 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFind Everything: A General Vision Language Model Approach to Multi-Object Search
Oct 01, 2024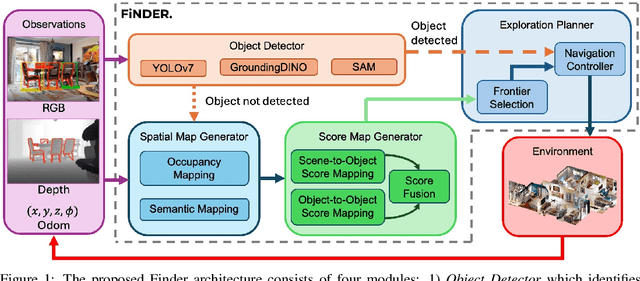
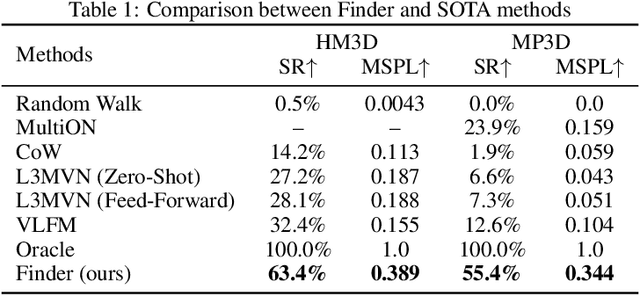
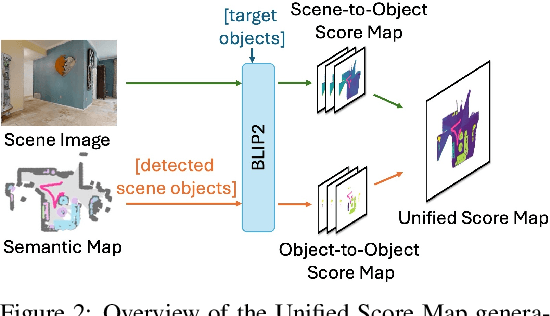
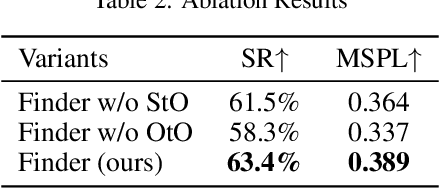
The Multi-Object Search (MOS) problem involves navigating to a sequence of locations to maximize the likelihood of finding target objects while minimizing travel costs. In this paper, we introduce a novel approach to the MOS problem, called Finder, which leverages vision language models (VLMs) to locate multiple objects across diverse environments. Specifically, our approach introduces multi-channel score maps to track and reason about multiple objects simultaneously during navigation, along with a score fusion technique that combines scene-level and object-level semantic correlations. Experiments in both simulated and real-world settings showed that Finder outperforms existing methods using deep reinforcement learning and VLMs. Ablation and scalability studies further validated our design choices and robustness with increasing numbers of target objects, respectively. Website: https://find-all-my-things.github.io/