 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSQ-CBF: Signed Distance Functions for Numerically Stable Superquadric-Based Safety Filtering
Feb 11, 2026Ensuring safe robot operation in cluttered and dynamic environments remains a fundamental challenge. While control barrier functions provide an effective framework for real-time safety filtering, their performance critically depends on the underlying geometric representation, which is often simplified, leading to either overly conservative behavior or insufficient collision coverage. Superquadrics offer an expressive way to model complex shapes using a few primitives and are increasingly used for robot safety. To integrate this representation into collision avoidance, most existing approaches directly use their implicit functions as barrier candidates. However, we identify a critical but overlooked issue in this practice: the gradients of the implicit SQ function can become severely ill-conditioned, potentially rendering the optimization infeasible and undermining reliable real-time safety filtering. To address this issue, we formulate an SQ-based safety filtering framework that uses signed distance functions as barrier candidates. Since analytical SDFs are unavailable for general SQs, we compute distances using the efficient Gilbert-Johnson-Keerthi algorithm and obtain gradients via randomized smoothing. Extensive simulation and real-world experiments demonstrate consistent collision-free manipulation in cluttered and unstructured scenes, showing robustness to challenging geometries, sensing noise, and dynamic disturbances, while improving task efficiency in teleoperation tasks. These results highlight a pathway toward safety filters that remain precise and reliable under the geometric complexity of real-world environments.
Addressing Relative Degree Issues in Control Barrier Function Synthesis with Physics-Informed Neural Networks
Apr 08, 2025



In robotics, control barrier function (CBF)-based safety filters are commonly used to enforce state constraints. A critical challenge arises when the relative degree of the CBF varies across the state space. This variability can create regions within the safe set where the control input becomes unconstrained. When implemented as a safety filter, this may result in chattering near the safety boundary and ultimately compromise system safety. To address this issue, we propose a novel approach for CBF synthesis by formulating it as solving a set of boundary value problems. The solutions to the boundary value problems are determined using physics-informed neural networks (PINNs). Our approach ensures that the synthesized CBFs maintain a constant relative degree across the set of admissible states, thereby preventing unconstrained control scenarios. We illustrate the approach in simulation and further verify it through real-world quadrotor experiments, demonstrating its effectiveness in preserving desired system safety properties.
Semantically Safe Robot Manipulation: From Semantic Scene Understanding to Motion Safeguards
Oct 19, 2024



Ensuring safe interactions in human-centric environments requires robots to understand and adhere to constraints recognized by humans as "common sense" (e.g., "moving a cup of water above a laptop is unsafe as the water may spill" or "rotating a cup of water is unsafe as it can lead to pouring its content"). Recent advances in computer vision and machine learning have enabled robots to acquire a semantic understanding of and reason about their operating environments. While extensive literature on safe robot decision-making exists, semantic understanding is rarely integrated into these formulations. In this work, we propose a semantic safety filter framework to certify robot inputs with respect to semantically defined constraints (e.g., unsafe spatial relationships, behaviours, and poses) and geometrically defined constraints (e.g., environment-collision and self-collision constraints). In our proposed approach, given perception inputs, we build a semantic map of the 3D environment and leverage the contextual reasoning capabilities of large language models to infer semantically unsafe conditions. These semantically unsafe conditions are then mapped to safe actions through a control barrier certification formulation. We evaluated our semantic safety filter approach in teleoperated tabletop manipulation tasks and pick-and-place tasks, demonstrating its effectiveness in incorporating semantic constraints to ensure safe robot operation beyond collision avoidance.
Safety Filtering While Training: Improving the Performance and Sample Efficiency of Reinforcement Learning Agents
Oct 15, 2024Reinforcement learning (RL) controllers are flexible and performant but rarely guarantee safety. Safety filters impart hard safety guarantees to RL controllers while maintaining flexibility. However, safety filters can cause undesired behaviours due to the separation between the controller and the safety filter, often degrading performance and robustness. In this paper, we propose several modifications to incorporating the safety filter in training RL controllers rather than solely applying it during evaluation. The modifications allow the RL controller to learn to account for the safety filter, improving performance. Additionally, our modifications significantly improve sample efficiency and eliminate training-time constraint violations. We verified the proposed modifications in simulated and real experiments with a Crazyflie 2.0 drone. In experiments, we show that the proposed training approaches require significantly fewer environment interactions and improve performance by up to 20% compared to standard RL training.
Is Data All That Matters? The Role of Control Frequency for Learning-Based Sampled-Data Control of Uncertain Systems
Mar 14, 2024Learning models or control policies from data has become a powerful tool to improve the performance of uncertain systems. While a strong focus has been placed on increasing the amount and quality of data to improve performance, data can never fully eliminate uncertainty, making feedback necessary to ensure stability and performance. We show that the control frequency at which the input is recalculated is a crucial design parameter, yet it has hardly been considered before. We address this gap by combining probabilistic model learning and sampled-data control. We use Gaussian processes (GPs) to learn a continuous-time model and compute a corresponding discrete-time controller. The result is an uncertain sampled-data control system, for which we derive robust stability conditions. We formulate semidefinite programs to compute the minimum control frequency required for stability and to optimize performance. As a result, our approach enables us to study the effect of both control frequency and data on stability and closed-loop performance. We show in numerical simulations of a quadrotor that performance can be improved by increasing either the amount of data or the control frequency, and that we can trade off one for the other. For example, by increasing the control frequency by 33%, we can reduce the number of data points by half while still achieving similar performance.
Optimized Control Invariance Conditions for Uncertain Input-Constrained Nonlinear Control Systems
Dec 15, 2023Providing safety guarantees for learning-based controllers is important for real-world applications. One approach to realizing safety for arbitrary control policies is safety filtering. If necessary, the filter modifies control inputs to ensure that the trajectories of a closed-loop system stay within a given state constraint set for all future time, referred to as the set being positive invariant or the system being safe. Under the assumption of fully known dynamics, safety can be certified using control barrier functions (CBFs). However, the dynamics model is often either unknown or only partially known in practice. Learning-based methods have been proposed to approximate the CBF condition for unknown or uncertain systems from data; however, these techniques do not account for input constraints and, as a result, may not yield a valid CBF condition to render the safe set invariant. In this work, we study conditions that guarantee control invariance of the system under input constraints and propose an optimization problem to reduce the conservativeness of CBF-based safety filters. Building on these theoretical insights, we further develop a probabilistic learning approach that allows us to build a safety filter that guarantees safety for uncertain, input-constrained systems with high probability. We demonstrate the efficacy of our proposed approach in simulation and real-world experiments on a quadrotor and show that we can achieve safe closed-loop behavior for a learned system while satisfying state and input constraints.
Swarm-GPT: Combining Large Language Models with Safe Motion Planning for Robot Choreography Design
Dec 02, 2023



This paper presents Swarm-GPT, a system that integrates large language models (LLMs) with safe swarm motion planning - offering an automated and novel approach to deployable drone swarm choreography. Swarm-GPT enables users to automatically generate synchronized drone performances through natural language instructions. With an emphasis on safety and creativity, Swarm-GPT addresses a critical gap in the field of drone choreography by integrating the creative power of generative models with the effectiveness and safety of model-based planning algorithms. This goal is achieved by prompting the LLM to generate a unique set of waypoints based on extracted audio data. A trajectory planner processes these waypoints to guarantee collision-free and feasible motion. Results can be viewed in simulation prior to execution and modified through dynamic re-prompting. Sim-to-real transfer experiments demonstrate Swarm-GPT's ability to accurately replicate simulated drone trajectories, with a mean sim-to-real root mean square error (RMSE) of 28.7 mm. To date, Swarm-GPT has been successfully showcased at three live events, exemplifying safe real-world deployment of pre-trained models.
Multi-Step Model Predictive Safety Filters: Reducing Chattering by Increasing the Prediction Horizon
Sep 20, 2023Learning-based controllers have demonstrated superior performance compared to classical controllers in various tasks. However, providing safety guarantees is not trivial. Safety, the satisfaction of state and input constraints, can be guaranteed by augmenting the learned control policy with a safety filter. Model predictive safety filters (MPSFs) are a common safety filtering approach based on model predictive control (MPC). MPSFs seek to guarantee safety while minimizing the difference between the proposed and applied inputs in the immediate next time step. This limited foresight can lead to jerky motions and undesired oscillations close to constraint boundaries, known as chattering. In this paper, we reduce chattering by considering input corrections over a longer horizon. Under the assumption of bounded model uncertainties, we prove recursive feasibility using techniques from robust MPC. We verified the proposed approach in both extensive simulation and quadrotor experiments. In experiments with a Crazyflie 2.0 drone, we show that, in addition to preserving the desired safety guarantees, the proposed MPSF reduces chattering by more than a factor of 4 compared to previous MPSF formulations.
A Remote Sim2real Aerial Competition: Fostering Reproducibility and Solutions' Diversity in Robotics Challenges
Aug 31, 2023
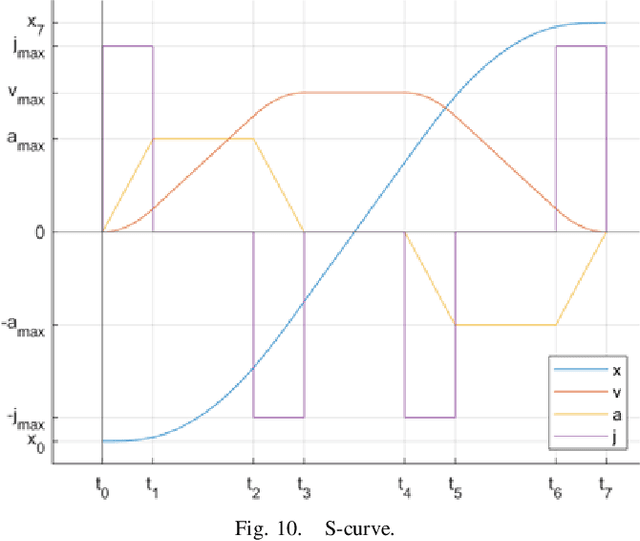
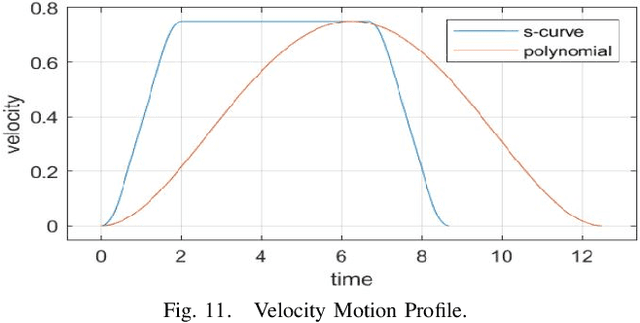

Shared benchmark problems have historically been a fundamental driver of progress for scientific communities. In the context of academic conferences, competitions offer the opportunity to researchers with different origins, backgrounds, and levels of seniority to quantitatively compare their ideas. In robotics, a hot and challenging topic is sim2real-porting approaches that work well in simulation to real robot hardware. In our case, creating a hybrid competition with both simulation and real robot components was also dictated by the uncertainties around travel and logistics in the post-COVID-19 world. Hence, this article motivates and describes an aerial sim2real robot competition that ran during the 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems, from the specification of the competition task, to the details of the software infrastructure supporting simulation and real-life experiments, to the approaches of the top-placed teams and the lessons learned by participants and organizers.
What is the Impact of Releasing Code with Publications? Statistics from the Machine Learning, Robotics, and Control Communities
Aug 19, 2023Open-sourcing research publications is a key enabler for the reproducibility of studies and the collective scientific progress of a research community. As all fields of science develop more advanced algorithms, we become more dependent on complex computational toolboxes -- sharing research ideas solely through equations and proofs is no longer sufficient to communicate scientific developments. Over the past years, several efforts have highlighted the importance and challenges of transparent and reproducible research; code sharing is one of the key necessities in such efforts. In this article, we study the impact of code release on scientific research and present statistics from three research communities: machine learning, robotics, and control. We found that, over a six-year period (2016-2021), the percentages of papers with code at major machine learning, robotics, and control conferences have at least doubled. Moreover, high-impact papers were generally supported by open-source codes. As an example, the top 1% of most cited papers at the Conference on Neural Information Processing Systems (NeurIPS) consistently included open-source codes. In addition, our analysis shows that popular code repositories generally come with high paper citations, which further highlights the coupling between code sharing and the impact of scientific research. While the trends are encouraging, we would like to continue to promote and increase our efforts toward transparent, reproducible research that accelerates innovation -- releasing code with our papers is a clear first step.