 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpressMM: Expressive Mobile Manipulation Behaviors in Human-Robot Interactions
Apr 07, 2026Mobile manipulators are increasingly deployed in human-centered environments to perform tasks. While completing such tasks, they should also be able to communicate their intent to the people around them using expressive robot behaviors. Prior work on expressive robot behaviors has used preprogrammed or learning-from-demonstration- based expressive motions and large language model generated high-level interactions. The majority of these existing approaches have not considered human-robot interactions (HRI) where users may interrupt, modify, or redirect a robot's actions during task execution. In this paper, we develop the novel ExpressMM framework that integrates a high-level language-guided planner based on a vision-language model for perception and conversational reasoning with a low-level vision-language-action policy to generate expressive robot behaviors during collaborative HRI tasks. Furthermore, ExpressMM supports interruptible interactions to accommodate updated or redirecting instructions by users. We demonstrate ExpressMM on a mobile manipulator assisting a human in a collaborative assembly scenario and conduct audience-based evaluation of live HRI demonstrations. Questionnaire results show that the ExpressMM-enabled expressive behaviors helped observers clearly interpret the robot's actions and intentions while supporting socially appropriate and understandable interactions. Participants also reported that the robot was useful for collaborative tasks and behaved in a predictable and safe manner during the demonstrations, fostering positive perceptions of the robot's usefulness, safety, and predictability during the collaborative tasks.
PovNet+: A Deep Learning Architecture for Socially Assistive Robots to Learn and Assist with Multiple Activities of Daily Living
Jan 28, 2026A significant barrier to the long-term deployment of autonomous socially assistive robots is their inability to both perceive and assist with multiple activities of daily living (ADLs). In this paper, we present the first multimodal deep learning architecture, POVNet+, for multi-activity recognition for socially assistive robots to proactively initiate assistive behaviors. Our novel architecture introduces the use of both ADL and motion embedding spaces to uniquely distinguish between a known ADL being performed, a new unseen ADL, or a known ADL being performed atypically in order to assist people in real scenarios. Furthermore, we apply a novel user state estimation method to the motion embedding space to recognize new ADLs while monitoring user performance. This ADL perception information is used to proactively initiate robot assistive interactions. Comparison experiments with state-of-the-art human activity recognition methods show our POVNet+ method has higher ADL classification accuracy. Human-robot interaction experiments in a cluttered living environment with multiple users and the socially assistive robot Leia using POVNet+ demonstrate the ability of our multi-modal ADL architecture in successfully identifying different seen and unseen ADLs, and ADLs being performed atypically, while initiating appropriate assistive human-robot interactions.
SplatSearch: Instance Image Goal Navigation for Mobile Robots using 3D Gaussian Splatting and Diffusion Models
Nov 17, 2025The Instance Image Goal Navigation (IIN) problem requires mobile robots deployed in unknown environments to search for specific objects or people of interest using only a single reference goal image of the target. This problem can be especially challenging when: 1) the reference image is captured from an arbitrary viewpoint, and 2) the robot must operate with sparse-view scene reconstructions. In this paper, we address the IIN problem, by introducing SplatSearch, a novel architecture that leverages sparse-view 3D Gaussian Splatting (3DGS) reconstructions. SplatSearch renders multiple viewpoints around candidate objects using a sparse online 3DGS map, and uses a multi-view diffusion model to complete missing regions of the rendered images, enabling robust feature matching against the goal image. A novel frontier exploration policy is introduced which uses visual context from the synthesized viewpoints with semantic context from the goal image to evaluate frontier locations, allowing the robot to prioritize frontiers that are semantically and visually relevant to the goal image. Extensive experiments in photorealistic home and real-world environments validate the higher performance of SplatSearch against current state-of-the-art methods in terms of Success Rate and Success Path Length. An ablation study confirms the design choices of SplatSearch.
Embodied AI with Foundation Models for Mobile Service Robots: A Systematic Review
May 26, 2025Rapid advancements in foundation models, including Large Language Models, Vision-Language Models, Multimodal Large Language Models, and Vision-Language-Action Models have opened new avenues for embodied AI in mobile service robotics. By combining foundation models with the principles of embodied AI, where intelligent systems perceive, reason, and act through physical interactions, robots can improve understanding, adapt to, and execute complex tasks in dynamic real-world environments. However, embodied AI in mobile service robots continues to face key challenges, including multimodal sensor fusion, real-time decision-making under uncertainty, task generalization, and effective human-robot interactions (HRI). In this paper, we present the first systematic review of the integration of foundation models in mobile service robotics, identifying key open challenges in embodied AI and examining how foundation models can address them. Namely, we explore the role of such models in enabling real-time sensor fusion, language-conditioned control, and adaptive task execution. Furthermore, we discuss real-world applications in the domestic assistance, healthcare, and service automation sectors, demonstrating the transformative impact of foundation models on service robotics. We also include potential future research directions, emphasizing the need for predictive scaling laws, autonomous long-term adaptation, and cross-embodiment generalization to enable scalable, efficient, and robust deployment of foundation models in human-centric robotic systems.
MLLM-Search: A Zero-Shot Approach to Finding People using Multimodal Large Language Models
Nov 27, 2024



Robotic search of people in human-centered environments, including healthcare settings, is challenging as autonomous robots need to locate people without complete or any prior knowledge of their schedules, plans or locations. Furthermore, robots need to be able to adapt to real-time events that can influence a person's plan in an environment. In this paper, we present MLLM-Search, a novel zero-shot person search architecture that leverages multimodal large language models (MLLM) to address the mobile robot problem of searching for a person under event-driven scenarios with varying user schedules. Our approach introduces a novel visual prompting method to provide robots with spatial understanding of the environment by generating a spatially grounded waypoint map, representing navigable waypoints by a topological graph and regions by semantic labels. This is incorporated into a MLLM with a region planner that selects the next search region based on the semantic relevance to the search scenario, and a waypoint planner which generates a search path by considering the semantically relevant objects and the local spatial context through our unique spatial chain-of-thought prompting approach. Extensive 3D photorealistic experiments were conducted to validate the performance of MLLM-Search in searching for a person with a changing schedule in different environments. An ablation study was also conducted to validate the main design choices of MLLM-Search. Furthermore, a comparison study with state-of-the art search methods demonstrated that MLLM-Search outperforms existing methods with respect to search efficiency. Real-world experiments with a mobile robot in a multi-room floor of a building showed that MLLM-Search was able to generalize to finding a person in a new unseen environment.
The Future of Intelligent Healthcare: A Systematic Analysis and Discussion on the Integration and Impact of Robots Using Large Language Models for Healthcare
Nov 05, 2024The potential use of large language models (LLMs) in healthcare robotics can help address the significant demand put on healthcare systems around the world with respect to an aging demographic and a shortage of healthcare professionals. Even though LLMs have already been integrated into medicine to assist both clinicians and patients, the integration of LLMs within healthcare robots has not yet been explored for clinical settings. In this perspective paper, we investigate the groundbreaking developments in robotics and LLMs to uniquely identify the needed system requirements for designing health specific LLM based robots in terms of multi modal communication through human robot interactions (HRIs), semantic reasoning, and task planning. Furthermore, we discuss the ethical issues, open challenges, and potential future research directions for this emerging innovative field.
4CNet: A Confidence-Aware, Contrastive, Conditional, Consistency Model for Robot Map Prediction in Multi-Robot Environments
Feb 27, 2024



Mobile robots in unknown cluttered environments with irregularly shaped obstacles often face sensing, energy, and communication challenges which directly affect their ability to explore these environments. In this paper, we introduce a novel deep learning method, Confidence-Aware Contrastive Conditional Consistency Model (4CNet), for mobile robot map prediction during resource-limited exploration in multi-robot environments. 4CNet uniquely incorporates: 1) a conditional consistency model for map prediction in irregularly shaped unknown regions, 2) a contrastive map-trajectory pretraining framework for a trajectory encoder that extracts spatial information from the trajectories of nearby robots during map prediction, and 3) a confidence network to measure the uncertainty of map prediction for effective exploration under resource constraints. We incorporate 4CNet within our proposed robot exploration with map prediction architecture, 4CNet-E. We then conduct extensive comparison studies with 4CNet-E and state-of-the-art heuristic and learning methods to investigate both map prediction and exploration performance in environments consisting of uneven terrain and irregularly shaped obstacles. Results showed that 4CNet-E obtained statistically significant higher prediction accuracy and area coverage with varying environment sizes, number of robots, energy budgets, and communication limitations. Real-world mobile robot experiments were performed and validated the feasibility and generalizability of 4CNet-E for mobile robot map prediction and exploration.
LDTrack: Dynamic People Tracking by Service Robots using Diffusion Models
Feb 26, 2024Tracking of dynamic people in cluttered and crowded human-centered environments is a challenging robotics problem due to the presence of intraclass variations including occlusions, pose deformations, and lighting variations. This paper introduces a novel deep learning architecture, using conditional latent diffusion models, the Latent Diffusion Track (LDTrack), for tracking multiple dynamic people under intraclass variations. By uniquely utilizing conditional latent diffusion models to capture temporal person embeddings, our architecture can adapt to appearance changes of people over time. We incorporated a latent feature encoder network which enables the diffusion process to operate within a high-dimensional latent space to allow for the extraction and spatial-temporal refinement of such rich features as person appearance, motion, location, identity, and contextual information. Extensive experiments demonstrate the effectiveness of LDTrack over other state-of-the-art tracking methods in cluttered and crowded human-centered environments under intraclass variations. Namely, the results show our method outperforms existing deep learning robotic people tracking methods in both tracking accuracy and tracking precision with statistical significance.
NavFormer: A Transformer Architecture for Robot Target-Driven Navigation in Unknown and Dynamic Environments
Feb 09, 2024



In unknown cluttered and dynamic environments such as disaster scenes, mobile robots need to perform target-driven navigation in order to find people or objects of interest, while being solely guided by images of the targets. In this paper, we introduce NavFormer, a novel end-to-end transformer architecture developed for robot target-driven navigation in unknown and dynamic environments. NavFormer leverages the strengths of both 1) transformers for sequential data processing and 2) self-supervised learning (SSL) for visual representation to reason about spatial layouts and to perform collision-avoidance in dynamic settings. The architecture uniquely combines dual-visual encoders consisting of a static encoder for extracting invariant environment features for spatial reasoning, and a general encoder for dynamic obstacle avoidance. The primary robot navigation task is decomposed into two sub-tasks for training: single robot exploration and multi-robot collision avoidance. We perform cross-task training to enable the transfer of learned skills to the complex primary navigation task without the need for task-specific fine-tuning. Simulated experiments demonstrate that NavFormer can effectively navigate a mobile robot in diverse unknown environments, outperforming existing state-of-the-art methods in terms of success rate and success weighted by (normalized inverse) path length. Furthermore, a comprehensive ablation study is performed to evaluate the impact of the main design choices of the structure and training of NavFormer, further validating their effectiveness in the overall system.
Robots Autonomously Detecting People: A Multimodal Deep Contrastive Learning Method Robust to Intraclass Variations
Mar 01, 2022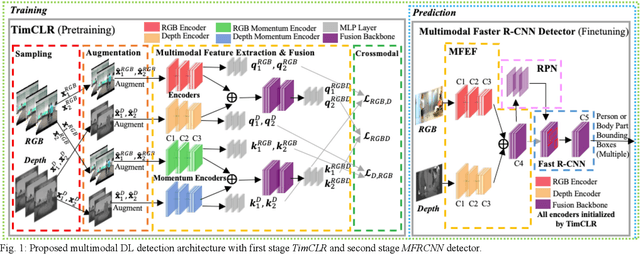

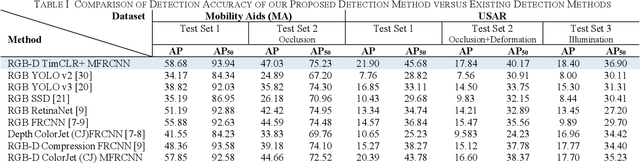
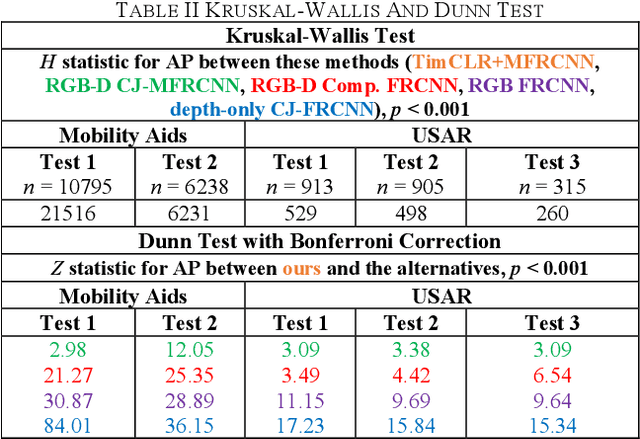
Robotic detection of people in crowded and/or cluttered human-centered environments including hospitals, long-term care, stores and airports is challenging as people can become occluded by other people or objects, and deform due to variations in clothing or pose. There can also be loss of discriminative visual features due to poor lighting. In this paper, we present a novel multimodal person detection architecture to address the mobile robot problem of person detection under intraclass variations. We present a two-stage training approach using 1) a unique pretraining method we define as Temporal Invariant Multimodal Contrastive Learning (TimCLR), and 2) a Multimodal Faster R-CNN (MFRCNN) detector. TimCLR learns person representations that are invariant under intraclass variations through unsupervised learning. Our approach is unique in that it generates image pairs from natural variations within multimodal image sequences, in addition to synthetic data augmentation, and contrasts crossmodal features to transfer invariances between different modalities. These pretrained features are used by the MFRCNN detector for finetuning and person detection from RGB-D images. Extensive experiments validate the performance of our DL architecture in both human-centered crowded and cluttered environments. Results show that our method outperforms existing unimodal and multimodal person detection approaches in terms of detection accuracy in detecting people with body occlusions and pose deformations in different lighting conditions.