 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCosmos-Reason1: From Physical Common Sense To Embodied Reasoning
Mar 18, 2025Physical AI systems need to perceive, understand, and perform complex actions in the physical world. In this paper, we present the Cosmos-Reason1 models that can understand the physical world and generate appropriate embodied decisions (e.g., next step action) in natural language through long chain-of-thought reasoning processes. We begin by defining key capabilities for Physical AI reasoning, with a focus on physical common sense and embodied reasoning. To represent physical common sense, we use a hierarchical ontology that captures fundamental knowledge about space, time, and physics. For embodied reasoning, we rely on a two-dimensional ontology that generalizes across different physical embodiments. Building on these capabilities, we develop two multimodal large language models, Cosmos-Reason1-8B and Cosmos-Reason1-56B. We curate data and train our models in four stages: vision pre-training, general supervised fine-tuning (SFT), Physical AI SFT, and Physical AI reinforcement learning (RL) as the post-training. To evaluate our models, we build comprehensive benchmarks for physical common sense and embodied reasoning according to our ontologies. Evaluation results show that Physical AI SFT and reinforcement learning bring significant improvements. To facilitate the development of Physical AI, we will make our code and pre-trained models available under the NVIDIA Open Model License at https://github.com/nvidia-cosmos/cosmos-reason1.
Cosmos World Foundation Model Platform for Physical AI
Jan 07, 2025



Physical AI needs to be trained digitally first. It needs a digital twin of itself, the policy model, and a digital twin of the world, the world model. In this paper, we present the Cosmos World Foundation Model Platform to help developers build customized world models for their Physical AI setups. We position a world foundation model as a general-purpose world model that can be fine-tuned into customized world models for downstream applications. Our platform covers a video curation pipeline, pre-trained world foundation models, examples of post-training of pre-trained world foundation models, and video tokenizers. To help Physical AI builders solve the most critical problems of our society, we make our platform open-source and our models open-weight with permissive licenses available via https://github.com/NVIDIA/Cosmos.
We're Not Using Videos Effectively: An Updated Domain Adaptive Video Segmentation Baseline
Feb 06, 2024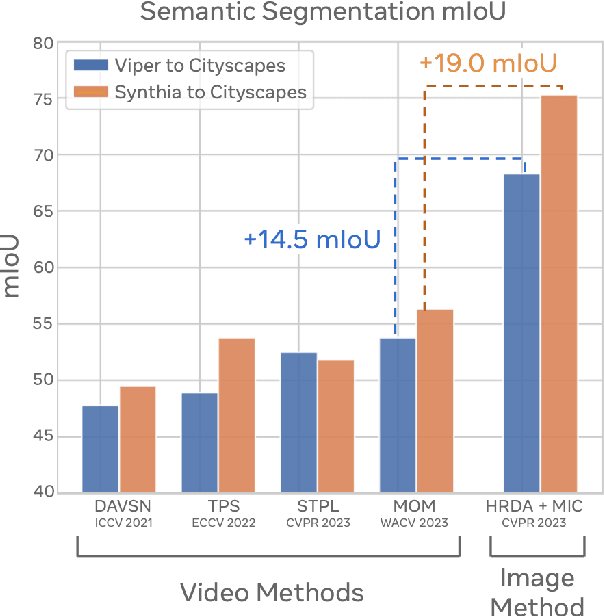

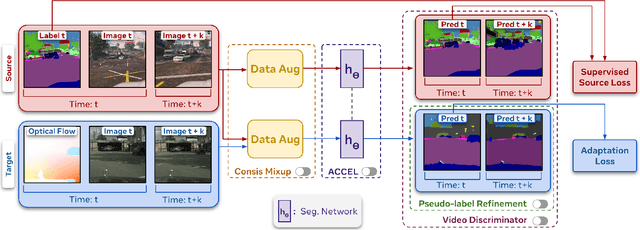
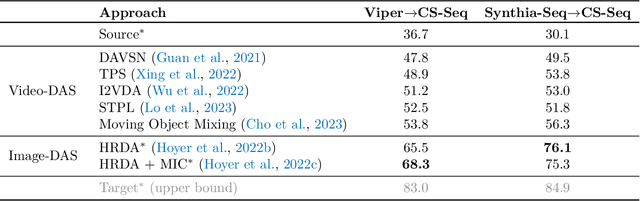
There has been abundant work in unsupervised domain adaptation for semantic segmentation (DAS) seeking to adapt a model trained on images from a labeled source domain to an unlabeled target domain. While the vast majority of prior work has studied this as a frame-level Image-DAS problem, a few Video-DAS works have sought to additionally leverage the temporal signal present in adjacent frames. However, Video-DAS works have historically studied a distinct set of benchmarks from Image-DAS, with minimal cross-benchmarking. In this work, we address this gap. Surprisingly, we find that (1) even after carefully controlling for data and model architecture, state-of-the-art Image-DAS methods (HRDA and HRDA+MIC) outperform Video-DAS methods on established Video-DAS benchmarks (+14.5 mIoU on Viper$\rightarrow$CityscapesSeq, +19.0 mIoU on Synthia$\rightarrow$CityscapesSeq), and (2) naive combinations of Image-DAS and Video-DAS techniques only lead to marginal improvements across datasets. To avoid siloed progress between Image-DAS and Video-DAS, we open-source our codebase with support for a comprehensive set of Video-DAS and Image-DAS methods on a common benchmark. Code available at https://github.com/SimarKareer/UnifiedVideoDA
AUGCAL: Improving Sim2Real Adaptation by Uncertainty Calibration on Augmented Synthetic Images
Dec 19, 2023

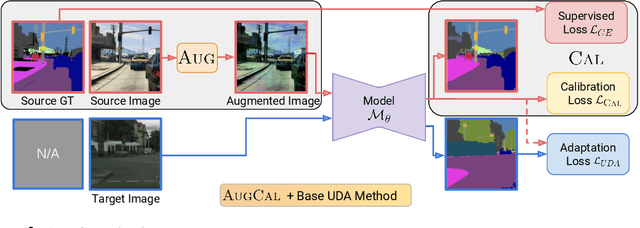

Synthetic data (SIM) drawn from simulators have emerged as a popular alternative for training models where acquiring annotated real-world images is difficult. However, transferring models trained on synthetic images to real-world applications can be challenging due to appearance disparities. A commonly employed solution to counter this SIM2REAL gap is unsupervised domain adaptation, where models are trained using labeled SIM data and unlabeled REAL data. Mispredictions made by such SIM2REAL adapted models are often associated with miscalibration - stemming from overconfident predictions on real data. In this paper, we introduce AUGCAL, a simple training-time patch for unsupervised adaptation that improves SIM2REAL adapted models by - (1) reducing overall miscalibration, (2) reducing overconfidence in incorrect predictions and (3) improving confidence score reliability by better guiding misclassification detection - all while retaining or improving SIM2REAL performance. Given a base SIM2REAL adaptation algorithm, at training time, AUGCAL involves replacing vanilla SIM images with strongly augmented views (AUG intervention) and additionally optimizing for a training time calibration loss on augmented SIM predictions (CAL intervention). We motivate AUGCAL using a brief analytical justification of how to reduce miscalibration on unlabeled REAL data. Through our experiments, we empirically show the efficacy of AUGCAL across multiple adaptation methods, backbones, tasks and shifts.
SkyScenes: A Synthetic Dataset for Aerial Scene Understanding
Dec 11, 2023



Real-world aerial scene understanding is limited by a lack of datasets that contain densely annotated images curated under a diverse set of conditions. Due to inherent challenges in obtaining such images in controlled real-world settings, we present SkyScenes, a synthetic dataset of densely annotated aerial images captured from Unmanned Aerial Vehicle (UAV) perspectives. We carefully curate SkyScenes images from CARLA to comprehensively capture diversity across layout (urban and rural maps), weather conditions, times of day, pitch angles and altitudes with corresponding semantic, instance and depth annotations. Through our experiments using SkyScenes, we show that (1) Models trained on SkyScenes generalize well to different real-world scenarios, (2) augmenting training on real images with SkyScenes data can improve real-world performance, (3) controlled variations in SkyScenes can offer insights into how models respond to changes in viewpoint conditions, and (4) incorporating additional sensor modalities (depth) can improve aerial scene understanding.
Battle of the Backbones: A Large-Scale Comparison of Pretrained Models across Computer Vision Tasks
Nov 20, 2023



Neural network based computer vision systems are typically built on a backbone, a pretrained or randomly initialized feature extractor. Several years ago, the default option was an ImageNet-trained convolutional neural network. However, the recent past has seen the emergence of countless backbones pretrained using various algorithms and datasets. While this abundance of choice has led to performance increases for a range of systems, it is difficult for practitioners to make informed decisions about which backbone to choose. Battle of the Backbones (BoB) makes this choice easier by benchmarking a diverse suite of pretrained models, including vision-language models, those trained via self-supervised learning, and the Stable Diffusion backbone, across a diverse set of computer vision tasks ranging from classification to object detection to OOD generalization and more. Furthermore, BoB sheds light on promising directions for the research community to advance computer vision by illuminating strengths and weakness of existing approaches through a comprehensive analysis conducted on more than 1500 training runs. While vision transformers (ViTs) and self-supervised learning (SSL) are increasingly popular, we find that convolutional neural networks pretrained in a supervised fashion on large training sets still perform best on most tasks among the models we consider. Moreover, in apples-to-apples comparisons on the same architectures and similarly sized pretraining datasets, we find that SSL backbones are highly competitive, indicating that future works should perform SSL pretraining with advanced architectures and larger pretraining datasets. We release the raw results of our experiments along with code that allows researchers to put their own backbones through the gauntlet here: https://github.com/hsouri/Battle-of-the-Backbones
LANCE: Stress-testing Visual Models by Generating Language-guided Counterfactual Images
May 30, 2023
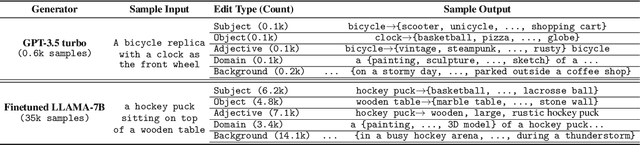
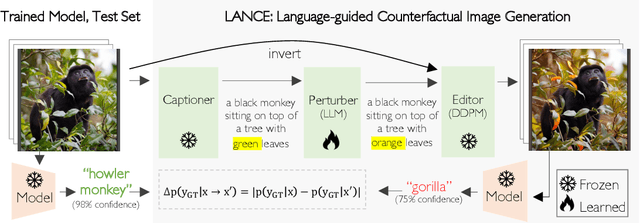

We propose an automated algorithm to stress-test a trained visual model by generating language-guided counterfactual test images (LANCE). Our method leverages recent progress in large language modeling and text-based image editing to augment an IID test set with a suite of diverse, realistic, and challenging test images without altering model weights. We benchmark the performance of a diverse set of pretrained models on our generated data and observe significant and consistent performance drops. We further analyze model sensitivity across different types of edits, and demonstrate its applicability at surfacing previously unknown class-level model biases in ImageNet.
Benchmarking Low-Shot Robustness to Natural Distribution Shifts
Apr 21, 2023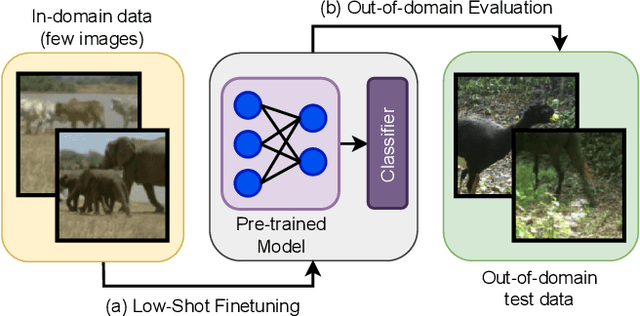
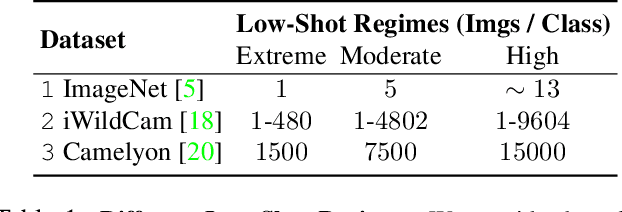
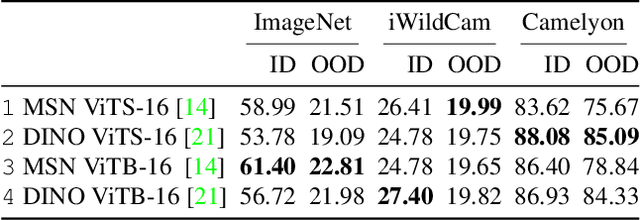
Robustness to natural distribution shifts has seen remarkable progress thanks to recent pre-training strategies combined with better fine-tuning methods. However, such fine-tuning assumes access to large amounts of labelled data, and the extent to which the observations hold when the amount of training data is not as high remains unknown. We address this gap by performing the first in-depth study of robustness to various natural distribution shifts in different low-shot regimes: spanning datasets, architectures, pre-trained initializations, and state-of-the-art robustness interventions. Most importantly, we find that there is no single model of choice that is often more robust than others, and existing interventions can fail to improve robustness on some datasets even if they do so in the full-shot regime. We hope that our work will motivate the community to focus on this problem of practical importance.
PASTA: Proportional Amplitude Spectrum Training Augmentation for Syn-to-Real Domain Generalization
Dec 02, 2022



Synthetic data offers the promise of cheap and bountiful training data for settings where lots of labeled real-world data for tasks is unavailable. However, models trained on synthetic data significantly underperform on real-world data. In this paper, we propose Proportional Amplitude Spectrum Training Augmentation (PASTA), a simple and effective augmentation strategy to improve out-of-the-box synthetic-to-real (syn-to-real) generalization performance. PASTA involves perturbing the amplitude spectrums of the synthetic images in the Fourier domain to generate augmented views. We design PASTA to perturb the amplitude spectrums in a structured manner such that high-frequency components are perturbed relatively more than the low-frequency ones. For the tasks of semantic segmentation (GTAV to Real), object detection (Sim10K to Real), and object recognition (VisDA-C Syn to Real), across a total of 5 syn-to-real shifts, we find that PASTA outperforms more complex state-of-the-art generalization methods while being complementary to the same.
RobustNav: Towards Benchmarking Robustness in Embodied Navigation
Jun 08, 2021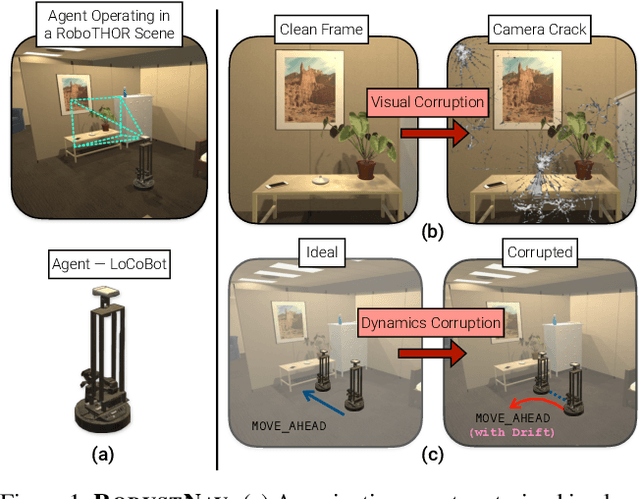
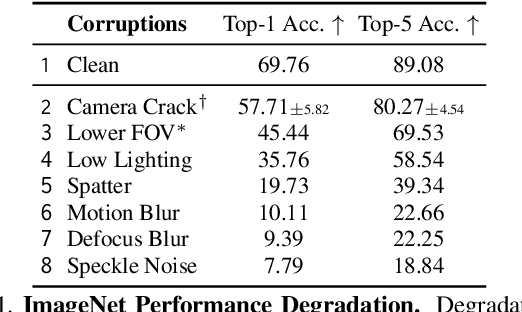

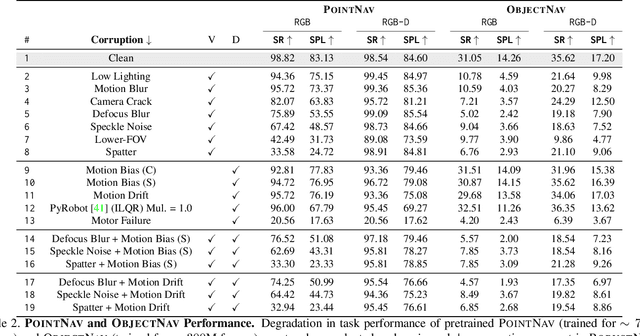
As an attempt towards assessing the robustness of embodied navigation agents, we propose RobustNav, a framework to quantify the performance of embodied navigation agents when exposed to a wide variety of visual - affecting RGB inputs - and dynamics - affecting transition dynamics - corruptions. Most recent efforts in visual navigation have typically focused on generalizing to novel target environments with similar appearance and dynamics characteristics. With RobustNav, we find that some standard embodied navigation agents significantly underperform (or fail) in the presence of visual or dynamics corruptions. We systematically analyze the kind of idiosyncrasies that emerge in the behavior of such agents when operating under corruptions. Finally, for visual corruptions in RobustNav, we show that while standard techniques to improve robustness such as data-augmentation and self-supervised adaptation offer some zero-shot resistance and improvements in navigation performance, there is still a long way to go in terms of recovering lost performance relative to clean "non-corrupt" settings, warranting more research in this direction. Our code is available at https://github.com/allenai/robustnav