 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning the Market: Sentiment-Based Ensemble Trading Agents
Feb 02, 2024



We propose the integration of sentiment analysis and deep-reinforcement learning ensemble algorithms for stock trading, and design a strategy capable of dynamically altering its employed agent given concurrent market sentiment. In particular, we create a simple-yet-effective method for extracting news sentiment and combine this with general improvements upon existing works, resulting in automated trading agents that effectively consider both qualitative market factors and quantitative stock data. We show that our approach results in a strategy that is profitable, robust, and risk-minimal -- outperforming the traditional ensemble strategy as well as single agent algorithms and market metrics. Our findings determine that the conventional practice of switching ensemble agents every fixed-number of months is sub-optimal, and that a dynamic sentiment-based framework greatly unlocks additional performance within these agents. Furthermore, as we have designed our algorithm with simplicity and efficiency in mind, we hypothesize that the transition of our method from historical evaluation towards real-time trading with live data should be relatively simple.
Learning to Fly -- a Gym Environment with PyBullet Physics for Reinforcement Learning of Multi-agent Quadcopter Control
Mar 04, 2021
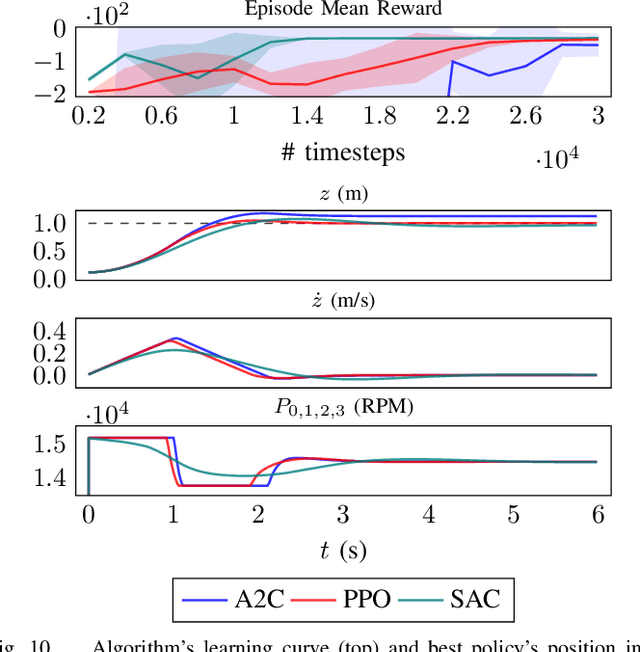
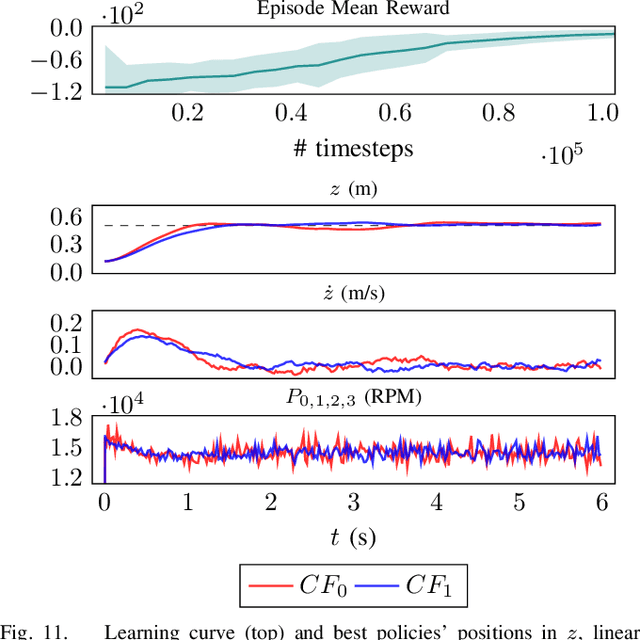
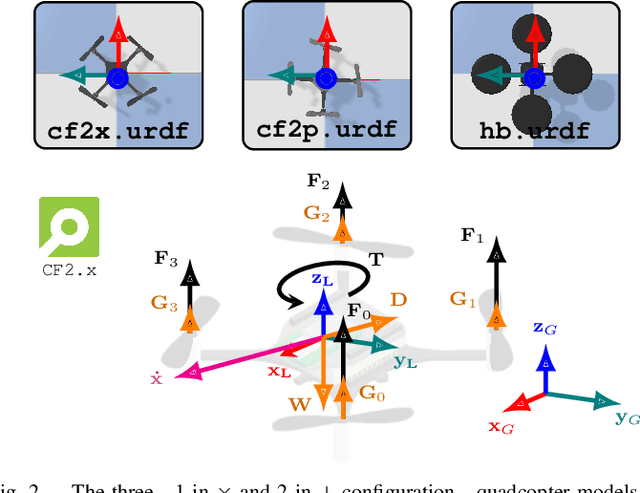
Robotic simulators are crucial for academic research and education as well as the development of safety-critical applications. Reinforcement learning environments -- simple simulations coupled with a problem specification in the form of a reward function -- are also important to standardize the development (and benchmarking) of learning algorithms. Yet, full-scale simulators typically lack portability and parallelizability. Vice versa, many reinforcement learning environments trade-off realism for high sample throughputs in toy-like problems. While public data sets have greatly benefited deep learning and computer vision, we still lack the software tools to simultaneously develop -- and fairly compare -- control theory and reinforcement learning approaches. In this paper, we propose an open-source OpenAI Gym-like environment for multiple quadcopters based on the Bullet physics engine. Its multi-agent and vision based reinforcement learning interfaces, as well as the support of realistic collisions and aerodynamic effects, make it, to the best of our knowledge, a first of its kind. We demonstrate its use through several examples, either for control (trajectory tracking with PID control, multi-robot flight with downwash, etc.) or reinforcement learning (single and multi-agent stabilization tasks), hoping to inspire future research that combines control theory and machine learning.