 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafety Filtering While Training: Improving the Performance and Sample Efficiency of Reinforcement Learning Agents
Oct 15, 2024Reinforcement learning (RL) controllers are flexible and performant but rarely guarantee safety. Safety filters impart hard safety guarantees to RL controllers while maintaining flexibility. However, safety filters can cause undesired behaviours due to the separation between the controller and the safety filter, often degrading performance and robustness. In this paper, we propose several modifications to incorporating the safety filter in training RL controllers rather than solely applying it during evaluation. The modifications allow the RL controller to learn to account for the safety filter, improving performance. Additionally, our modifications significantly improve sample efficiency and eliminate training-time constraint violations. We verified the proposed modifications in simulated and real experiments with a Crazyflie 2.0 drone. In experiments, we show that the proposed training approaches require significantly fewer environment interactions and improve performance by up to 20% compared to standard RL training.
Multi-Step Model Predictive Safety Filters: Reducing Chattering by Increasing the Prediction Horizon
Sep 20, 2023Learning-based controllers have demonstrated superior performance compared to classical controllers in various tasks. However, providing safety guarantees is not trivial. Safety, the satisfaction of state and input constraints, can be guaranteed by augmenting the learned control policy with a safety filter. Model predictive safety filters (MPSFs) are a common safety filtering approach based on model predictive control (MPC). MPSFs seek to guarantee safety while minimizing the difference between the proposed and applied inputs in the immediate next time step. This limited foresight can lead to jerky motions and undesired oscillations close to constraint boundaries, known as chattering. In this paper, we reduce chattering by considering input corrections over a longer horizon. Under the assumption of bounded model uncertainties, we prove recursive feasibility using techniques from robust MPC. We verified the proposed approach in both extensive simulation and quadrotor experiments. In experiments with a Crazyflie 2.0 drone, we show that, in addition to preserving the desired safety guarantees, the proposed MPSF reduces chattering by more than a factor of 4 compared to previous MPSF formulations.
What is the Impact of Releasing Code with Publications? Statistics from the Machine Learning, Robotics, and Control Communities
Aug 19, 2023Open-sourcing research publications is a key enabler for the reproducibility of studies and the collective scientific progress of a research community. As all fields of science develop more advanced algorithms, we become more dependent on complex computational toolboxes -- sharing research ideas solely through equations and proofs is no longer sufficient to communicate scientific developments. Over the past years, several efforts have highlighted the importance and challenges of transparent and reproducible research; code sharing is one of the key necessities in such efforts. In this article, we study the impact of code release on scientific research and present statistics from three research communities: machine learning, robotics, and control. We found that, over a six-year period (2016-2021), the percentages of papers with code at major machine learning, robotics, and control conferences have at least doubled. Moreover, high-impact papers were generally supported by open-source codes. As an example, the top 1% of most cited papers at the Conference on Neural Information Processing Systems (NeurIPS) consistently included open-source codes. In addition, our analysis shows that popular code repositories generally come with high paper citations, which further highlights the coupling between code sharing and the impact of scientific research. While the trends are encouraging, we would like to continue to promote and increase our efforts toward transparent, reproducible research that accelerates innovation -- releasing code with our papers is a clear first step.
Deep Reinforcement Learning for Decentralized Multi-Robot Exploration with Macro Actions
Oct 05, 2021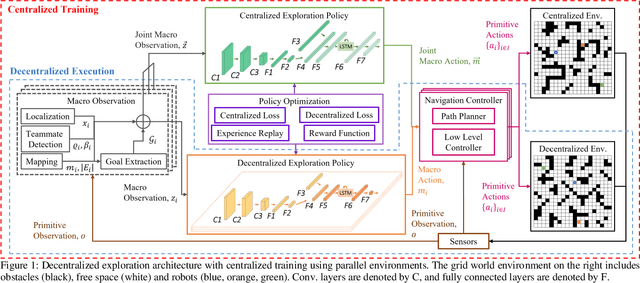
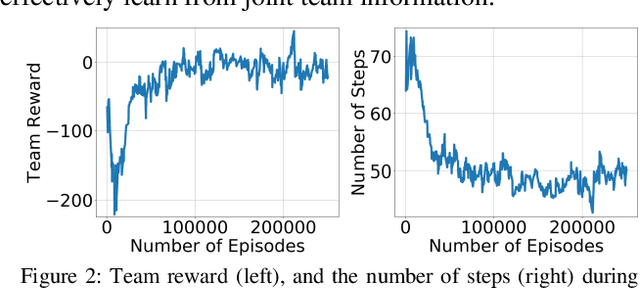
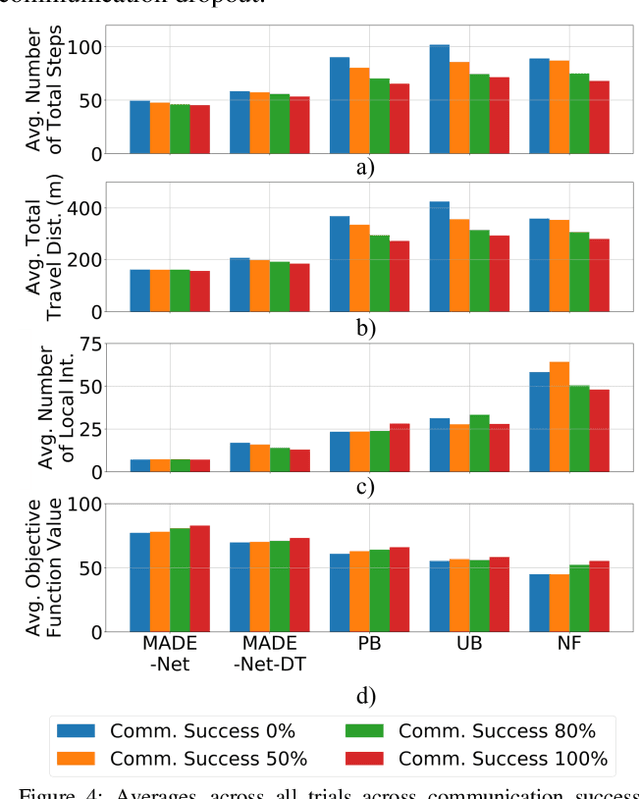
Cooperative multi-robot teams need to be able to explore cluttered and unstructured environments together while dealing with communication challenges. Specifically, during communication dropout, local information about robots can no longer be exchanged to maintain robot team coordination. Therefore, robots need to consider high-level teammate intentions during action selection. In this paper, we present the first Macro Action Decentralized Exploration Network (MADE-Net) using multi-agent deep reinforcement learning to address the challenges of communication dropouts during multi-robot exploration in unseen, unstructured, and cluttered environments. Simulated robot team exploration experiments were conducted and compared to classical and deep reinforcement learning methods. The results showed that our MADE-Net method was able to outperform all benchmark methods in terms of computation time, total travel distance, number of local interactions between robots, and exploration rate across various degrees of communication dropouts; highlighting the effectiveness and robustness of our method.