 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpressMM: Expressive Mobile Manipulation Behaviors in Human-Robot Interactions
Apr 07, 2026Mobile manipulators are increasingly deployed in human-centered environments to perform tasks. While completing such tasks, they should also be able to communicate their intent to the people around them using expressive robot behaviors. Prior work on expressive robot behaviors has used preprogrammed or learning-from-demonstration- based expressive motions and large language model generated high-level interactions. The majority of these existing approaches have not considered human-robot interactions (HRI) where users may interrupt, modify, or redirect a robot's actions during task execution. In this paper, we develop the novel ExpressMM framework that integrates a high-level language-guided planner based on a vision-language model for perception and conversational reasoning with a low-level vision-language-action policy to generate expressive robot behaviors during collaborative HRI tasks. Furthermore, ExpressMM supports interruptible interactions to accommodate updated or redirecting instructions by users. We demonstrate ExpressMM on a mobile manipulator assisting a human in a collaborative assembly scenario and conduct audience-based evaluation of live HRI demonstrations. Questionnaire results show that the ExpressMM-enabled expressive behaviors helped observers clearly interpret the robot's actions and intentions while supporting socially appropriate and understandable interactions. Participants also reported that the robot was useful for collaborative tasks and behaved in a predictable and safe manner during the demonstrations, fostering positive perceptions of the robot's usefulness, safety, and predictability during the collaborative tasks.
PovNet+: A Deep Learning Architecture for Socially Assistive Robots to Learn and Assist with Multiple Activities of Daily Living
Jan 28, 2026A significant barrier to the long-term deployment of autonomous socially assistive robots is their inability to both perceive and assist with multiple activities of daily living (ADLs). In this paper, we present the first multimodal deep learning architecture, POVNet+, for multi-activity recognition for socially assistive robots to proactively initiate assistive behaviors. Our novel architecture introduces the use of both ADL and motion embedding spaces to uniquely distinguish between a known ADL being performed, a new unseen ADL, or a known ADL being performed atypically in order to assist people in real scenarios. Furthermore, we apply a novel user state estimation method to the motion embedding space to recognize new ADLs while monitoring user performance. This ADL perception information is used to proactively initiate robot assistive interactions. Comparison experiments with state-of-the-art human activity recognition methods show our POVNet+ method has higher ADL classification accuracy. Human-robot interaction experiments in a cluttered living environment with multiple users and the socially assistive robot Leia using POVNet+ demonstrate the ability of our multi-modal ADL architecture in successfully identifying different seen and unseen ADLs, and ADLs being performed atypically, while initiating appropriate assistive human-robot interactions.
SplatSearch: Instance Image Goal Navigation for Mobile Robots using 3D Gaussian Splatting and Diffusion Models
Nov 17, 2025The Instance Image Goal Navigation (IIN) problem requires mobile robots deployed in unknown environments to search for specific objects or people of interest using only a single reference goal image of the target. This problem can be especially challenging when: 1) the reference image is captured from an arbitrary viewpoint, and 2) the robot must operate with sparse-view scene reconstructions. In this paper, we address the IIN problem, by introducing SplatSearch, a novel architecture that leverages sparse-view 3D Gaussian Splatting (3DGS) reconstructions. SplatSearch renders multiple viewpoints around candidate objects using a sparse online 3DGS map, and uses a multi-view diffusion model to complete missing regions of the rendered images, enabling robust feature matching against the goal image. A novel frontier exploration policy is introduced which uses visual context from the synthesized viewpoints with semantic context from the goal image to evaluate frontier locations, allowing the robot to prioritize frontiers that are semantically and visually relevant to the goal image. Extensive experiments in photorealistic home and real-world environments validate the higher performance of SplatSearch against current state-of-the-art methods in terms of Success Rate and Success Path Length. An ablation study confirms the design choices of SplatSearch.
Embodied AI with Foundation Models for Mobile Service Robots: A Systematic Review
May 26, 2025Rapid advancements in foundation models, including Large Language Models, Vision-Language Models, Multimodal Large Language Models, and Vision-Language-Action Models have opened new avenues for embodied AI in mobile service robotics. By combining foundation models with the principles of embodied AI, where intelligent systems perceive, reason, and act through physical interactions, robots can improve understanding, adapt to, and execute complex tasks in dynamic real-world environments. However, embodied AI in mobile service robots continues to face key challenges, including multimodal sensor fusion, real-time decision-making under uncertainty, task generalization, and effective human-robot interactions (HRI). In this paper, we present the first systematic review of the integration of foundation models in mobile service robotics, identifying key open challenges in embodied AI and examining how foundation models can address them. Namely, we explore the role of such models in enabling real-time sensor fusion, language-conditioned control, and adaptive task execution. Furthermore, we discuss real-world applications in the domestic assistance, healthcare, and service automation sectors, demonstrating the transformative impact of foundation models on service robotics. We also include potential future research directions, emphasizing the need for predictive scaling laws, autonomous long-term adaptation, and cross-embodiment generalization to enable scalable, efficient, and robust deployment of foundation models in human-centric robotic systems.
Inverse k-visibility for RSSI-based Indoor Geometric Mapping
Aug 14, 2024In recent years, the increased availability of WiFi in indoor environments has gained an interest in the robotics community to leverage WiFi signals for enhancing indoor SLAM (Simultaneous Localization and Mapping) systems. SLAM technology is widely used, especially for the navigation and control of autonomous robots. This paper discusses various works in developing WiFi-based localization and challenges in achieving high-accuracy geometric maps. This paper introduces the concept of inverse k-visibility developed from the k-visibility algorithm to identify the free space in an unknown environment for planning, navigation, and obstacle avoidance. Comprehensive experiments, including those utilizing single and multiple RSSI signals, were conducted in both simulated and real-world environments to demonstrate the robustness of the proposed algorithm. Additionally, a detailed analysis comparing the resulting maps with ground-truth Lidar-based maps is provided to highlight the algorithm's accuracy and reliability.
Visual Inertial Odometry using Focal Plane Binary Features (BIT-VIO)
Mar 14, 2024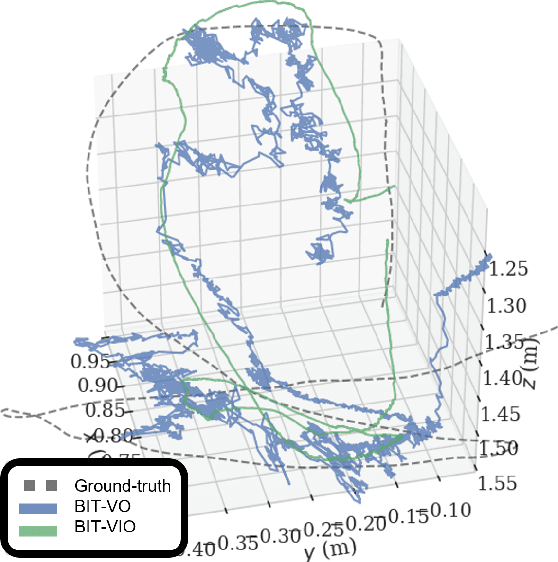
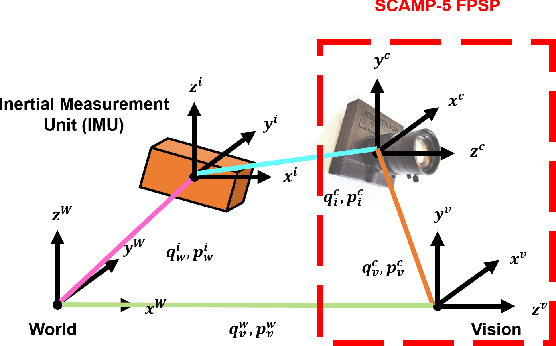
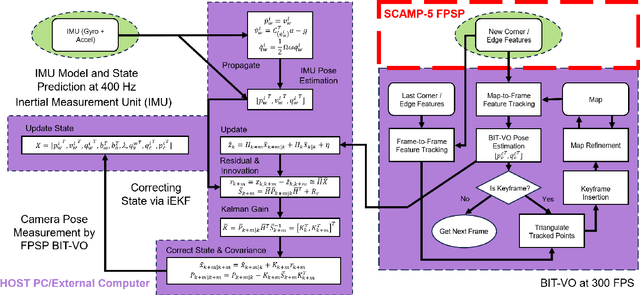
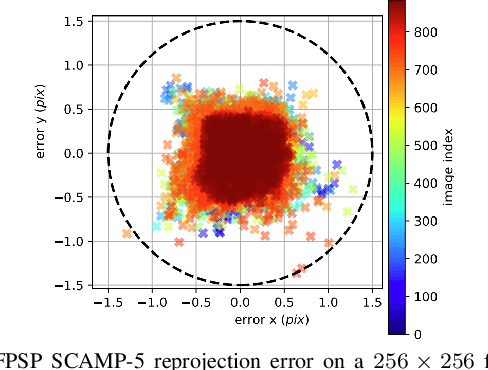
Focal-Plane Sensor-Processor Arrays (FPSP)s are an emerging technology that can execute vision algorithms directly on the image sensor. Unlike conventional cameras, FPSPs perform computation on the image plane -- at individual pixels -- enabling high frame rate image processing while consuming low power, making them ideal for mobile robotics. FPSPs, such as the SCAMP-5, use parallel processing and are based on the Single Instruction Multiple Data (SIMD) paradigm. In this paper, we present BIT-VIO, the first Visual Inertial Odometry (VIO) which utilises SCAMP-5.BIT-VIO is a loosely-coupled iterated Extended Kalman Filter (iEKF) which fuses together the visual odometry running fast at 300 FPS with predictions from 400 Hz IMU measurements to provide accurate and smooth trajectories.