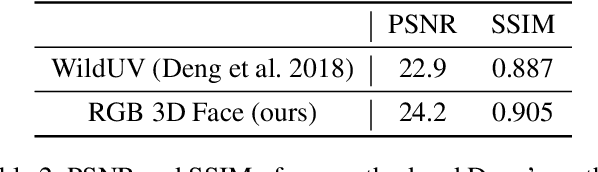
Mar 12, 2020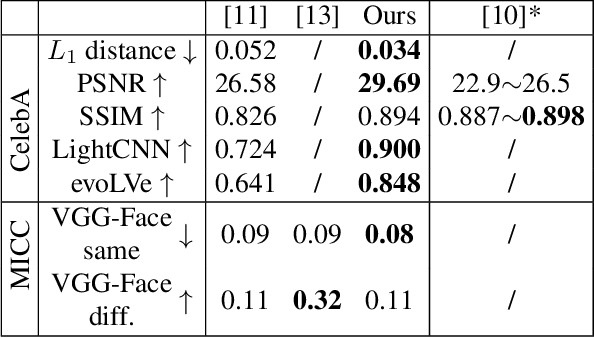
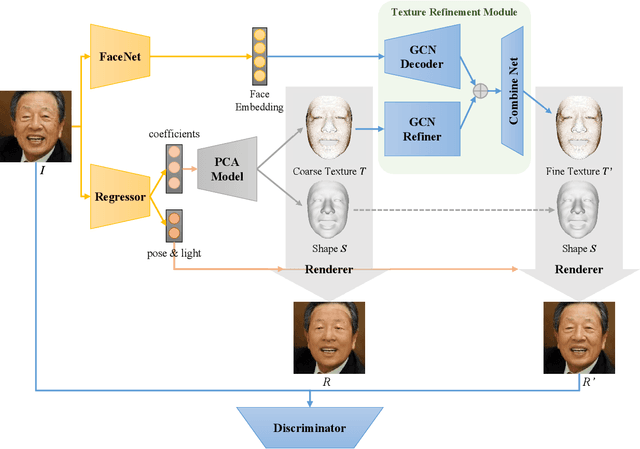
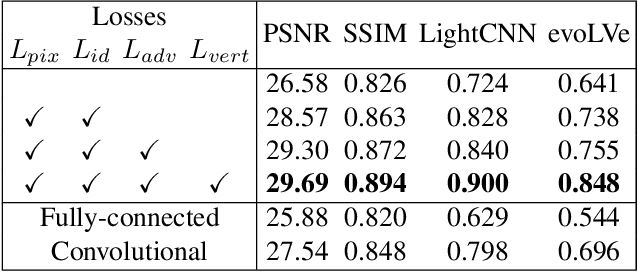

3D Morphable Model (3DMM) based methods have achieved great success in recovering 3D face shapes from single-view images. However, the facial textures recovered by such methods lack the fidelity as exhibited in the input images. Recent work demonstrates high-quality facial texture recovering with generative networks trained from a large-scale database of high-resolution UV maps of face textures, which is hard to prepare and not publicly available. In this paper, we introduce a method to reconstruct 3D facial shapes with high-fidelity textures from single-view images in-the-wild, without the need to capture a large-scale face texture database. The main idea is to refine the initial texture generated by a 3DMM based method with facial details from the input image. To this end, we propose to use graph convolutional networks to reconstruct the detailed colors for the mesh vertices instead of reconstructing the UV map. Experiments show that our method can generate high-quality results and outperforms state-of-the-art methods in both qualitative and quantitative comparisons.