 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSGMD: Score Gradient Matching Distillation for Few-Step Video Diffusion Distillation
May 28, 2026Distribution Matching Distillation (DMD) is a widely used paradigm for accelerating inference in few-step video diffusion models. However, DMD-style video distillation faces two coupled challenges: the fake score must track a continuously evolving generator, making training costly when frequent updates are required, while reverse-KL-style matching can be mode-seeking and conservative for preserving strong motion dynamics. To address these issues, we propose \textbf{Score Gradient Matching Distillation (SGMD)}. SGMD adopts a fake-score perspective by directly optimizing the fake score toward the teacher, while using teacher stop-gradient Fisher as a stable distribution-matching objective. We provide a gradient analysis that motivates this objective choice under ideal tracking. Building on this, SGMD introduces a pair of dual potentials: negative-residual (NR) for outer-loop correction and residual-contraction (RC) for inner-loop tracking. Empirically, compared to DMD2, SGMD achieves an approximately $\sim 3\times$ training speedup and substantially improves motion dynamics for 4-step distilled models while preserving temporal consistency. A human study confirms that SGMD is preferred in motion quality and overall preference, while visual quality and text alignment remain comparable. Code is available at https://github.com/ModelTC/LightX2V.
SenseNova-U1: Unifying Multimodal Understanding and Generation with NEO-unify Architecture
May 12, 2026Recent large vision-language models (VLMs) remain fundamentally constrained by a persistent dichotomy: understanding and generation are treated as distinct problems, leading to fragmented architectures, cascaded pipelines, and misaligned representation spaces. We argue that this divide is not merely an engineering artifact, but a structural limitation that hinders the emergence of native multimodal intelligence. Hence, we introduce SenseNova-U1, a native unified multimodal paradigm built upon NEO-unify, in which understanding and generation evolve as synergistic views of a single underlying process. We launch two native unified variants, SenseNova-U1-8B-MoT and SenseNova-U1-A3B-MoT, built on dense (8B) and mixture-of-experts (30B-A3B) understanding baselines, respectively. Designed from first principles, they rival top-tier understanding-only VLMs across text understanding, vision-language perception, knowledge reasoning, agentic decision-making, and spatial intelligence. Meanwhile, they deliver strong semantic consistency and visual fidelity, excelling in conventional or knowledge-intensive any-to-image (X2I) synthesis, complex text-rich infographic generation, and interleaved vision-language generation, with or without think patterns. Beyond performance, we show detailed model design, data preprocessing, pre-/post-training, and inference strategies to support community research. Last but not least, preliminary evidence demonstrates that our models extend beyond perception and generation, performing strongly in vision-language-action (VLA) and world model (WM) scenarios. This points toward a broader roadmap where models do not translate between modalities, but think and act across them in a native manner. Multimodal AI is no longer about connecting separate systems, but about building a unified one and trusting the necessary capabilities to emerge from within.
Scaling Spatial Intelligence with Multimodal Foundation Models
Nov 17, 2025
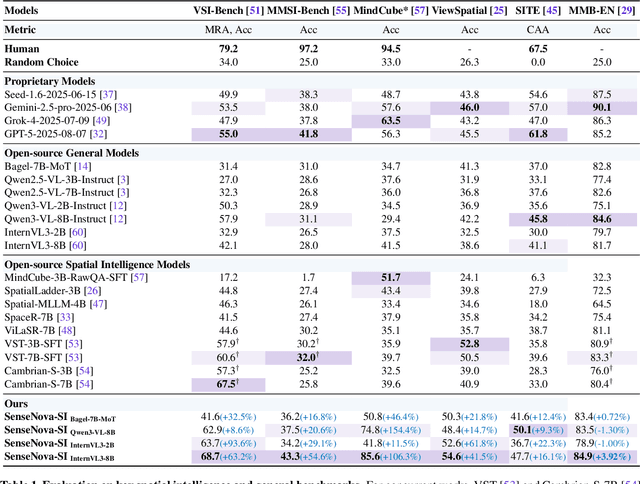


Despite remarkable progress, multimodal foundation models still exhibit surprising deficiencies in spatial intelligence. In this work, we explore scaling up multimodal foundation models to cultivate spatial intelligence within the SenseNova-SI family, built upon established multimodal foundations including visual understanding models (i.e., Qwen3-VL and InternVL3) and unified understanding and generation models (i.e., Bagel). We take a principled approach to constructing high-performing and robust spatial intelligence by systematically curating SenseNova-SI-8M: eight million diverse data samples under a rigorous taxonomy of spatial capabilities. SenseNova-SI demonstrates unprecedented performance across a broad range of spatial intelligence benchmarks: 68.7% on VSI-Bench, 43.3% on MMSI, 85.6% on MindCube, 54.6% on ViewSpatial, and 50.1% on SITE, while maintaining strong general multimodal understanding (e.g., 84.9% on MMBench-En). More importantly, we analyze the impact of data scaling, discuss early signs of emergent generalization capabilities enabled by diverse data training, analyze the risk of overfitting and language shortcuts, present a preliminary study on spatial chain-of-thought reasoning, and validate the potential downstream application. SenseNova-SI is an ongoing project, and this report will be updated continuously. All newly trained multimodal foundation models are publicly released to facilitate further research in this direction.
Phased DMD: Few-step Distribution Matching Distillation via Score Matching within Subintervals
Oct 31, 2025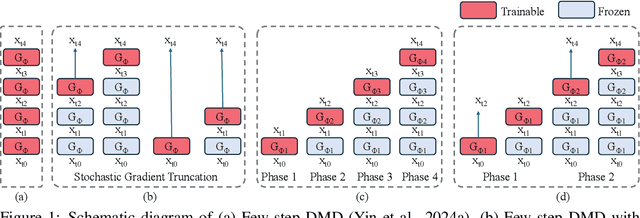

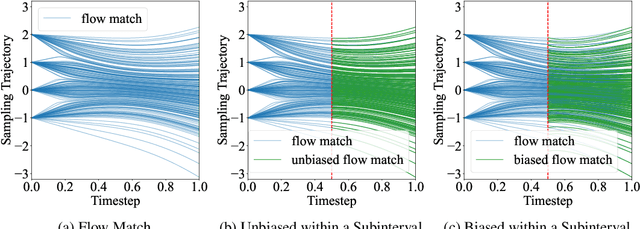
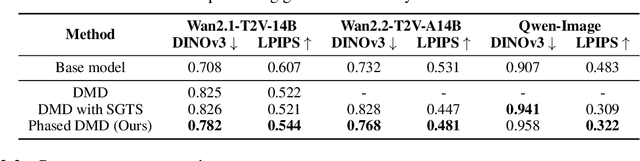
Distribution Matching Distillation (DMD) distills score-based generative models into efficient one-step generators, without requiring a one-to-one correspondence with the sampling trajectories of their teachers. However, limited model capacity causes one-step distilled models underperform on complex generative tasks, e.g., synthesizing intricate object motions in text-to-video generation. Directly extending DMD to multi-step distillation increases memory usage and computational depth, leading to instability and reduced efficiency. While prior works propose stochastic gradient truncation as a potential solution, we observe that it substantially reduces the generation diversity of multi-step distilled models, bringing it down to the level of their one-step counterparts. To address these limitations, we propose Phased DMD, a multi-step distillation framework that bridges the idea of phase-wise distillation with Mixture-of-Experts (MoE), reducing learning difficulty while enhancing model capacity. Phased DMD is built upon two key ideas: progressive distribution matching and score matching within subintervals. First, our model divides the SNR range into subintervals, progressively refining the model to higher SNR levels, to better capture complex distributions. Next, to ensure the training objective within each subinterval is accurate, we have conducted rigorous mathematical derivations. We validate Phased DMD by distilling state-of-the-art image and video generation models, including Qwen-Image (20B parameters) and Wan2.2 (28B parameters). Experimental results demonstrate that Phased DMD preserves output diversity better than DMD while retaining key generative capabilities. We will release our code and models.
Has GPT-5 Achieved Spatial Intelligence? An Empirical Study
Aug 18, 2025



Multi-modal models have achieved remarkable progress in recent years. Nevertheless, they continue to exhibit notable limitations in spatial understanding and reasoning, which are fundamental capabilities to achieving artificial general intelligence. With the recent release of GPT-5, allegedly the most powerful AI model to date, it is timely to examine where the leading models stand on the path toward spatial intelligence. First, we propose a comprehensive taxonomy of spatial tasks that unifies existing benchmarks and discuss the challenges in ensuring fair evaluation. We then evaluate state-of-the-art proprietary and open-source models on eight key benchmarks, at a cost exceeding one billion total tokens. Our empirical study reveals that (1) GPT-5 demonstrates unprecedented strength in spatial intelligence, yet (2) still falls short of human performance across a broad spectrum of tasks. Moreover, we (3) identify the more challenging spatial intelligence problems for multi-modal models, and (4) proprietary models do not exhibit a decisive advantage when facing the most difficult problems. In addition, we conduct a qualitative evaluation across a diverse set of scenarios that are intuitive for humans yet fail even the most advanced multi-modal models.
UniTalker: Scaling up Audio-Driven 3D Facial Animation through A Unified Model
Aug 01, 2024



Audio-driven 3D facial animation aims to map input audio to realistic facial motion. Despite significant progress, limitations arise from inconsistent 3D annotations, restricting previous models to training on specific annotations and thereby constraining the training scale. In this work, we present UniTalker, a unified model featuring a multi-head architecture designed to effectively leverage datasets with varied annotations. To enhance training stability and ensure consistency among multi-head outputs, we employ three training strategies, namely, PCA, model warm-up, and pivot identity embedding. To expand the training scale and diversity, we assemble A2F-Bench, comprising five publicly available datasets and three newly curated datasets. These datasets contain a wide range of audio domains, covering multilingual speech voices and songs, thereby scaling the training data from commonly employed datasets, typically less than 1 hour, to 18.5 hours. With a single trained UniTalker model, we achieve substantial lip vertex error reductions of 9.2% for BIWI dataset and 13.7% for Vocaset. Additionally, the pre-trained UniTalker exhibits promise as the foundation model for audio-driven facial animation tasks. Fine-tuning the pre-trained UniTalker on seen datasets further enhances performance on each dataset, with an average error reduction of 6.3% on A2F-Bench. Moreover, fine-tuning UniTalker on an unseen dataset with only half the data surpasses prior state-of-the-art models trained on the full dataset. The code and dataset are available at the project page https://github.com/X-niper/UniTalker.
Learning Dense Correspondence for NeRF-Based Face Reenactment
Dec 19, 2023



Face reenactment is challenging due to the need to establish dense correspondence between various face representations for motion transfer. Recent studies have utilized Neural Radiance Field (NeRF) as fundamental representation, which further enhanced the performance of multi-view face reenactment in photo-realism and 3D consistency. However, establishing dense correspondence between different face NeRFs is non-trivial, because implicit representations lack ground-truth correspondence annotations like mesh-based 3D parametric models (e.g., 3DMM) with index-aligned vertexes. Although aligning 3DMM space with NeRF-based face representations can realize motion control, it is sub-optimal for their limited face-only modeling and low identity fidelity. Therefore, we are inspired to ask: Can we learn the dense correspondence between different NeRF-based face representations without a 3D parametric model prior? To address this challenge, we propose a novel framework, which adopts tri-planes as fundamental NeRF representation and decomposes face tri-planes into three components: canonical tri-planes, identity deformations, and motion. In terms of motion control, our key contribution is proposing a Plane Dictionary (PlaneDict) module, which efficiently maps the motion conditions to a linear weighted addition of learnable orthogonal plane bases. To the best of our knowledge, our framework is the first method that achieves one-shot multi-view face reenactment without a 3D parametric model prior. Extensive experiments demonstrate that we produce better results in fine-grained motion control and identity preservation than previous methods.
Digital Life Project: Autonomous 3D Characters with Social Intelligence
Dec 07, 2023



In this work, we present Digital Life Project, a framework utilizing language as the universal medium to build autonomous 3D characters, who are capable of engaging in social interactions and expressing with articulated body motions, thereby simulating life in a digital environment. Our framework comprises two primary components: 1) SocioMind: a meticulously crafted digital brain that models personalities with systematic few-shot exemplars, incorporates a reflection process based on psychology principles, and emulates autonomy by initiating dialogue topics; 2) MoMat-MoGen: a text-driven motion synthesis paradigm for controlling the character's digital body. It integrates motion matching, a proven industry technique to ensure motion quality, with cutting-edge advancements in motion generation for diversity. Extensive experiments demonstrate that each module achieves state-of-the-art performance in its respective domain. Collectively, they enable virtual characters to initiate and sustain dialogues autonomously, while evolving their socio-psychological states. Concurrently, these characters can perform contextually relevant bodily movements. Additionally, a motion captioning module further allows the virtual character to recognize and appropriately respond to human players' actions. Homepage: https://digital-life-project.com/
ReliTalk: Relightable Talking Portrait Generation from a Single Video
Sep 05, 2023Recent years have witnessed great progress in creating vivid audio-driven portraits from monocular videos. However, how to seamlessly adapt the created video avatars to other scenarios with different backgrounds and lighting conditions remains unsolved. On the other hand, existing relighting studies mostly rely on dynamically lighted or multi-view data, which are too expensive for creating video portraits. To bridge this gap, we propose ReliTalk, a novel framework for relightable audio-driven talking portrait generation from monocular videos. Our key insight is to decompose the portrait's reflectance from implicitly learned audio-driven facial normals and images. Specifically, we involve 3D facial priors derived from audio features to predict delicate normal maps through implicit functions. These initially predicted normals then take a crucial part in reflectance decomposition by dynamically estimating the lighting condition of the given video. Moreover, the stereoscopic face representation is refined using the identity-consistent loss under simulated multiple lighting conditions, addressing the ill-posed problem caused by limited views available from a single monocular video. Extensive experiments validate the superiority of our proposed framework on both real and synthetic datasets. Our code is released in https://github.com/arthur-qiu/ReliTalk.
HuMMan: Multi-Modal 4D Human Dataset for Versatile Sensing and Modeling
Apr 28, 2022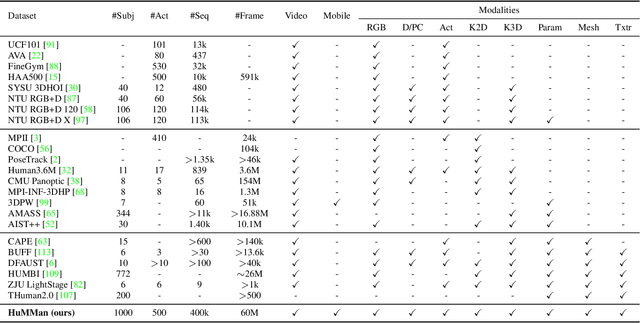
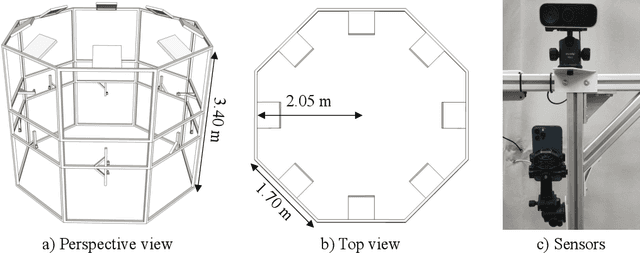

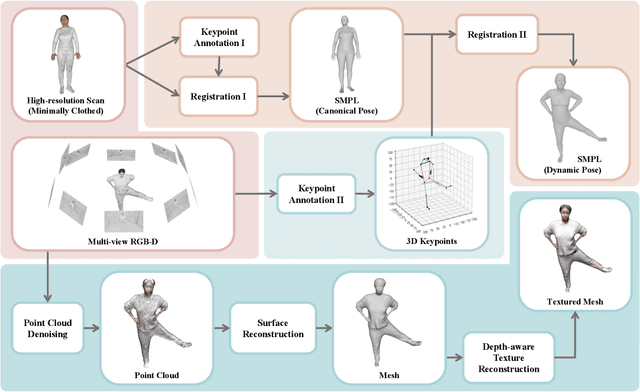
4D human sensing and modeling are fundamental tasks in vision and graphics with numerous applications. With the advances of new sensors and algorithms, there is an increasing demand for more versatile datasets. In this work, we contribute HuMMan, a large-scale multi-modal 4D human dataset with 1000 human subjects, 400k sequences and 60M frames. HuMMan has several appealing properties: 1) multi-modal data and annotations including color images, point clouds, keypoints, SMPL parameters, and textured meshes; 2) popular mobile device is included in the sensor suite; 3) a set of 500 actions, designed to cover fundamental movements; 4) multiple tasks such as action recognition, pose estimation, parametric human recovery, and textured mesh reconstruction are supported and evaluated. Extensive experiments on HuMMan voice the need for further study on challenges such as fine-grained action recognition, dynamic human mesh reconstruction, point cloud-based parametric human recovery, and cross-device domain gaps.