 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRaspberry PhenoSet: A Phenology-based Dataset for Automated Growth Detection and Yield Estimation
Nov 01, 2024

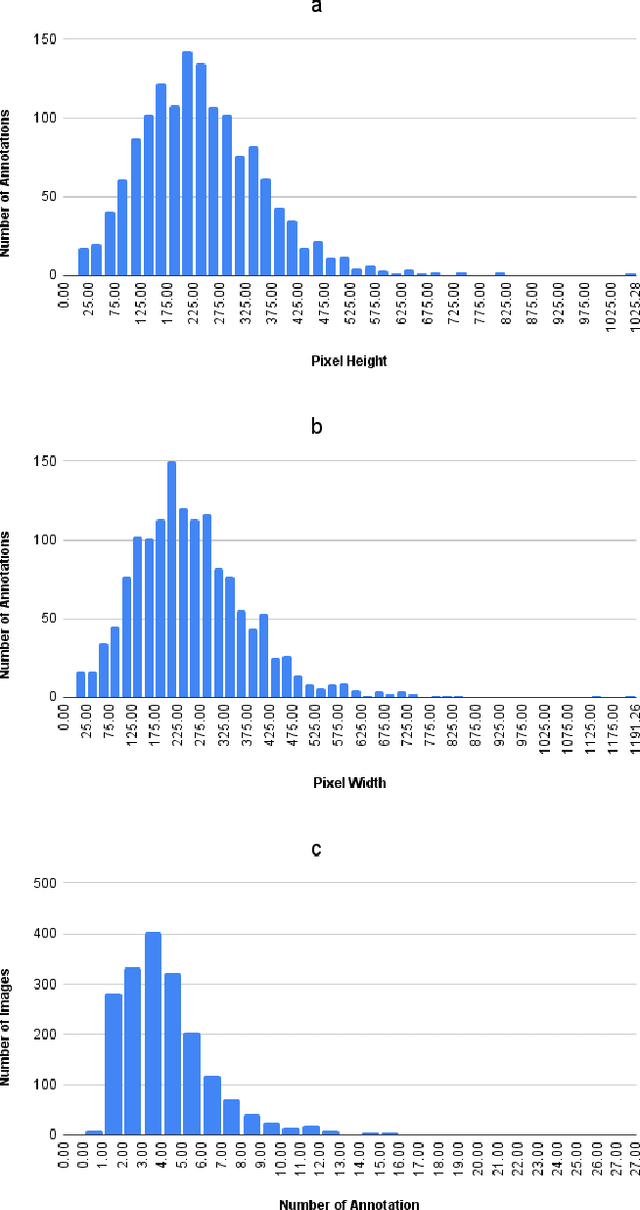
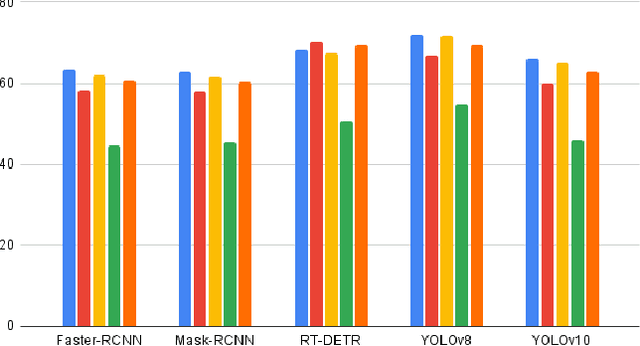
The future of the agriculture industry is intertwined with automation. Accurate fruit detection, yield estimation, and harvest time estimation are crucial for optimizing agricultural practices. These tasks can be carried out by robots to reduce labour costs and improve the efficiency of the process. To do so, deep learning models should be trained to perform knowledge-based tasks, which outlines the importance of contributing valuable data to the literature. In this paper, we introduce Raspberry PhenoSet, a phenology-based dataset designed for detecting and segmenting raspberry fruit across seven developmental stages. To the best of our knowledge, Raspberry PhenoSet is the first fruit dataset to integrate biology-based classification with fruit detection tasks, offering valuable insights for yield estimation and precise harvest timing. This dataset contains 1,853 high-resolution images, the highest quality in the literature, captured under controlled artificial lighting in a vertical farm. The dataset has a total of 6,907 instances of mask annotations, manually labelled to reflect the seven phenology stages. We have also benchmarked Raspberry PhenoSet using several state-of-the-art deep learning models, including YOLOv8, YOLOv10, RT-DETR, and Mask R-CNN, to provide a comprehensive evaluation of their performance on the dataset. Our results highlight the challenges of distinguishing subtle phenology stages and underscore the potential of Raspberry PhenoSet for both deep learning model development and practical robotic applications in agriculture, particularly in yield prediction and supply chain management. The dataset and the trained models are publicly available for future studies.
A Master-Follower Teleoperation System for Robotic Catheterization: Design, Characterization, and Tracking Control
Jul 18, 2024Minimally invasive robotic surgery has gained significant attention over the past two decades. Telerobotic systems, combined with robot-mediated minimally invasive techniques, have enabled surgeons and clinicians to mitigate radiation exposure for medical staff and extend medical services to remote and hard-to-reach areas. To enhance these services, teleoperated robotic surgery systems incorporating master and follower devices should offer transparency, enabling surgeons and clinicians to remotely experience a force interaction similar to the one the follower device experiences with patients' bodies. This paper presents the design and development of a three-degree-of-freedom master-follower teleoperated system for robotic catheterization. To resemble manual intervention by clinicians, the follower device features a grip-insert-release mechanism to eliminate catheter buckling and torsion during operation. The bidirectionally navigable ablation catheter is statically characterized for force-interactive medical interventions. The system's performance is evaluated through approaching and open-loop path tracking over typical circular, infinity-like, and spiral paths. Path tracking errors are presented as mean Euclidean error (MEE) and mean absolute error (MAE). The MEE ranges from 0.64 cm (infinity-like path) to 1.53 cm (spiral path). The MAE also ranges from 0.81 cm (infinity-like path) to 1.92 cm (spiral path). The results indicate that while the system's precision and accuracy with an open-loop controller meet the design targets, closed-loop controllers are necessary to address the catheter's hysteresis and dead zone, and system nonlinearities.
Visual Inertial Odometry using Focal Plane Binary Features (BIT-VIO)
Mar 14, 2024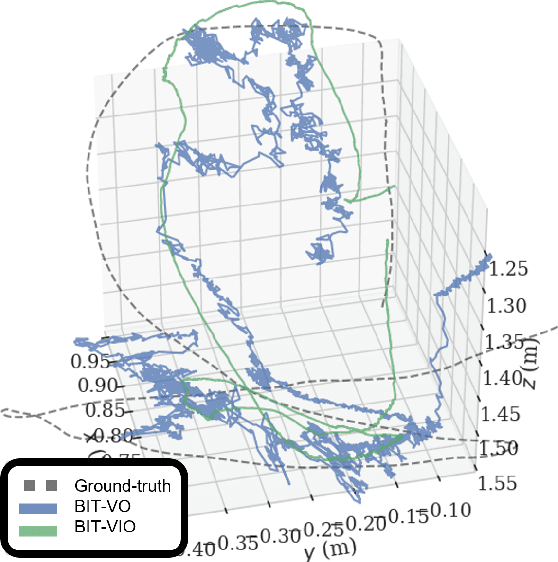
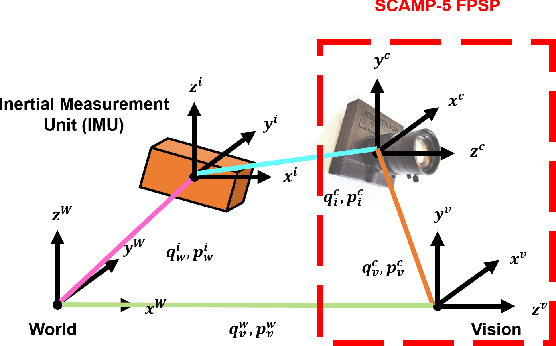
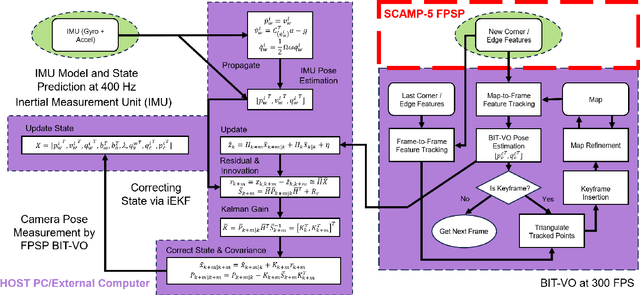
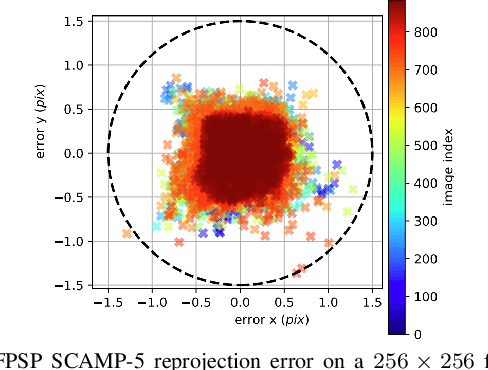
Focal-Plane Sensor-Processor Arrays (FPSP)s are an emerging technology that can execute vision algorithms directly on the image sensor. Unlike conventional cameras, FPSPs perform computation on the image plane -- at individual pixels -- enabling high frame rate image processing while consuming low power, making them ideal for mobile robotics. FPSPs, such as the SCAMP-5, use parallel processing and are based on the Single Instruction Multiple Data (SIMD) paradigm. In this paper, we present BIT-VIO, the first Visual Inertial Odometry (VIO) which utilises SCAMP-5.BIT-VIO is a loosely-coupled iterated Extended Kalman Filter (iEKF) which fuses together the visual odometry running fast at 300 FPS with predictions from 400 Hz IMU measurements to provide accurate and smooth trajectories.
Di-NeRF: Distributed NeRF for Collaborative Learning with Unknown Relative Poses
Feb 02, 2024



Collaborative mapping of unknown environments can be done faster and more robustly than a single robot. However, a collaborative approach requires a distributed paradigm to be scalable and deal with communication issues. This work presents a fully distributed algorithm enabling a group of robots to collectively optimize the parameters of a Neural Radiance Field (NeRF). The algorithm involves the communication of each robot's trained NeRF parameters over a mesh network, where each robot trains its NeRF and has access to its own visual data only. Additionally, the relative poses of all robots are jointly optimized alongside the model parameters, enabling mapping with unknown relative camera poses. We show that multi-robot systems can benefit from differentiable and robust 3D reconstruction optimized from multiple NeRFs. Experiments on real-world and synthetic data demonstrate the efficiency of the proposed algorithm. See the website of the project for videos of the experiments and supplementary material(https://sites.google.com/view/di-nerf/home).
Deep Direct Visual Servoing of Tendon-Driven Continuum Robots
Nov 04, 2021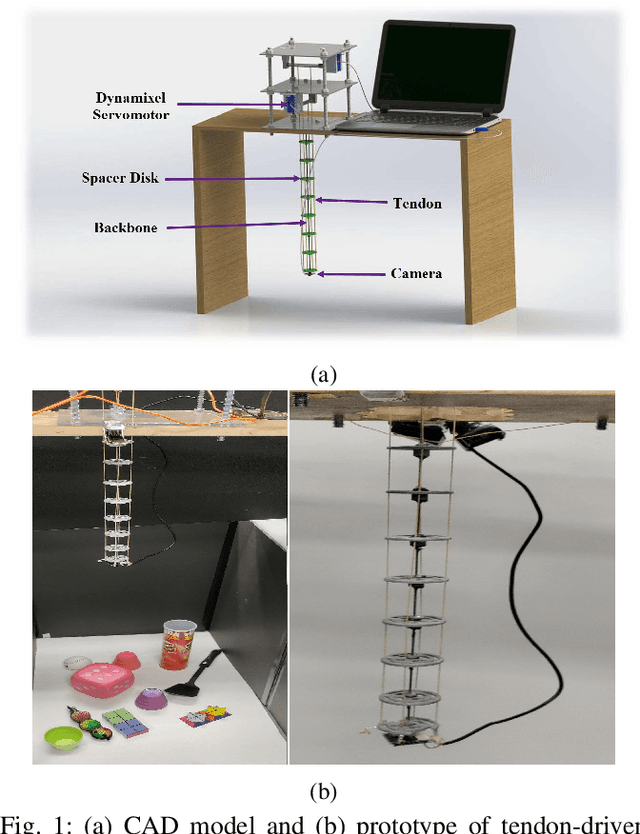

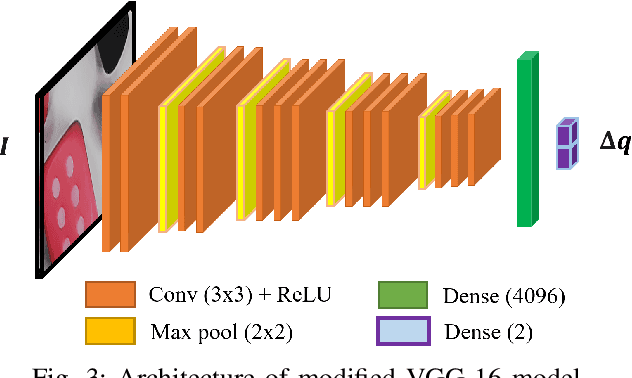

Vision-based control has found a key place in the research to tackle the requirement of the state feedback when controlling a continuum robot under physical sensing limitations. Traditional visual servoing requires feature extraction and tracking while the imaging device captures the images, which limits the controller's efficiency. We hypothesize that employing deep learning models and implementing direct visual servoing can effectively resolve the issue by eliminating the tracking requirement and controlling the continuum robot without requiring an exact system model. In this paper, we control a single-section tendon-driven continuum robot utilizing a modified VGG-16 deep learning network and an eye-in-hand direct visual servoing approach. The proposed algorithm is first developed in Blender using only one input image of the target and then implemented on a real robot. The convergence and accuracy of the results in normal, shadowed, and occluded scenes reflected by the sum of absolute difference between the normalized target and captured images prove the effectiveness and robustness of the proposed controller.