 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSplatSearch: Instance Image Goal Navigation for Mobile Robots using 3D Gaussian Splatting and Diffusion Models
Nov 17, 2025The Instance Image Goal Navigation (IIN) problem requires mobile robots deployed in unknown environments to search for specific objects or people of interest using only a single reference goal image of the target. This problem can be especially challenging when: 1) the reference image is captured from an arbitrary viewpoint, and 2) the robot must operate with sparse-view scene reconstructions. In this paper, we address the IIN problem, by introducing SplatSearch, a novel architecture that leverages sparse-view 3D Gaussian Splatting (3DGS) reconstructions. SplatSearch renders multiple viewpoints around candidate objects using a sparse online 3DGS map, and uses a multi-view diffusion model to complete missing regions of the rendered images, enabling robust feature matching against the goal image. A novel frontier exploration policy is introduced which uses visual context from the synthesized viewpoints with semantic context from the goal image to evaluate frontier locations, allowing the robot to prioritize frontiers that are semantically and visually relevant to the goal image. Extensive experiments in photorealistic home and real-world environments validate the higher performance of SplatSearch against current state-of-the-art methods in terms of Success Rate and Success Path Length. An ablation study confirms the design choices of SplatSearch.
MLLM-Search: A Zero-Shot Approach to Finding People using Multimodal Large Language Models
Nov 27, 2024



Robotic search of people in human-centered environments, including healthcare settings, is challenging as autonomous robots need to locate people without complete or any prior knowledge of their schedules, plans or locations. Furthermore, robots need to be able to adapt to real-time events that can influence a person's plan in an environment. In this paper, we present MLLM-Search, a novel zero-shot person search architecture that leverages multimodal large language models (MLLM) to address the mobile robot problem of searching for a person under event-driven scenarios with varying user schedules. Our approach introduces a novel visual prompting method to provide robots with spatial understanding of the environment by generating a spatially grounded waypoint map, representing navigable waypoints by a topological graph and regions by semantic labels. This is incorporated into a MLLM with a region planner that selects the next search region based on the semantic relevance to the search scenario, and a waypoint planner which generates a search path by considering the semantically relevant objects and the local spatial context through our unique spatial chain-of-thought prompting approach. Extensive 3D photorealistic experiments were conducted to validate the performance of MLLM-Search in searching for a person with a changing schedule in different environments. An ablation study was also conducted to validate the main design choices of MLLM-Search. Furthermore, a comparison study with state-of-the art search methods demonstrated that MLLM-Search outperforms existing methods with respect to search efficiency. Real-world experiments with a mobile robot in a multi-room floor of a building showed that MLLM-Search was able to generalize to finding a person in a new unseen environment.
Find Everything: A General Vision Language Model Approach to Multi-Object Search
Oct 01, 2024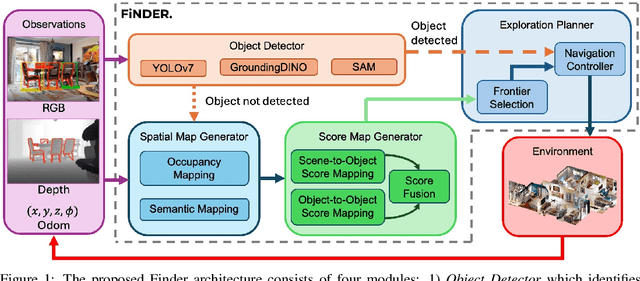
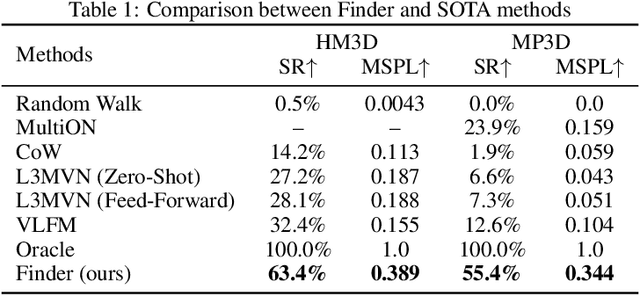
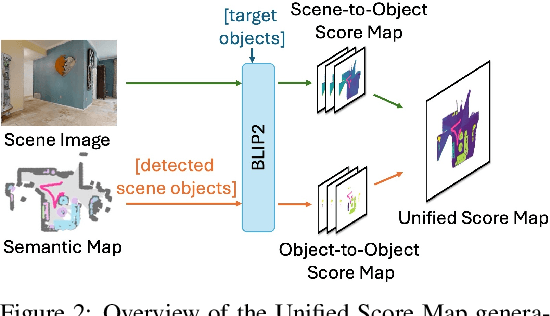
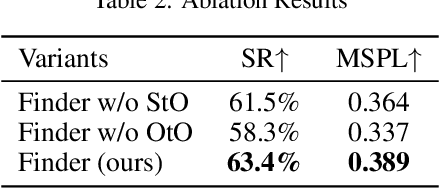
The Multi-Object Search (MOS) problem involves navigating to a sequence of locations to maximize the likelihood of finding target objects while minimizing travel costs. In this paper, we introduce a novel approach to the MOS problem, called Finder, which leverages vision language models (VLMs) to locate multiple objects across diverse environments. Specifically, our approach introduces multi-channel score maps to track and reason about multiple objects simultaneously during navigation, along with a score fusion technique that combines scene-level and object-level semantic correlations. Experiments in both simulated and real-world settings showed that Finder outperforms existing methods using deep reinforcement learning and VLMs. Ablation and scalability studies further validated our design choices and robustness with increasing numbers of target objects, respectively. Website: https://find-all-my-things.github.io/
NavFormer: A Transformer Architecture for Robot Target-Driven Navigation in Unknown and Dynamic Environments
Feb 09, 2024



In unknown cluttered and dynamic environments such as disaster scenes, mobile robots need to perform target-driven navigation in order to find people or objects of interest, while being solely guided by images of the targets. In this paper, we introduce NavFormer, a novel end-to-end transformer architecture developed for robot target-driven navigation in unknown and dynamic environments. NavFormer leverages the strengths of both 1) transformers for sequential data processing and 2) self-supervised learning (SSL) for visual representation to reason about spatial layouts and to perform collision-avoidance in dynamic settings. The architecture uniquely combines dual-visual encoders consisting of a static encoder for extracting invariant environment features for spatial reasoning, and a general encoder for dynamic obstacle avoidance. The primary robot navigation task is decomposed into two sub-tasks for training: single robot exploration and multi-robot collision avoidance. We perform cross-task training to enable the transfer of learned skills to the complex primary navigation task without the need for task-specific fine-tuning. Simulated experiments demonstrate that NavFormer can effectively navigate a mobile robot in diverse unknown environments, outperforming existing state-of-the-art methods in terms of success rate and success weighted by (normalized inverse) path length. Furthermore, a comprehensive ablation study is performed to evaluate the impact of the main design choices of the structure and training of NavFormer, further validating their effectiveness in the overall system.