 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePLT-D3: A High-fidelity Dynamic Driving Simulation Dataset for Stereo Depth and Scene Flow
Jun 11, 2024

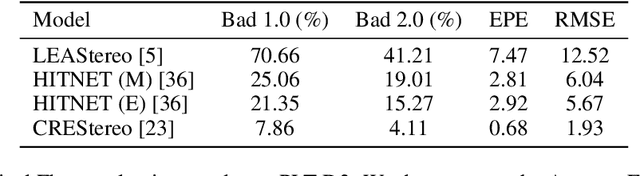
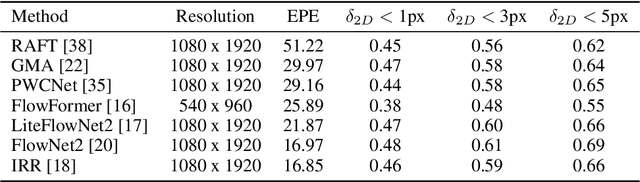
Autonomous driving has experienced remarkable progress, bolstered by innovations in computational hardware and sophisticated deep learning methodologies. The foundation of these advancements rests on the availability and quality of datasets, which are crucial for the development and refinement of dependable and versatile autonomous driving algorithms. While numerous datasets have been developed to support the evolution of autonomous driving perception technologies, few offer the diversity required to thoroughly test and enhance system robustness under varied weather conditions. Many public datasets lack the comprehensive coverage of challenging weather scenarios and detailed, high-resolution data, which are critical for training and validating advanced autonomous-driving perception models. In this paper, we introduce PLT-D3; a Dynamic-weather Driving Dataset, designed specifically to enhance autonomous driving systems' adaptability to diverse weather conditions. PLT-D3 provides high-fidelity stereo depth and scene flow ground truth data generated using Unreal Engine 5. In particular, this dataset includes synchronized high-resolution stereo image sequences that replicate a wide array of dynamic weather scenarios including rain, snow, fog, and diverse lighting conditions, offering an unprecedented level of realism in simulation-based testing. The primary aim of PLT-D3 is to address the scarcity of comprehensive training and testing resources that can simulate real-world weather variations. Benchmarks have been established for several critical autonomous driving tasks using PLT-D3, such as depth estimation, optical flow and scene-flow to measure and enhance the performance of state-of-the-art models.
Deep Direct Visual Servoing of Tendon-Driven Continuum Robots
Nov 04, 2021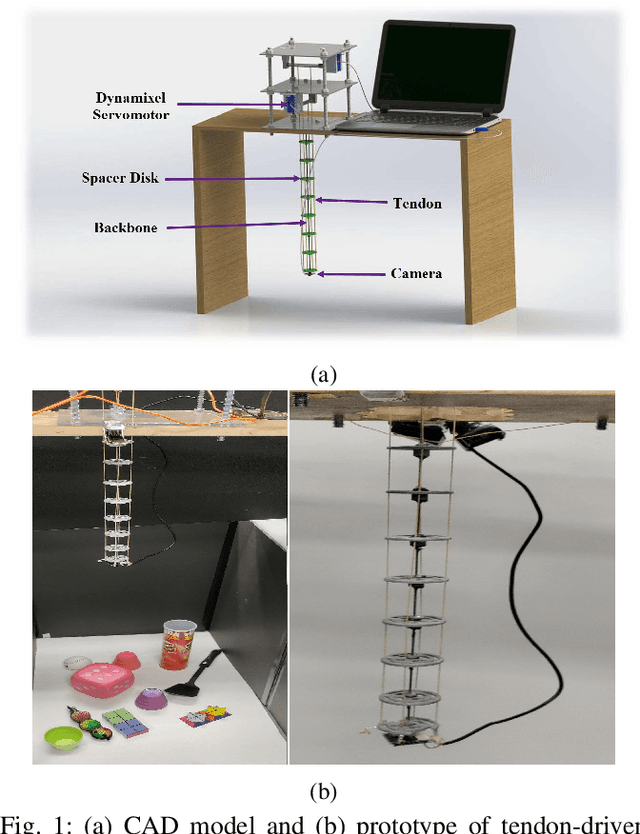

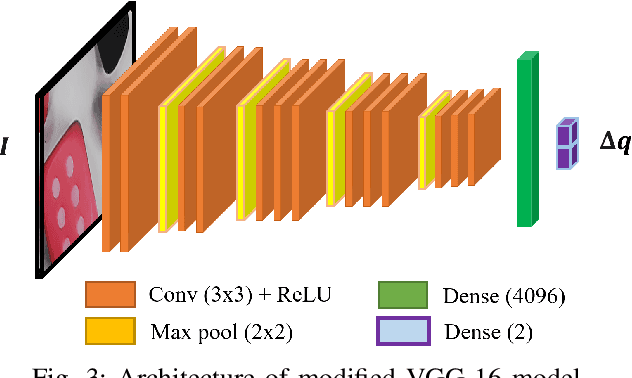

Vision-based control has found a key place in the research to tackle the requirement of the state feedback when controlling a continuum robot under physical sensing limitations. Traditional visual servoing requires feature extraction and tracking while the imaging device captures the images, which limits the controller's efficiency. We hypothesize that employing deep learning models and implementing direct visual servoing can effectively resolve the issue by eliminating the tracking requirement and controlling the continuum robot without requiring an exact system model. In this paper, we control a single-section tendon-driven continuum robot utilizing a modified VGG-16 deep learning network and an eye-in-hand direct visual servoing approach. The proposed algorithm is first developed in Blender using only one input image of the target and then implemented on a real robot. The convergence and accuracy of the results in normal, shadowed, and occluded scenes reflected by the sum of absolute difference between the normalized target and captured images prove the effectiveness and robustness of the proposed controller.