 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgoProx: Evaluating MLLMs on Egocentric 3D Proximity Reasoning Across a Cognitive Hierarchy
May 26, 2026Humans constantly reason about 3D proximity, the relations between their body and surrounding objects, to guide perception and action in daily life. Whether multimodal large language models (MLLMs) can perform such embodied 3D reasoning remains unclear. To this end, we introduce EgoProx, a benchmark for egocentric 3D proximity reasoning. We organize our tasks along a cognitive chain, covering intention, exploration, exploitation, and chain-of-actions reasoning. We also design an agent based data engine that produces diverse and consistent QA pairs at scale. We benchmark prevailing MLLMs on EgoProx and conduct additional analyses with dataset specific and task specific instruction tuning. We observe large cross-domain gains, indicating that current MLLMs contain some spatial knowledge; however, they still struggle to effectively leverage it for spatial reasoning VQA.
Introspective Diffusion Language Models
Apr 13, 2026Diffusion language models promise parallel generation, yet still lag behind autoregressive (AR) models in quality. We stem this gap to a failure of introspective consistency: AR models agree with their own generations, while DLMs often do not. We define the introspective acceptance rate, which measures whether a model accepts its previously generated tokens. This reveals why AR training has a structural advantage: causal masking and logit shifting implicitly enforce introspective consistency. Motivated by this observation, we introduce Introspective Diffusion Language Model (I-DLM), a paradigm that retains diffusion-style parallel decoding while inheriting the introspective consistency of AR training. I-DLM uses a novel introspective strided decoding (ISD) algorithm, which enables the model to verify previously generated tokens while advancing new ones in the same forward pass. From a systems standpoint, we build I-DLM inference engine on AR-inherited optimizations and further customize it with a stationary-batch scheduler. To the best of our knowledge, I-DLM is the first DLM to match the quality of its same-scale AR counterpart while outperforming prior DLMs in both model quality and practical serving efficiency across 15 benchmarks. It reaches 69.6 on AIME-24 and 45.7 on LiveCodeBench-v6, exceeding LLaDA-2.1-mini (16B) by more than 26 and 15 points, respectively. Beyond quality, I-DLM is designed for the growing demand of large-concurrency serving, delivering about 3x higher throughput than prior state-of-the-art DLMs.
IOTA: Corrective Knowledge-Guided Prompt Learning via Black-White Box Framework
Jan 28, 2026Recently, adapting pre-trained models to downstream tasks has attracted increasing interest. Previous Parameter-Efficient-Tuning (PET) methods regard the pre-trained model as an opaque Black Box model, relying purely on data-driven optimization and underutilizing their inherent prior knowledge. This oversight limits the models' potential for effective downstream task adaptation. To address these issues, we propose a novel black-whIte bOx prompT leArning framework (IOTA), which integrates a data-driven Black Box module with a knowledge-driven White Box module for downstream task adaptation. Specifically, the White Box module derives corrective knowledge by contrasting the wrong predictions with the right cognition. This knowledge is verbalized into interpretable human prompts and leveraged through a corrective knowledge-guided prompt selection strategy to guide the Black Box module toward more accurate predictions. By jointly leveraging knowledge- and data-driven learning signals, IOTA achieves effective downstream task adaptation. Experimental results on 12 image classification benchmarks under few-shot and easy-to-hard adaptation settings demonstrate the effectiveness of corrective knowledge and the superiority of our method over state-of-the-art methods.
Robust Filtering and Learning in State-Space Models: Skewness and Heavy Tails Via Asymmetric Laplace Distribution
Jul 30, 2025State-space models are pivotal for dynamic system analysis but often struggle with outlier data that deviates from Gaussian distributions, frequently exhibiting skewness and heavy tails. This paper introduces a robust extension utilizing the asymmetric Laplace distribution, specifically tailored to capture these complex characteristics. We propose an efficient variational Bayes algorithm and a novel single-loop parameter estimation strategy, significantly enhancing the efficiency of the filtering, smoothing, and parameter estimation processes. Our comprehensive experiments demonstrate that our methods provide consistently robust performance across various noise settings without the need for manual hyperparameter adjustments. In stark contrast, existing models generally rely on specific noise conditions and necessitate extensive manual tuning. Moreover, our approach uses far fewer computational resources, thereby validating the model's effectiveness and underscoring its potential for practical applications in fields such as robust control and financial modeling.
Single-agent or Multi-agent Systems? Why Not Both?
May 23, 2025Multi-agent systems (MAS) decompose complex tasks and delegate subtasks to different large language model (LLM) agents and tools. Prior studies have reported the superior accuracy performance of MAS across diverse domains, enabled by long-horizon context tracking and error correction through role-specific agents. However, the design and deployment of MAS incur higher complexity and runtime cost compared to single-agent systems (SAS). Meanwhile, frontier LLMs, such as OpenAI-o3 and Gemini-2.5-Pro, have rapidly advanced in long-context reasoning, memory retention, and tool usage, mitigating many limitations that originally motivated MAS designs. In this paper, we conduct an extensive empirical study comparing MAS and SAS across various popular agentic applications. We find that the benefits of MAS over SAS diminish as LLM capabilities improve, and we propose efficient mechanisms to pinpoint the error-prone agent in MAS. Furthermore, the performance discrepancy between MAS and SAS motivates our design of a hybrid agentic paradigm, request cascading between MAS and SAS, to improve both efficiency and capability. Our design improves accuracy by 1.1-12% while reducing deployment costs by up to 20% across various agentic applications.
Relative Pose Estimation through Affine Corrections of Monocular Depth Priors
Jan 09, 2025



Monocular depth estimation (MDE) models have undergone significant advancements over recent years. Many MDE models aim to predict affine-invariant relative depth from monocular images, while recent developments in large-scale training and vision foundation models enable reasonable estimation of metric (absolute) depth. However, effectively leveraging these predictions for geometric vision tasks, in particular relative pose estimation, remains relatively under explored. While depths provide rich constraints for cross-view image alignment, the intrinsic noise and ambiguity from the monocular depth priors present practical challenges to improving upon classic keypoint-based solutions. In this paper, we develop three solvers for relative pose estimation that explicitly account for independent affine (scale and shift) ambiguities, covering both calibrated and uncalibrated conditions. We further propose a hybrid estimation pipeline that combines our proposed solvers with classic point-based solvers and epipolar constraints. We find that the affine correction modeling is beneficial to not only the relative depth priors but also, surprisingly, the ``metric" ones. Results across multiple datasets demonstrate large improvements of our approach over classic keypoint-based baselines and PnP-based solutions, under both calibrated and uncalibrated setups. We also show that our method improves consistently with different feature matchers and MDE models, and can further benefit from very recent advances on both modules. Code is available at https://github.com/MarkYu98/madpose.
Robust and Constrained Estimation of State-Space Models: A Majorization-Minimization Approach
Nov 18, 2024In this paper, we present a novel optimization algorithm designed specifically for estimating state-space models to deal with heavy-tailed measurement noise and constraints. Our algorithm addresses two significant limitations found in existing approaches: susceptibility to measurement noise outliers and difficulties in incorporating constraints into state estimation. By formulating constrained state estimation as an optimization problem and employing the Majorization-Minimization (MM) approach, our framework provides a unified solution that enhances the robustness of the Kalman filter. Experimental results demonstrate high accuracy and computational efficiency achieved by our proposed approach, establishing it as a promising solution for robust and constrained state estimation in real-world applications.
Continual Novel Class Discovery via Feature Enhancement and Adaptation
May 10, 2024



Continual Novel Class Discovery (CNCD) aims to continually discover novel classes without labels while maintaining the recognition capability for previously learned classes. The main challenges faced by CNCD include the feature-discrepancy problem, the inter-session confusion problem, etc. In this paper, we propose a novel Feature Enhancement and Adaptation method for the CNCD to tackle the above challenges, which consists of a guide-to-novel framework, a centroid-to-samples similarity constraint (CSS), and a boundary-aware prototype constraint (BAP). More specifically, the guide-to-novel framework is established to continually discover novel classes under the guidance of prior distribution. Afterward, the CSS is designed to constrain the relationship between centroid-to-samples similarities of different classes, thereby enhancing the distinctiveness of features among novel classes. Finally, the BAP is proposed to keep novel class features aware of the positions of other class prototypes during incremental sessions, and better adapt novel class features to the shared feature space. Experimental results on three benchmark datasets demonstrate the superiority of our method, especially in more challenging protocols with more incremental sessions.
Learning the Market: Sentiment-Based Ensemble Trading Agents
Feb 02, 2024



We propose the integration of sentiment analysis and deep-reinforcement learning ensemble algorithms for stock trading, and design a strategy capable of dynamically altering its employed agent given concurrent market sentiment. In particular, we create a simple-yet-effective method for extracting news sentiment and combine this with general improvements upon existing works, resulting in automated trading agents that effectively consider both qualitative market factors and quantitative stock data. We show that our approach results in a strategy that is profitable, robust, and risk-minimal -- outperforming the traditional ensemble strategy as well as single agent algorithms and market metrics. Our findings determine that the conventional practice of switching ensemble agents every fixed-number of months is sub-optimal, and that a dynamic sentiment-based framework greatly unlocks additional performance within these agents. Furthermore, as we have designed our algorithm with simplicity and efficiency in mind, we hypothesize that the transition of our method from historical evaluation towards real-time trading with live data should be relatively simple.
LoftQ: LoRA-Fine-Tuning-Aware Quantization for Large Language Models
Oct 23, 2023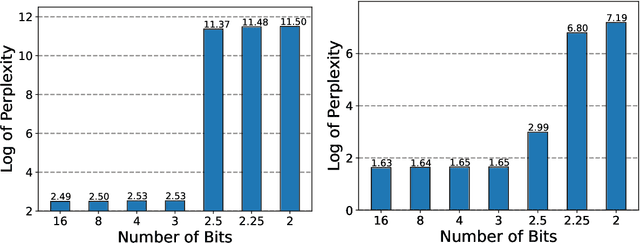
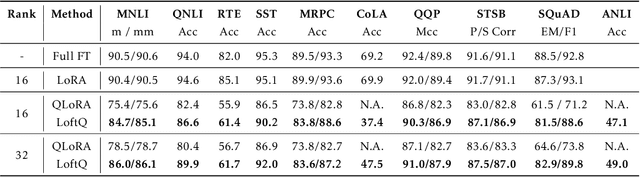
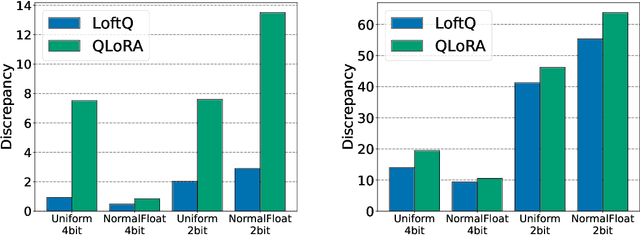
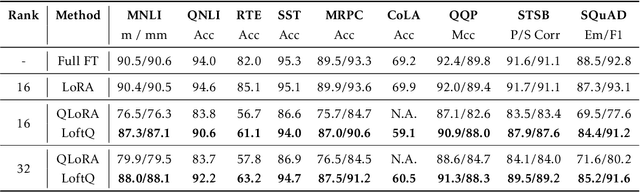
Quantization is an indispensable technique for serving Large Language Models (LLMs) and has recently found its way into LoRA fine-tuning. In this work we focus on the scenario where quantization and LoRA fine-tuning are applied together on a pre-trained model. In such cases it is common to observe a consistent gap in the performance on downstream tasks between full fine-tuning and quantization plus LoRA fine-tuning approach. In response, we propose LoftQ (LoRA-Fine-Tuning-aware Quantization), a novel quantization framework that simultaneously quantizes an LLM and finds a proper low-rank initialization for LoRA fine-tuning. Such an initialization alleviates the discrepancy between the quantized and full-precision model and significantly improves the generalization in downstream tasks. We evaluate our method on natural language understanding, question answering, summarization, and natural language generation tasks. Experiments show that our method is highly effective and outperforms existing quantization methods, especially in the challenging 2-bit and 2/4-bit mixed precision regimes. We will release our code.