 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCosmos World Foundation Model Platform for Physical AI
Jan 07, 2025



Physical AI needs to be trained digitally first. It needs a digital twin of itself, the policy model, and a digital twin of the world, the world model. In this paper, we present the Cosmos World Foundation Model Platform to help developers build customized world models for their Physical AI setups. We position a world foundation model as a general-purpose world model that can be fine-tuned into customized world models for downstream applications. Our platform covers a video curation pipeline, pre-trained world foundation models, examples of post-training of pre-trained world foundation models, and video tokenizers. To help Physical AI builders solve the most critical problems of our society, we make our platform open-source and our models open-weight with permissive licenses available via https://github.com/NVIDIA/Cosmos.
Robots Understanding Contextual Information in Human-Centered Environments using Weakly Supervised Mask Data Distillation
Dec 15, 2020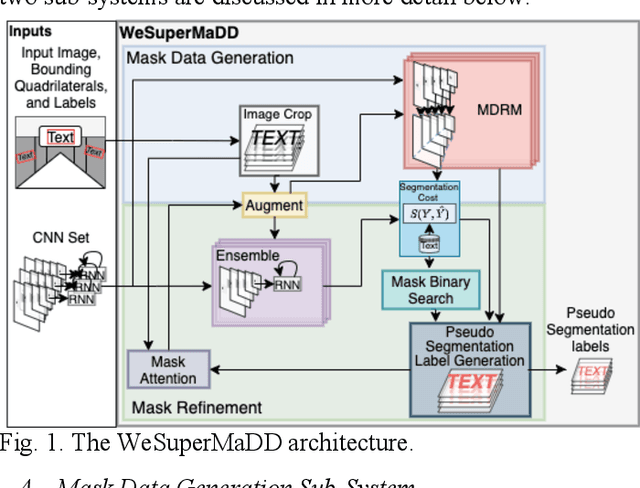


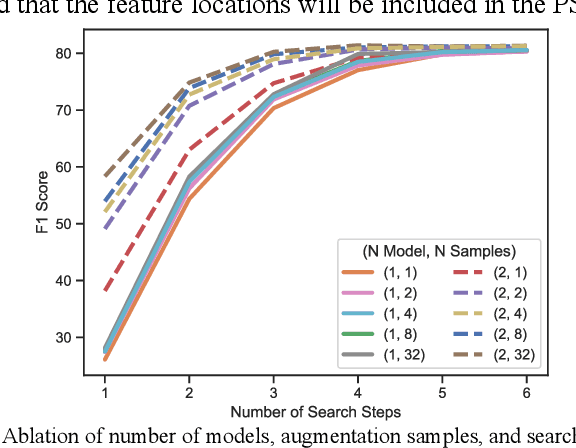
Contextual information in human environments, such as signs, symbols, and objects provide important information for robots to use for exploration and navigation. To identify and segment contextual information from complex images obtained in these environments, data-driven methods such as Convolutional Neural Networks (CNNs) are used. However, these methods require large amounts of human labeled data which are slow and time-consuming to obtain. Weakly supervised methods address this limitation by generating pseudo segmentation labels (PSLs). In this paper, we present the novel Weakly Supervised Mask Data Distillation (WeSuperMaDD) architecture for autonomously generating PSLs using CNNs not specifically trained for the task of context segmentation; i.e., CNNs trained for object classification, image captioning, etc. WeSuperMaDD uniquely generates PSLs using learned image features from sparse and limited diversity data; common in robot navigation tasks in human-centred environments (malls, grocery stores). Our proposed architecture uses a new mask refinement system which automatically searches for the PSL with the fewest foreground pixels that satisfies cost constraints. This removes the need for handcrafted heuristic rules. Extensive experiments successfully validated the performance of WeSuperMaDD in generating PSLs for datasets with text of various scales, fonts, and perspectives in multiple indoor/outdoor environments. A comparison with Naive, GrabCut, and Pyramid methods found a significant improvement in label and segmentation quality. Moreover, a context segmentation CNN trained using the WeSuperMaDD architecture achieved measurable improvements in accuracy compared to one trained with Naive PSLs. Our method also had comparable performance to existing state-of-the-art text detection and segmentation methods on real datasets without requiring segmentation labels for training.
End to End Learning for Self-Driving Cars
Apr 25, 2016


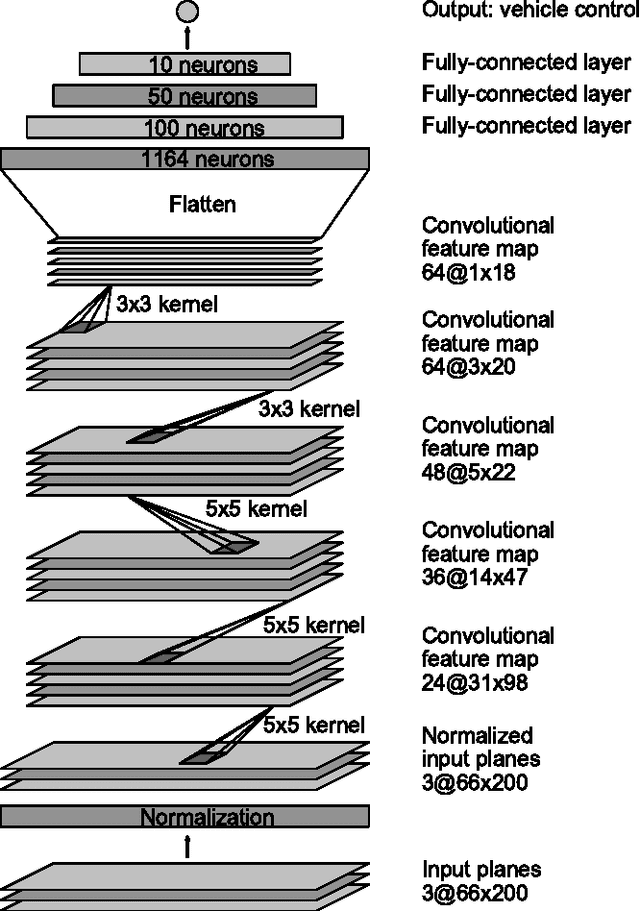
We trained a convolutional neural network (CNN) to map raw pixels from a single front-facing camera directly to steering commands. This end-to-end approach proved surprisingly powerful. With minimum training data from humans the system learns to drive in traffic on local roads with or without lane markings and on highways. It also operates in areas with unclear visual guidance such as in parking lots and on unpaved roads. The system automatically learns internal representations of the necessary processing steps such as detecting useful road features with only the human steering angle as the training signal. We never explicitly trained it to detect, for example, the outline of roads. Compared to explicit decomposition of the problem, such as lane marking detection, path planning, and control, our end-to-end system optimizes all processing steps simultaneously. We argue that this will eventually lead to better performance and smaller systems. Better performance will result because the internal components self-optimize to maximize overall system performance, instead of optimizing human-selected intermediate criteria, e.g., lane detection. Such criteria understandably are selected for ease of human interpretation which doesn't automatically guarantee maximum system performance. Smaller networks are possible because the system learns to solve the problem with the minimal number of processing steps. We used an NVIDIA DevBox and Torch 7 for training and an NVIDIA DRIVE(TM) PX self-driving car computer also running Torch 7 for determining where to drive. The system operates at 30 frames per second (FPS).