 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobots Autonomously Detecting People: A Multimodal Deep Contrastive Learning Method Robust to Intraclass Variations
Paper and Code
Mar 01, 2022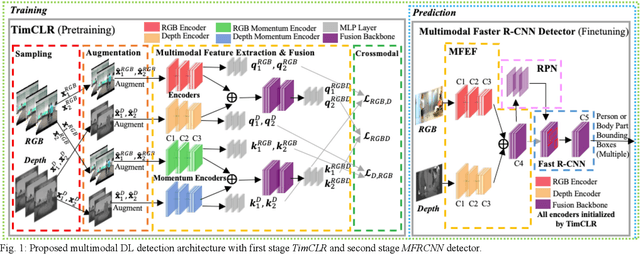

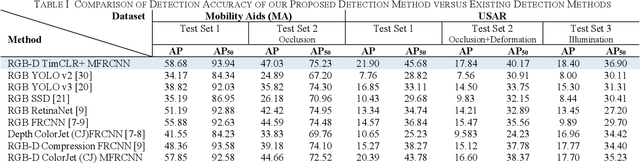
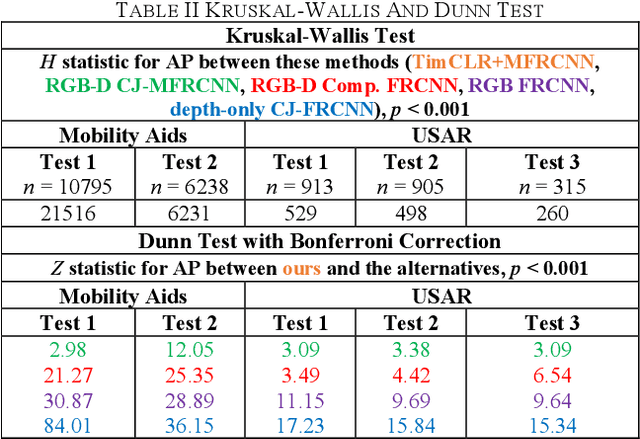
Robotic detection of people in crowded and/or cluttered human-centered environments including hospitals, long-term care, stores and airports is challenging as people can become occluded by other people or objects, and deform due to variations in clothing or pose. There can also be loss of discriminative visual features due to poor lighting. In this paper, we present a novel multimodal person detection architecture to address the mobile robot problem of person detection under intraclass variations. We present a two-stage training approach using 1) a unique pretraining method we define as Temporal Invariant Multimodal Contrastive Learning (TimCLR), and 2) a Multimodal Faster R-CNN (MFRCNN) detector. TimCLR learns person representations that are invariant under intraclass variations through unsupervised learning. Our approach is unique in that it generates image pairs from natural variations within multimodal image sequences, in addition to synthetic data augmentation, and contrasts crossmodal features to transfer invariances between different modalities. These pretrained features are used by the MFRCNN detector for finetuning and person detection from RGB-D images. Extensive experiments validate the performance of our DL architecture in both human-centered crowded and cluttered environments. Results show that our method outperforms existing unimodal and multimodal person detection approaches in terms of detection accuracy in detecting people with body occlusions and pose deformations in different lighting conditions.