 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgeaerial-autonomy-stack -- a Faster-than-real-time, Autopilot-agnostic, ROS2 Framework to Simulate and Deploy Perception-based Drones
Feb 06, 2026Unmanned aerial vehicles are rapidly transforming multiple applications, from agricultural and infrastructure monitoring to logistics and defense. Introducing greater autonomy to these systems can simultaneously make them more effective as well as reliable. Thus, the ability to rapidly engineer and deploy autonomous aerial systems has become of strategic importance. In the 2010s, a combination of high-performance compute, data, and open-source software led to the current deep learning and AI boom, unlocking decades of prior theoretical work. Robotics is on the cusp of a similar transformation. However, physical AI faces unique hurdles, often combined under the umbrella term "simulation-to-reality gap". These span from modeling shortcomings to the complexity of vertically integrating the highly heterogeneous hardware and software systems typically found in field robots. To address the latter, we introduce aerial-autonomy-stack, an open-source, end-to-end framework designed to streamline the pipeline from (GPU-accelerated) perception to (flight controller-based) action. Our stack allows the development of aerial autonomy using ROS2 and provides a common interface for two of the most popular autopilots: PX4 and ArduPilot. We show that it supports over 20x faster-than-real-time, end-to-end simulation of a complete development and deployment stack -- including edge compute and networking -- significantly compressing the build-test-release cycle of perception-based autonomy.
Race Against the Machine: a Fully-annotated, Open-design Dataset of Autonomous and Piloted High-speed Flight
Nov 05, 2023



Unmanned aerial vehicles, and multi-rotors in particular, can now perform dexterous tasks in impervious environments, from infrastructure monitoring to emergency deliveries. Autonomous drone racing has emerged as an ideal benchmark to develop and evaluate these capabilities. Its challenges include accurate and robust visual-inertial odometry during aggressive maneuvers, complex aerodynamics, and constrained computational resources. As researchers increasingly channel their efforts into it, they also need the tools to timely and equitably compare their results and advances. With this dataset, we want to (i) support the development of new methods and (ii) establish quantitative comparisons for approaches coming from the broader robotics, controls, and artificial intelligence communities. We want to provide a one-stop resource that is comprehensive of (i) aggressive autonomous and piloted flight, (ii) high-resolution, high-frequency visual, inertial, and motion capture data, (iii) commands and control inputs, (iv) multiple light settings, and (v) corner-level labeling of drone racing gates. We also release the complete specifications to recreate our flight platform, using commercial off-the-shelf components and the open-source flight controller Betaflight. Our dataset, open-source scripts, and drone design are available at: https://github.com/tii-racing/drone-racing-dataset.
A Remote Sim2real Aerial Competition: Fostering Reproducibility and Solutions' Diversity in Robotics Challenges
Aug 31, 2023

Shared benchmark problems have historically been a fundamental driver of progress for scientific communities. In the context of academic conferences, competitions offer the opportunity to researchers with different origins, backgrounds, and levels of seniority to quantitatively compare their ideas. In robotics, a hot and challenging topic is sim2real-porting approaches that work well in simulation to real robot hardware. In our case, creating a hybrid competition with both simulation and real robot components was also dictated by the uncertainties around travel and logistics in the post-COVID-19 world. Hence, this article motivates and describes an aerial sim2real robot competition that ran during the 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems, from the specification of the competition task, to the details of the software infrastructure supporting simulation and real-life experiments, to the approaches of the top-placed teams and the lessons learned by participants and organizers.
What is the Impact of Releasing Code with Publications? Statistics from the Machine Learning, Robotics, and Control Communities
Aug 19, 2023Open-sourcing research publications is a key enabler for the reproducibility of studies and the collective scientific progress of a research community. As all fields of science develop more advanced algorithms, we become more dependent on complex computational toolboxes -- sharing research ideas solely through equations and proofs is no longer sufficient to communicate scientific developments. Over the past years, several efforts have highlighted the importance and challenges of transparent and reproducible research; code sharing is one of the key necessities in such efforts. In this article, we study the impact of code release on scientific research and present statistics from three research communities: machine learning, robotics, and control. We found that, over a six-year period (2016-2021), the percentages of papers with code at major machine learning, robotics, and control conferences have at least doubled. Moreover, high-impact papers were generally supported by open-source codes. As an example, the top 1% of most cited papers at the Conference on Neural Information Processing Systems (NeurIPS) consistently included open-source codes. In addition, our analysis shows that popular code repositories generally come with high paper citations, which further highlights the coupling between code sharing and the impact of scientific research. While the trends are encouraging, we would like to continue to promote and increase our efforts toward transparent, reproducible research that accelerates innovation -- releasing code with our papers is a clear first step.
Characterising the Robustness of Reinforcement Learning for Continuous Control using Disturbance Injection
Oct 27, 2022In this study, we leverage the deliberate and systematic fault-injection capabilities of an open-source benchmark suite to perform a series of experiments on state-of-the-art deep and robust reinforcement learning algorithms. We aim to benchmark robustness in the context of continuous action spaces -- crucial for deployment in robot control. We find that robustness is more prominent for action disturbances than it is for disturbances to observations and dynamics. We also observe that state-of-the-art approaches that are not explicitly designed to improve robustness perform at a level comparable to that achieved by those that are. Our study and results are intended to provide insight into the current state of safe and robust reinforcement learning and a foundation for the advancement of the field, in particular, for deployment in robotic systems.
safe-control-gym: a Unified Benchmark Suite for Safe Learning-based Control and Reinforcement Learning
Sep 18, 2021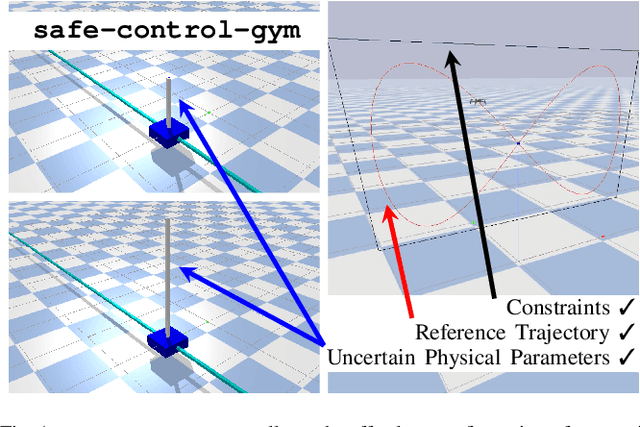
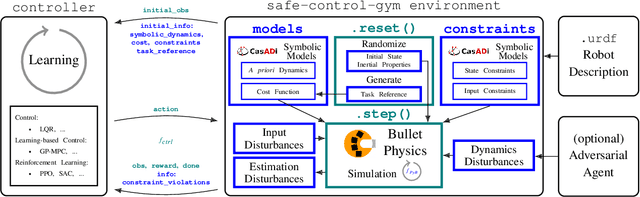
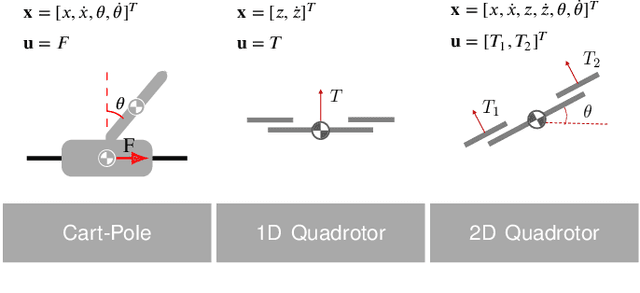
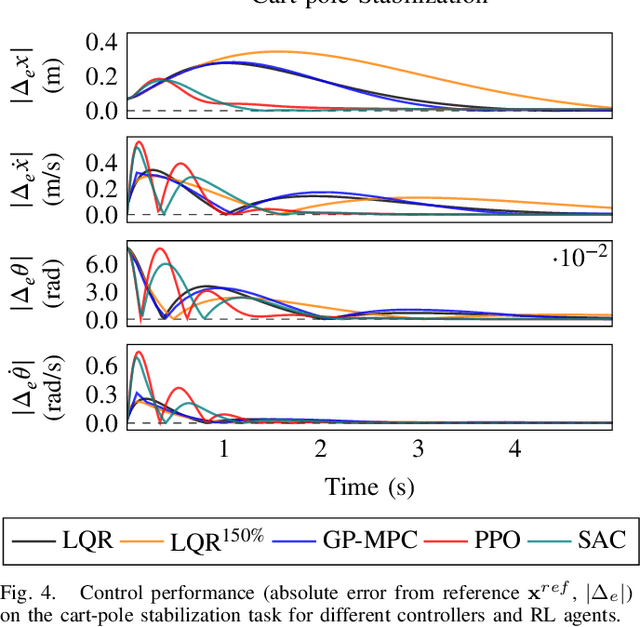
In recent years, reinforcement learning and learning-based control -- as well as the study of their safety, crucial for deployment in real-world robots -- have gained significant traction. However, to adequately gauge the progress and applicability of new results, we need the tools to equitably compare the approaches proposed by the controls and reinforcement learning communities. Here, we propose a new open-source benchmark suite, called safe-control-gym. Our starting point is OpenAI's Gym API, which is one of the de facto standard in reinforcement learning research. Yet, we highlight the reasons for its limited appeal to control theory researchers -- and safe control, in particular. E.g., the lack of analytical models and constraint specifications. Thus, we propose to extend this API with (i) the ability to specify (and query) symbolic models and constraints and (ii) introduce simulated disturbances in the control inputs, measurements, and inertial properties. We provide implementations for three dynamic systems -- the cart-pole, 1D, and 2D quadrotor -- and two control tasks -- stabilization and trajectory tracking. To demonstrate our proposal -- and in an attempt to bring research communities closer together -- we show how to use safe-control-gym to quantitatively compare the control performance, data efficiency, and safety of multiple approaches from the areas of traditional control, learning-based control, and reinforcement learning.
Safe Learning in Robotics: From Learning-Based Control to Safe Reinforcement Learning
Aug 13, 2021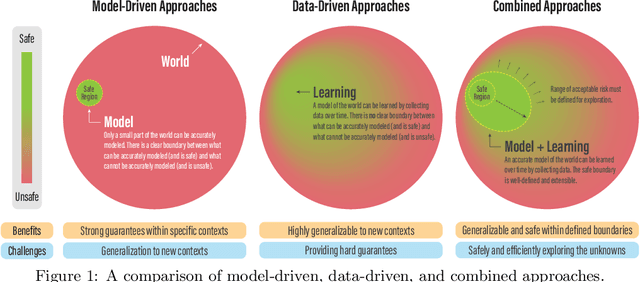
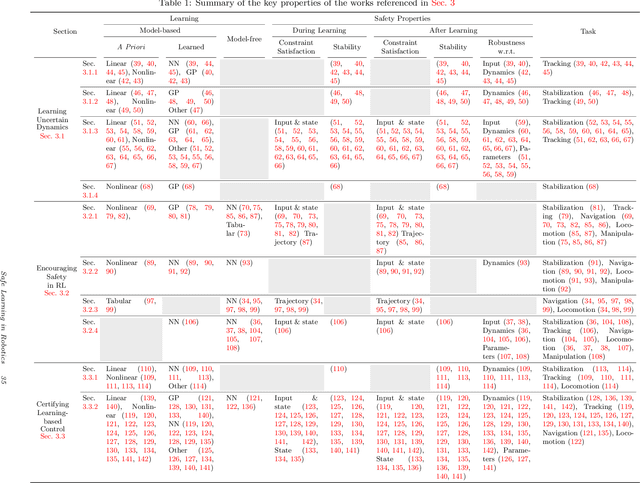
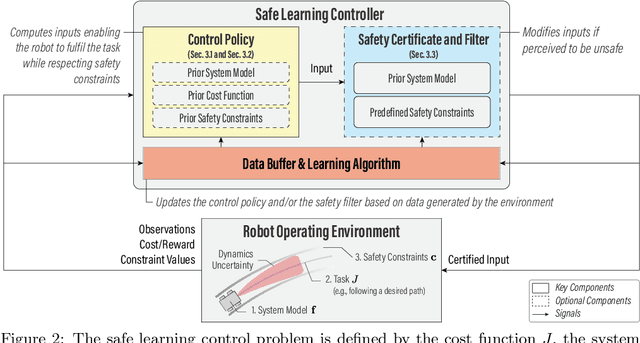
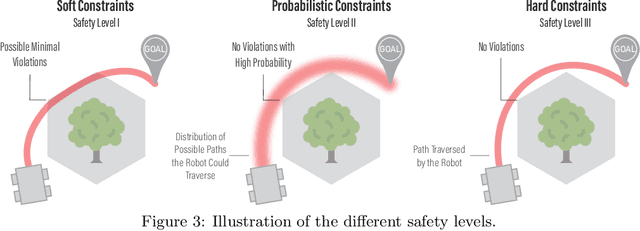
The last half-decade has seen a steep rise in the number of contributions on safe learning methods for real-world robotic deployments from both the control and reinforcement learning communities. This article provides a concise but holistic review of the recent advances made in using machine learning to achieve safe decision making under uncertainties, with a focus on unifying the language and frameworks used in control theory and reinforcement learning research. Our review includes: learning-based control approaches that safely improve performance by learning the uncertain dynamics, reinforcement learning approaches that encourage safety or robustness, and methods that can formally certify the safety of a learned control policy. As data- and learning-based robot control methods continue to gain traction, researchers must understand when and how to best leverage them in real-world scenarios where safety is imperative, such as when operating in close proximity to humans. We highlight some of the open challenges that will drive the field of robot learning in the coming years, and emphasize the need for realistic physics-based benchmarks to facilitate fair comparisons between control and reinforcement learning approaches.
Learning to Fly -- a Gym Environment with PyBullet Physics for Reinforcement Learning of Multi-agent Quadcopter Control
Mar 04, 2021
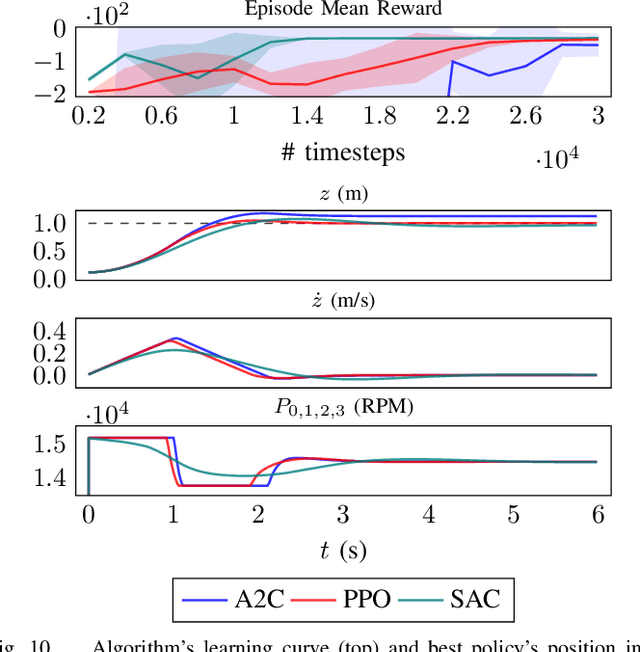
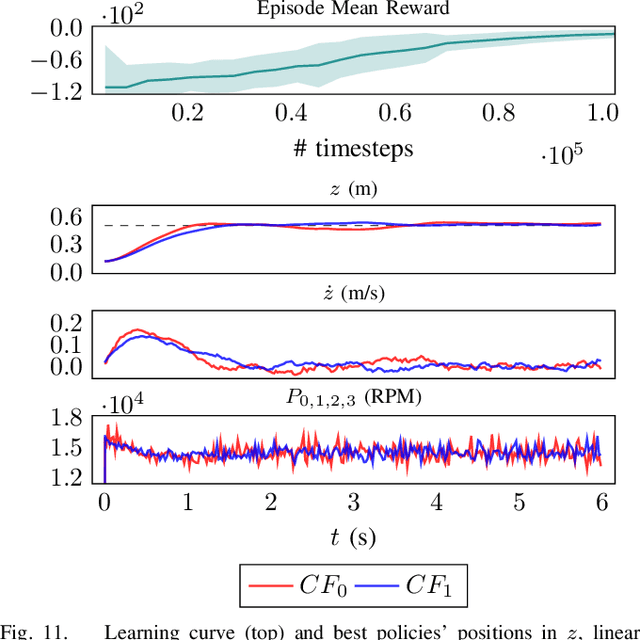
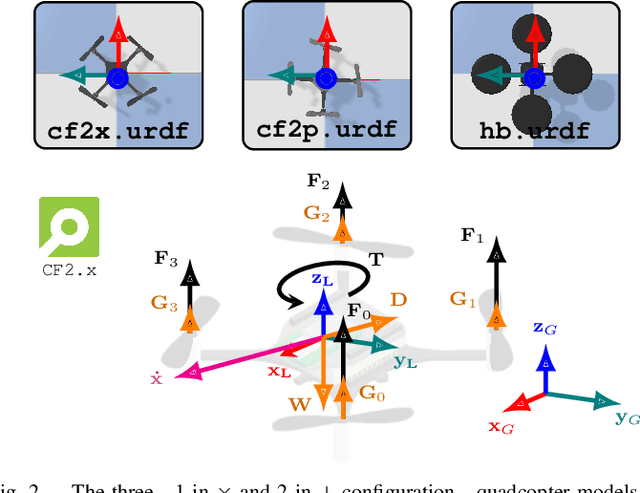
Robotic simulators are crucial for academic research and education as well as the development of safety-critical applications. Reinforcement learning environments -- simple simulations coupled with a problem specification in the form of a reward function -- are also important to standardize the development (and benchmarking) of learning algorithms. Yet, full-scale simulators typically lack portability and parallelizability. Vice versa, many reinforcement learning environments trade-off realism for high sample throughputs in toy-like problems. While public data sets have greatly benefited deep learning and computer vision, we still lack the software tools to simultaneously develop -- and fairly compare -- control theory and reinforcement learning approaches. In this paper, we propose an open-source OpenAI Gym-like environment for multiple quadcopters based on the Bullet physics engine. Its multi-agent and vision based reinforcement learning interfaces, as well as the support of realistic collisions and aerodynamic effects, make it, to the best of our knowledge, a first of its kind. We demonstrate its use through several examples, either for control (trajectory tracking with PID control, multi-robot flight with downwash, etc.) or reinforcement learning (single and multi-agent stabilization tasks), hoping to inspire future research that combines control theory and machine learning.
Learning-based Bias Correction for Time Difference of Arrival Ultra-wideband Localization of Resource-constrained Mobile Robots
Mar 02, 2021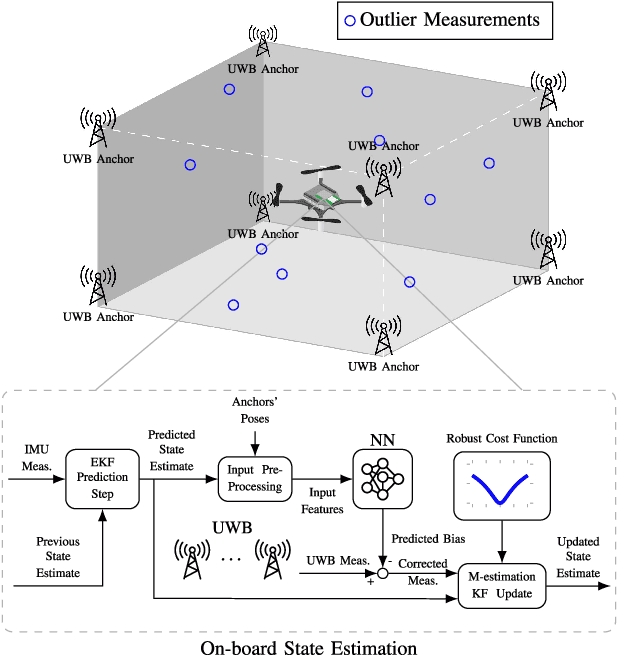
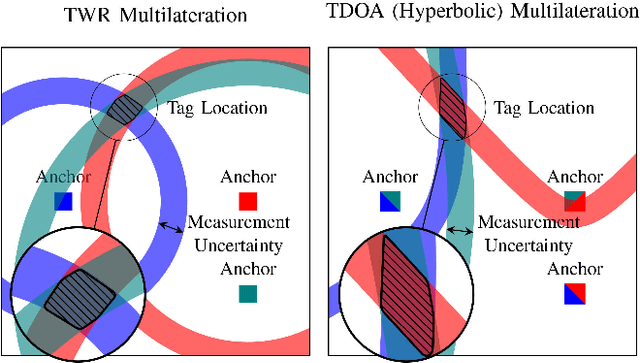

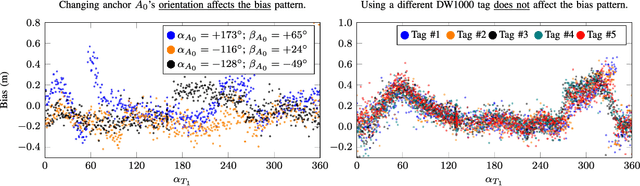
Accurate indoor localization is a crucial enabling technology for many robotics applications, from warehouse management to monitoring tasks. Ultra-wideband (UWB) time difference of arrival (TDOA)-based localization is a promising lightweight, low-cost solution that can scale to a large number of devices -- making it especially suited for resource-constrained multi-robot applications. However, the localization accuracy of standard, commercially available UWB radios is often insufficient due to significant measurement bias and outliers. In this letter, we address these issues by proposing a robust UWB TDOA localization framework comprising of (i) learning-based bias correction and (ii) M-estimation-based robust filtering to handle outliers. The key properties of our approach are that (i) the learned biases generalize to different UWB anchor setups and (ii) the approach is computationally efficient enough to run on resource-constrained hardware. We demonstrate our approach on a Crazyflie nano-quadcopter. Experimental results show that the proposed localization framework, relying only on the onboard IMU and UWB, provides an average of 42.08 percent localization error reduction (in three different anchor setups) compared to the baseline approach without bias compensation. {We also show autonomous trajectory tracking on a quadcopter using our UWB TDOA localization approach.}
Learning-based Bias Correction for Ultra-wideband Localization of Resource-constrained Mobile Robots
Mar 20, 2020
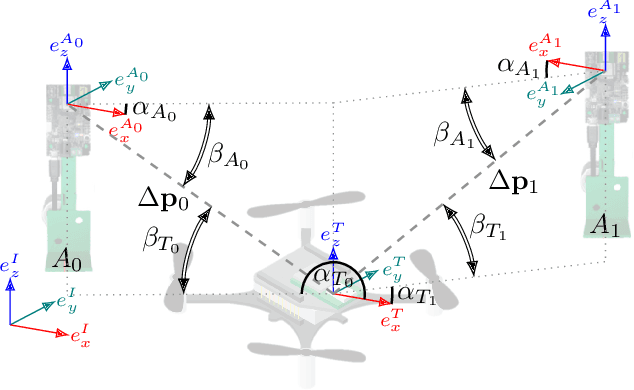
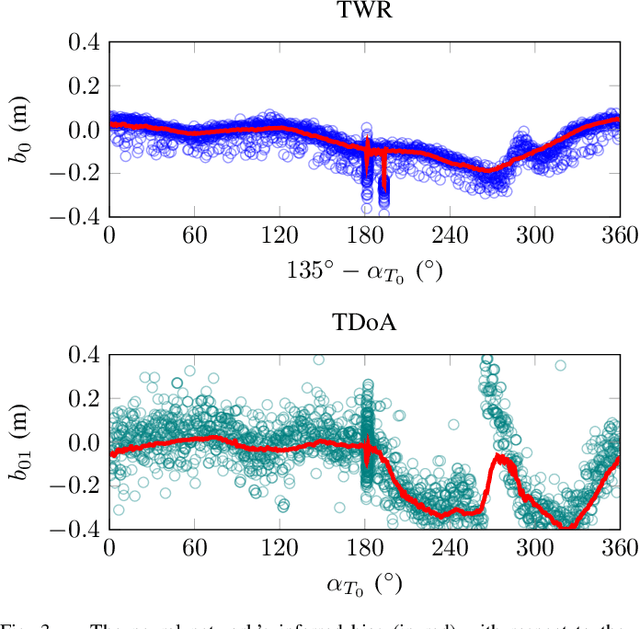
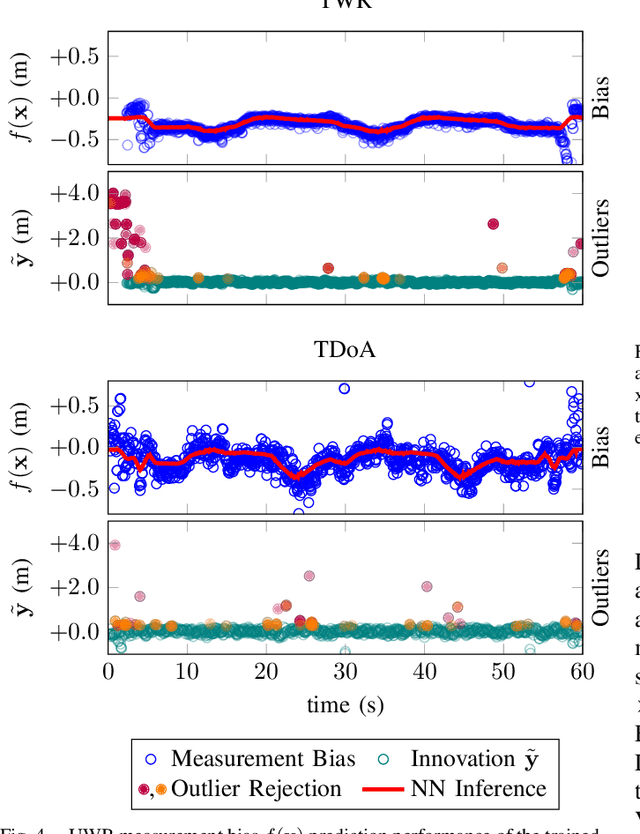
Accurate indoor localization is a crucial enabling technology for many robotics applications, from warehouse management to monitoring tasks. Ultra-wideband (UWB) ranging is a promising solution which is low-cost, lightweight, and computationally inexpensive compared to alternative state-of-the-art approaches such as simultaneous localization and mapping, making it especially suited for resource-constrained aerial robots. Many commercially-available ultra-wideband radios, however, provide inaccurate, biased range measurements. In this article, we propose a bias correction framework compatible with both two-way ranging and time difference of arrival ultra-wideband localization. Our method comprises of two steps: (i) statistical outlier rejection and (ii) a learning-based bias correction. This approach is scalable and frugal enough to be deployed on-board a nano-quadcopter's microcontroller. Previous research mostly focused on two-way ranging bias correction and has not been implemented in closed-loop nor using resource-constrained robots. Experimental results show that, using our approach, the localization error is reduced by ~18.5% and 48% (for TWR and TDoA, respectively), and a quadcopter can accurately track trajectories with position information from UWB only.