 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat is the Impact of Releasing Code with Publications? Statistics from the Machine Learning, Robotics, and Control Communities
Aug 19, 2023Open-sourcing research publications is a key enabler for the reproducibility of studies and the collective scientific progress of a research community. As all fields of science develop more advanced algorithms, we become more dependent on complex computational toolboxes -- sharing research ideas solely through equations and proofs is no longer sufficient to communicate scientific developments. Over the past years, several efforts have highlighted the importance and challenges of transparent and reproducible research; code sharing is one of the key necessities in such efforts. In this article, we study the impact of code release on scientific research and present statistics from three research communities: machine learning, robotics, and control. We found that, over a six-year period (2016-2021), the percentages of papers with code at major machine learning, robotics, and control conferences have at least doubled. Moreover, high-impact papers were generally supported by open-source codes. As an example, the top 1% of most cited papers at the Conference on Neural Information Processing Systems (NeurIPS) consistently included open-source codes. In addition, our analysis shows that popular code repositories generally come with high paper citations, which further highlights the coupling between code sharing and the impact of scientific research. While the trends are encouraging, we would like to continue to promote and increase our efforts toward transparent, reproducible research that accelerates innovation -- releasing code with our papers is a clear first step.
Differentially Flat Learning-based Model Predictive Control Using a Stability, State, and Input Constraining Safety Filter
Jul 20, 2023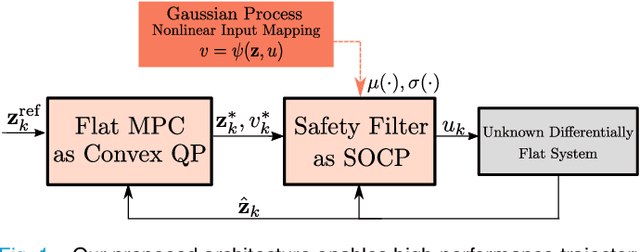

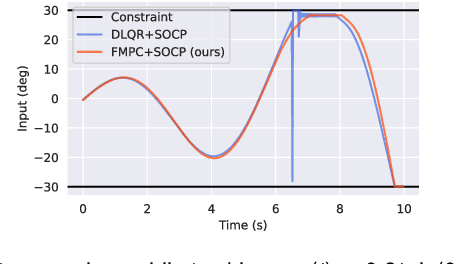
Learning-based optimal control algorithms control unknown systems using past trajectory data and a learned model of the system dynamics. These controllers use either a linear approximation of the learned dynamics, trading performance for faster computation, or nonlinear optimization methods, which typically perform better but can limit real-time applicability. In this work, we present a novel nonlinear controller that exploits differential flatness to achieve similar performance to state-of-the-art learning-based controllers but with significantly less computational effort. Differential flatness is a property of dynamical systems whereby nonlinear systems can be exactly linearized through a nonlinear input mapping. Here, the nonlinear transformation is learned as a Gaussian process and is used in a safety filter that guarantees, with high probability, stability as well as input and flat state constraint satisfaction. This safety filter is then used to refine inputs from a flat model predictive controller to perform constrained nonlinear learning-based optimal control through two successive convex optimizations. We compare our method to state-of-the-art learning-based control strategies and achieve similar performance, but with significantly better computational efficiency, while also respecting flat state and input constraints, and guaranteeing stability.
* 6 pages, 5 figures, Published in IEEE Control Systems Letters
safe-control-gym: a Unified Benchmark Suite for Safe Learning-based Control and Reinforcement Learning
Sep 18, 2021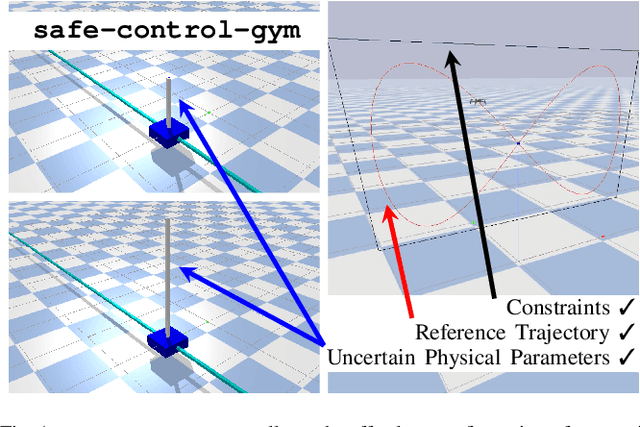
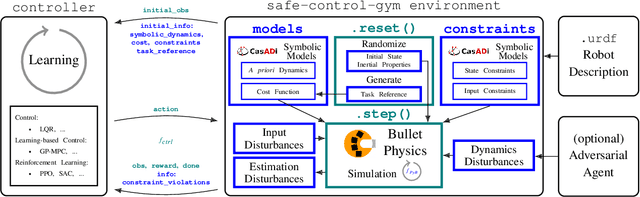
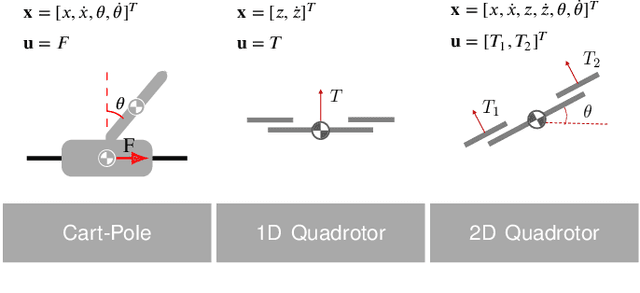
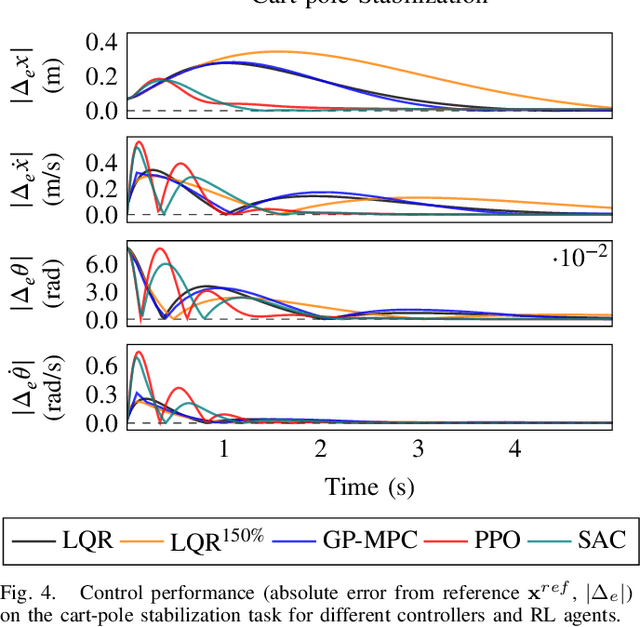
In recent years, reinforcement learning and learning-based control -- as well as the study of their safety, crucial for deployment in real-world robots -- have gained significant traction. However, to adequately gauge the progress and applicability of new results, we need the tools to equitably compare the approaches proposed by the controls and reinforcement learning communities. Here, we propose a new open-source benchmark suite, called safe-control-gym. Our starting point is OpenAI's Gym API, which is one of the de facto standard in reinforcement learning research. Yet, we highlight the reasons for its limited appeal to control theory researchers -- and safe control, in particular. E.g., the lack of analytical models and constraint specifications. Thus, we propose to extend this API with (i) the ability to specify (and query) symbolic models and constraints and (ii) introduce simulated disturbances in the control inputs, measurements, and inertial properties. We provide implementations for three dynamic systems -- the cart-pole, 1D, and 2D quadrotor -- and two control tasks -- stabilization and trajectory tracking. To demonstrate our proposal -- and in an attempt to bring research communities closer together -- we show how to use safe-control-gym to quantitatively compare the control performance, data efficiency, and safety of multiple approaches from the areas of traditional control, learning-based control, and reinforcement learning.
Riemannian Optimization for Distance Geometric Inverse Kinematics
Aug 31, 2021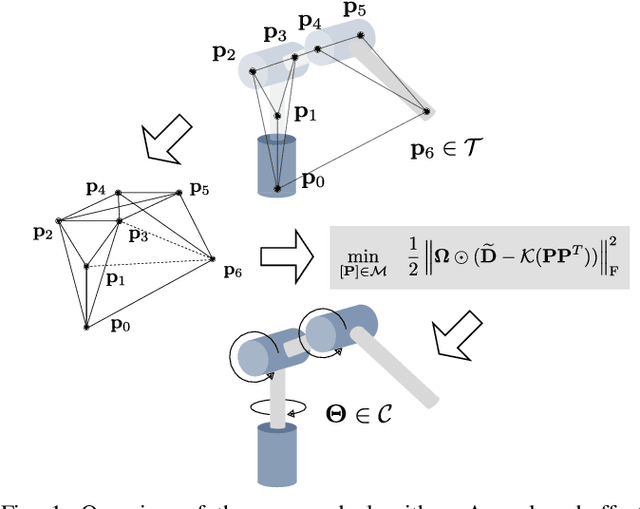
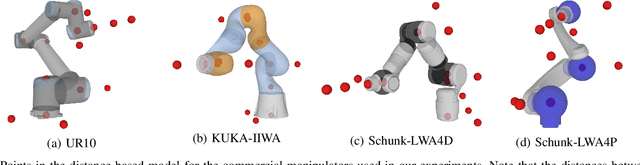
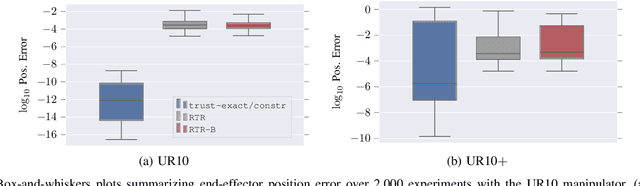
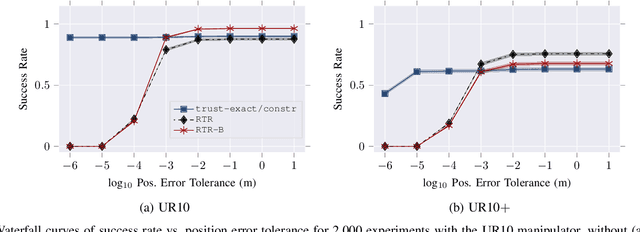
Solving the inverse kinematics problem is a fundamental challenge in motion planning, control, and calibration for articulated robots. Kinematic models for these robots are typically parameterized by joint angles, generating a complicated mapping between a robot's configuration and end-effector pose. Alternatively, the kinematic model and task constraints can be represented using invariant distances between points attached to the robot. In this paper, we formalize the equivalence of distance-based inverse kinematics and the distance geometry problem for a large class of articulated robots and task constraints. Unlike previous approaches, we use the connection between distance geometry and low-rank matrix completion to find inverse kinematics solutions by completing a partial Euclidean distance matrix through local optimization. Furthermore, we parameterize the space of Euclidean distance matrices with the Riemannian manifold of fixed-rank Gram matrices, allowing us to leverage a variety of mature Riemannian optimization methods. Finally, we show that bound smoothing can be used to generate informed initializations without significant computational overhead, improving convergence. We demonstrate that our novel inverse kinematics solver achieves higher success rates than traditional techniques, and significantly outperforms them on problems that involve many workspace constraints.
Safe Learning in Robotics: From Learning-Based Control to Safe Reinforcement Learning
Aug 13, 2021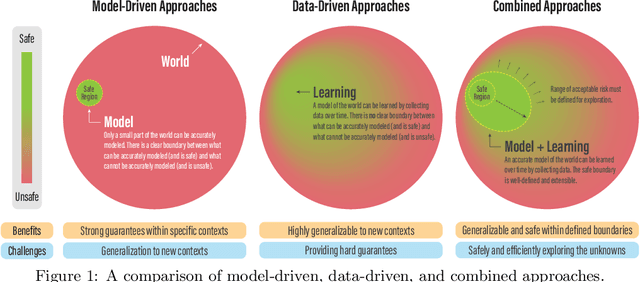
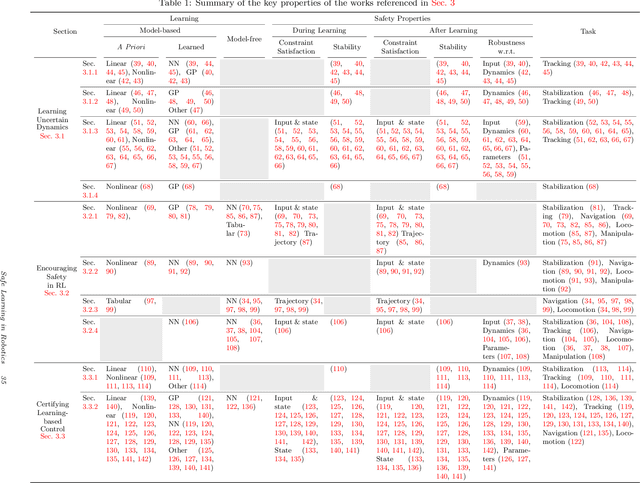
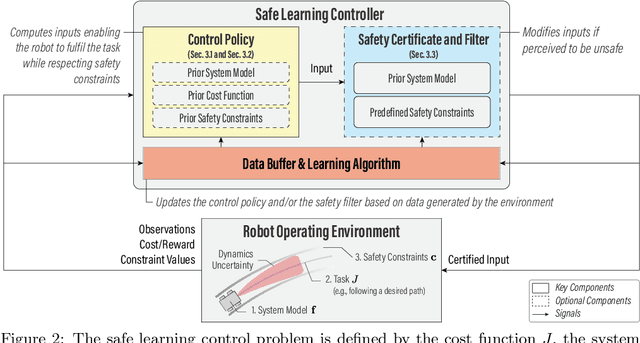
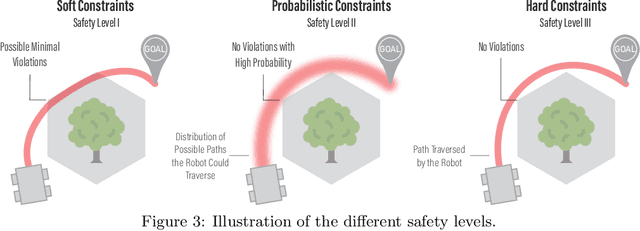
The last half-decade has seen a steep rise in the number of contributions on safe learning methods for real-world robotic deployments from both the control and reinforcement learning communities. This article provides a concise but holistic review of the recent advances made in using machine learning to achieve safe decision making under uncertainties, with a focus on unifying the language and frameworks used in control theory and reinforcement learning research. Our review includes: learning-based control approaches that safely improve performance by learning the uncertain dynamics, reinforcement learning approaches that encourage safety or robustness, and methods that can formally certify the safety of a learned control policy. As data- and learning-based robot control methods continue to gain traction, researchers must understand when and how to best leverage them in real-world scenarios where safety is imperative, such as when operating in close proximity to humans. We highlight some of the open challenges that will drive the field of robot learning in the coming years, and emphasize the need for realistic physics-based benchmarks to facilitate fair comparisons between control and reinforcement learning approaches.