 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-Constrained Denoising Autoencoders for Data-Scarce Wildfire UAV Sensing
Jan 16, 2026Wildfire monitoring requires high-resolution atmospheric measurements, yet low-cost sensors on Unmanned Aerial Vehicles (UAVs) exhibit baseline drift, cross-sensitivity, and response lag that corrupt concentration estimates. Traditional deep learning denoising approaches demand large datasets impractical to obtain from limited UAV flight campaigns. We present PC$^2$DAE, a physics-informed denoising autoencoder that addresses data scarcity by embedding physical constraints directly into the network architecture. Non-negative concentration estimates are enforced via softplus activations and physically plausible temporal smoothing, ensuring outputs are physically admissible by construction rather than relying on loss function penalties. The architecture employs hierarchical decoder heads for Black Carbon, Gas, and CO$_2$ sensor families, with two variants: PC$^2$DAE-Lean (21k parameters) for edge deployment and PC$^2$DAE-Wide (204k parameters) for offline processing. We evaluate on 7,894 synchronized 1 Hz samples collected from UAV flights during prescribed burns in Saskatchewan, Canada (approximately 2.2 hours of flight data), two orders of magnitude below typical deep learning requirements. PC$^2$DAE-Lean achieves 67.3\% smoothness improvement and 90.7\% high-frequency noise reduction with zero physics violations. Five baselines (LSTM-AE, U-Net, Transformer, CBDAE, DeSpaWN) produce 15--23\% negative outputs. The lean variant outperforms wide (+5.6\% smoothness), suggesting reduced capacity with strong inductive bias prevents overfitting in data-scarce regimes. Training completes in under 65 seconds on consumer hardware.
UAV See, UGV Do: Aerial Imagery and Virtual Teach Enabling Zero-Shot Ground Vehicle Repeat
May 22, 2025This paper presents Virtual Teach and Repeat (VirT&R): an extension of the Teach and Repeat (T&R) framework that enables GPS-denied, zero-shot autonomous ground vehicle navigation in untraversed environments. VirT&R leverages aerial imagery captured for a target environment to train a Neural Radiance Field (NeRF) model so that dense point clouds and photo-textured meshes can be extracted. The NeRF mesh is used to create a high-fidelity simulation of the environment for piloting an unmanned ground vehicle (UGV) to virtually define a desired path. The mission can then be executed in the actual target environment by using NeRF-derived point cloud submaps associated along the path and an existing LiDAR Teach and Repeat (LT&R) framework. We benchmark the repeatability of VirT&R on over 12 km of autonomous driving data using physical markings that allow a sim-to-real lateral path-tracking error to be obtained and compared with LT&R. VirT&R achieved measured root mean squared errors (RMSE) of 19.5 cm and 18.4 cm in two different environments, which are slightly less than one tire width (24 cm) on the robot used for testing, and respective maximum errors were 39.4 cm and 47.6 cm. This was done using only the NeRF-derived teach map, demonstrating that VirT&R has similar closed-loop path-tracking performance to LT&R but does not require a human to manually teach the path to the UGV in the actual environment.
Bistable SMA-driven engine for pulse-jet locomotion in soft aquatic robots
Apr 04, 2025This paper presents the design and experimental validation of a bio-inspired soft aquatic robot, the DilBot, which uses a bistable shape memory alloy-driven engine for pulse-jet locomotion. Drawing inspiration from the efficient swimming mechanisms of box jellyfish, the DilBot incorporates antagonistic shape memory alloy springs encapsulated in silicone insulation to achieve high-power propulsion. The innovative bistable mechanism allows continuous swimming cycles by storing and releasing energy in a controlled manner. Through free-swimming experiments and force characterization tests, we evaluated the DilBot's performance, achieving a peak speed of 158 mm/s and generating a maximum thrust of 5.59 N. This work demonstrates a novel approach to enhancing the efficiency of shape memory alloy actuators in aquatic environments. It presents a promising pathway for future applications in underwater environmental monitoring using robotic swarms.
Evaluation of Flight Parameters in UAV-based 3D Reconstruction for Rooftop Infrastructure Assessment
Apr 02, 2025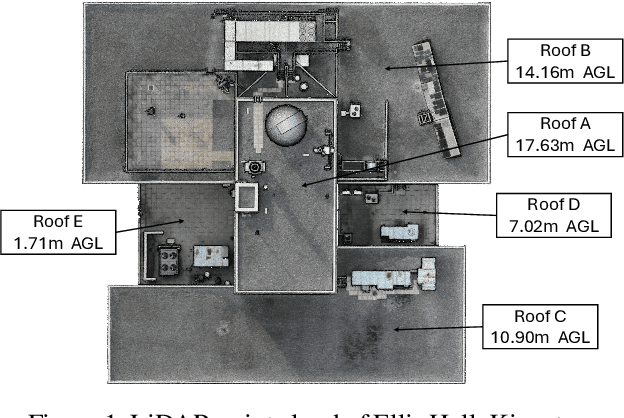
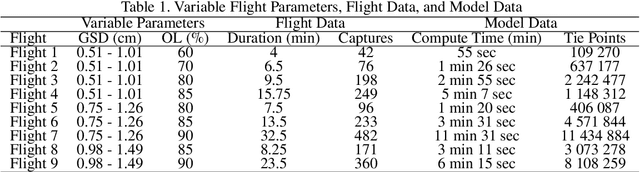


Rooftop 3D reconstruction using UAV-based photogrammetry offers a promising solution for infrastructure assessment, but existing methods often require high percentages of image overlap and extended flight times to ensure model accuracy when using autonomous flight paths. This study systematically evaluates key flight parameters-ground sampling distance (GSD) and image overlap-to optimize the 3D reconstruction of complex rooftop infrastructure. Controlled UAV flights were conducted over a multi-segment rooftop at Queen's University using a DJI Phantom 4 Pro V2, with varied GSD and overlap settings. The collected data were processed using Reality Capture software and evaluated against ground truth models generated from UAV-based LiDAR and terrestrial laser scanning (TLS). Experimental results indicate that a GSD range of 0.75-1.26 cm combined with 85% image overlap achieves a high degree of model accuracy, while minimizing images collected and flight time. These findings provide guidance for planning autonomous UAV flight paths for efficient rooftop assessments.
Tiny Learning-Based MPC for Multirotors: Solver-Aware Learning for Efficient Embedded Predictive Control
Oct 31, 2024
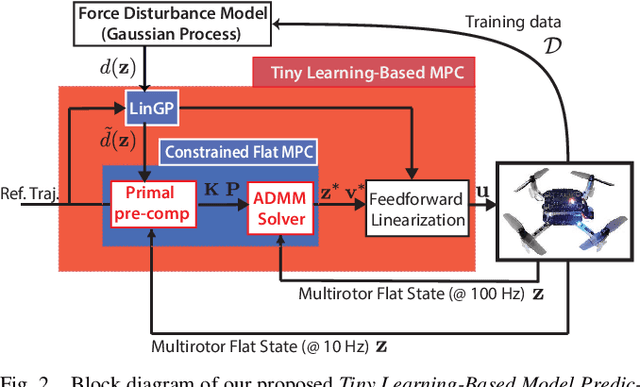
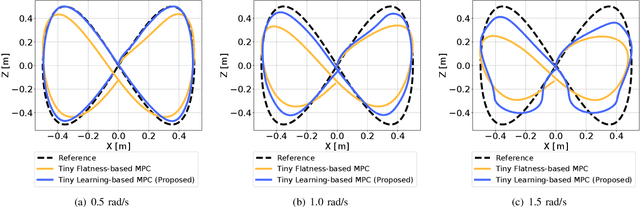
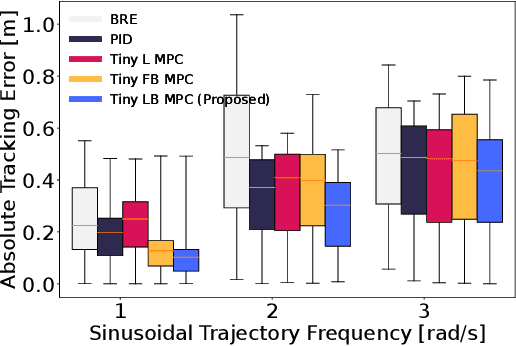
Tiny aerial robots show promise for applications like environmental monitoring and search-and-rescue but face challenges in control due to their limited computing power and complex dynamics. Model Predictive Control (MPC) can achieve agile trajectory tracking and handle constraints. Although current learning-based MPC methods, such as Gaussian Process (GP) MPC, improve control performance by learning residual dynamics, they are computationally demanding, limiting their onboard application on tiny robots. This paper introduces Tiny Learning-Based Model Predictive Control (LB MPC), a novel framework for resource-constrained micro multirotor platforms. By exploiting multirotor dynamics' structure and developing an efficient solver, our approach enables high-rate control at 100 Hz on a Crazyflie 2.1 with a Teensy 4.0 microcontroller. We demonstrate a 23\% average improvement in tracking performance over existing embedded MPC methods, achieving the first onboard implementation of learning-based MPC on a tiny multirotor (53 g).
A Time and Place to Land: Online Learning-Based Distributed MPC for Multirotor Landing on Surface Vessel in Waves
Oct 29, 2024Landing a multirotor unmanned aerial vehicle (UAV) on an uncrewed surface vessel (USV) extends the operational range and offers recharging capabilities for maritime and limnology applications, such as search-and-rescue and environmental monitoring. However, autonomous UAV landings on USVs are challenging due to the unpredictable tilt and motion of the vessel caused by waves. This movement introduces spatial and temporal uncertainties, complicating safe, precise landings. Existing autonomous landing techniques on unmanned ground vehicles (UGVs) rely on shared state information, often causing time delays due to communication limits. This paper introduces a learning-based distributed Model Predictive Control (MPC) framework for autonomous UAV landings on USVs in wave-like conditions. Each vehicle's MPC optimizes for an artificial goal and input, sharing only the goal with the other vehicle. These goals are penalized by coupling and platform tilt costs, learned as a Gaussian Process (GP). We validate our framework in comprehensive indoor experiments using a custom-designed platform attached to a UGV to simulate USV tilting motion. Our approach achieves a 53% increase in landing success compared to an approach that neglects the impact of tilt motion on landing.
Distributed Model Predictive Control for Cooperative Multirotor Landing on Uncrewed Surface Vessel in Waves
Feb 16, 2024



Heterogeneous autonomous robot teams consisting of multirotor and uncrewed surface vessels (USVs) have the potential to enable various maritime applications, including advanced search-and-rescue operations. A critical requirement of these applications is the ability to land a multirotor on a USV for tasks such as recharging. This paper addresses the challenge of safely landing a multirotor on a cooperative USV in harsh open waters. To tackle this problem, we propose a novel sequential distributed model predictive control (MPC) scheme for cooperative multirotor-USV landing. Our approach combines standard tracking MPCs for the multirotor and USV with additional artificial intermediate goal locations. These artificial goals enable the robots to coordinate their cooperation without prior guidance. Each vehicle solves an individual optimization problem for both the artificial goal and an input that tracks it but only communicates the former to the other vehicle. The artificial goals are penalized by a suitable coupling cost. Furthermore, our proposed distributed MPC scheme utilizes a spatial-temporal wave model to coordinate in real-time a safer landing location and time the multirotor's landing to limit severe tilt of the USV.
A Computationally Efficient Learning-Based Model Predictive Control for Multirotors under Aerodynamic Disturbances
Feb 15, 2024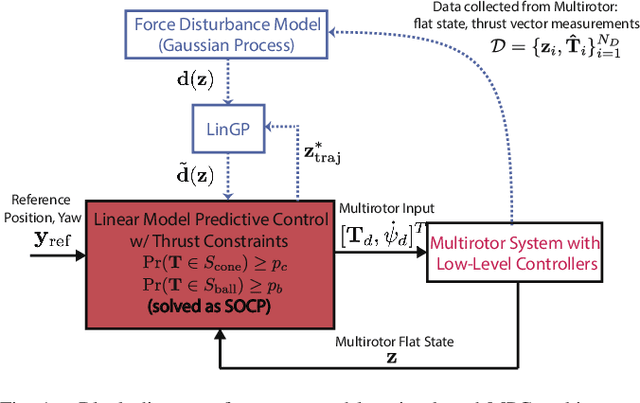
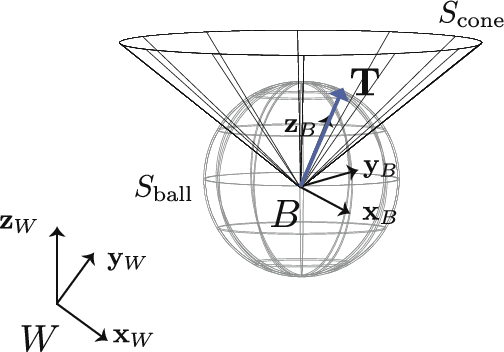
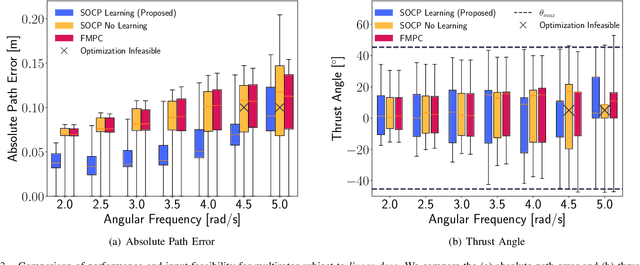
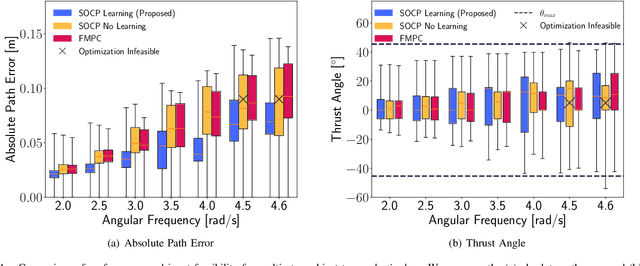
Neglecting complex aerodynamic effects hinders high-speed yet high-precision multirotor autonomy. In this paper, we present a computationally efficient learning-based model predictive controller that simultaneously optimizes a trajectory that can be tracked within the physical limits (on thrust and orientation) of the multirotor system despite unknown aerodynamic forces and adapts the control input. To do this, we leverage the well-known differential flatness property of multirotors, which allows us to transform their nonlinear dynamics into a linear model. The main limitation of current flatness-based planning and control approaches is that they often neglect dynamic feasibility. This is because these constraints are nonlinear as a result of the mapping between the input, i.e., multirotor thrust, and the flat state. In our approach, we learn a novel representation of the drag forces by learning the mapping from the flat state to the multirotor thrust vector (in a world frame) as a Gaussian Process (GP). Our proposed approach leverages the properties of GPs to develop a convex optimal controller that can be iteratively solved as a second-order cone program (SOCP). In simulation experiments, our proposed approach outperforms related model predictive controllers that do not account for aerodynamic effects on trajectory feasibility, leading to a reduction of up to 55% in absolute tracking error.
A Remote Sim2real Aerial Competition: Fostering Reproducibility and Solutions' Diversity in Robotics Challenges
Aug 31, 2023

Shared benchmark problems have historically been a fundamental driver of progress for scientific communities. In the context of academic conferences, competitions offer the opportunity to researchers with different origins, backgrounds, and levels of seniority to quantitatively compare their ideas. In robotics, a hot and challenging topic is sim2real-porting approaches that work well in simulation to real robot hardware. In our case, creating a hybrid competition with both simulation and real robot components was also dictated by the uncertainties around travel and logistics in the post-COVID-19 world. Hence, this article motivates and describes an aerial sim2real robot competition that ran during the 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems, from the specification of the competition task, to the details of the software infrastructure supporting simulation and real-life experiments, to the approaches of the top-placed teams and the lessons learned by participants and organizers.
Differentially Flat Learning-based Model Predictive Control Using a Stability, State, and Input Constraining Safety Filter
Jul 20, 2023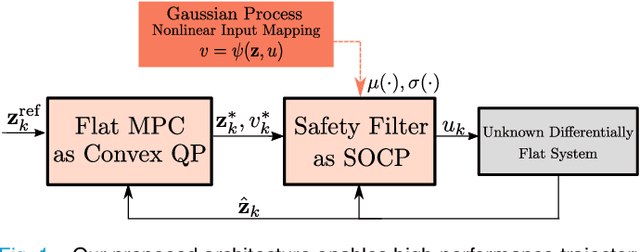

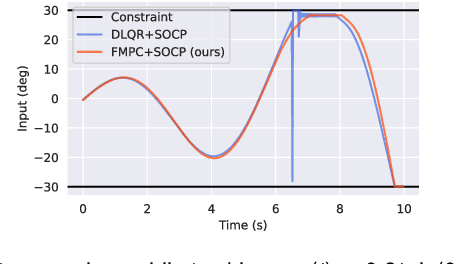
Learning-based optimal control algorithms control unknown systems using past trajectory data and a learned model of the system dynamics. These controllers use either a linear approximation of the learned dynamics, trading performance for faster computation, or nonlinear optimization methods, which typically perform better but can limit real-time applicability. In this work, we present a novel nonlinear controller that exploits differential flatness to achieve similar performance to state-of-the-art learning-based controllers but with significantly less computational effort. Differential flatness is a property of dynamical systems whereby nonlinear systems can be exactly linearized through a nonlinear input mapping. Here, the nonlinear transformation is learned as a Gaussian process and is used in a safety filter that guarantees, with high probability, stability as well as input and flat state constraint satisfaction. This safety filter is then used to refine inputs from a flat model predictive controller to perform constrained nonlinear learning-based optimal control through two successive convex optimizations. We compare our method to state-of-the-art learning-based control strategies and achieve similar performance, but with significantly better computational efficiency, while also respecting flat state and input constraints, and guaranteeing stability.
* 6 pages, 5 figures, Published in IEEE Control Systems Letters