 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPEAR-MM: Selective Parameter Evaluation and Restoration via Model Merging for Efficient Financial LLM Adaptation
Nov 11, 2025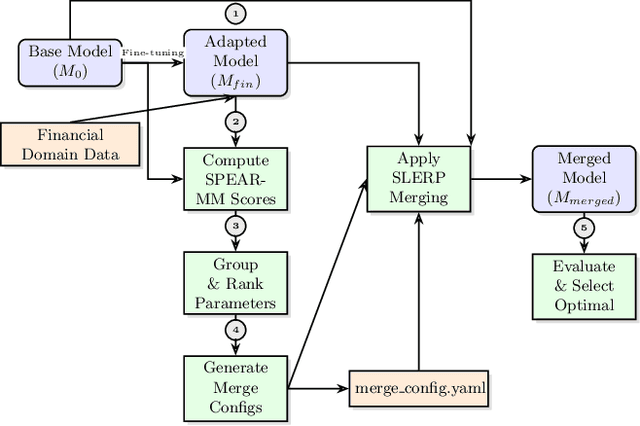


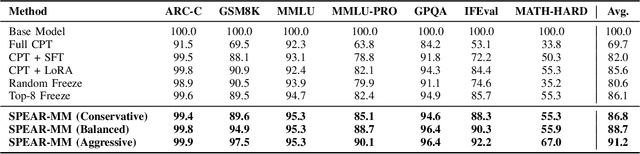
Large language models (LLMs) adapted to financial domains often suffer from catastrophic forgetting of general reasoning capabilities essential for customer interactions and complex financial analysis. We introduce Selective Parameter Evaluation and Restoration via Model Merging (SPEAR-MM), a practical framework that preserves critical capabilities while enabling domain adaptation. Our method approximates layer-wise impact on external benchmarks through post-hoc analysis, then selectively freezes or restores transformer layers via spherical interpolation merging. Applied to LLaMA-3.1-8B for financial tasks, SPEAR-MM achieves 91.2% retention of general capabilities versus 69.7% for standard continual pretraining, while maintaining 94% of domain adaptation gains. The approach provides interpretable trade-off control and reduces computational costs by 90% crucial for resource-constrained financial institutions.
Battle of the Backbones: A Large-Scale Comparison of Pretrained Models across Computer Vision Tasks
Nov 20, 2023



Neural network based computer vision systems are typically built on a backbone, a pretrained or randomly initialized feature extractor. Several years ago, the default option was an ImageNet-trained convolutional neural network. However, the recent past has seen the emergence of countless backbones pretrained using various algorithms and datasets. While this abundance of choice has led to performance increases for a range of systems, it is difficult for practitioners to make informed decisions about which backbone to choose. Battle of the Backbones (BoB) makes this choice easier by benchmarking a diverse suite of pretrained models, including vision-language models, those trained via self-supervised learning, and the Stable Diffusion backbone, across a diverse set of computer vision tasks ranging from classification to object detection to OOD generalization and more. Furthermore, BoB sheds light on promising directions for the research community to advance computer vision by illuminating strengths and weakness of existing approaches through a comprehensive analysis conducted on more than 1500 training runs. While vision transformers (ViTs) and self-supervised learning (SSL) are increasingly popular, we find that convolutional neural networks pretrained in a supervised fashion on large training sets still perform best on most tasks among the models we consider. Moreover, in apples-to-apples comparisons on the same architectures and similarly sized pretraining datasets, we find that SSL backbones are highly competitive, indicating that future works should perform SSL pretraining with advanced architectures and larger pretraining datasets. We release the raw results of our experiments along with code that allows researchers to put their own backbones through the gauntlet here: https://github.com/hsouri/Battle-of-the-Backbones
K-SAM: Sharpness-Aware Minimization at the Speed of SGD
Oct 23, 2022Sharpness-Aware Minimization (SAM) has recently emerged as a robust technique for improving the accuracy of deep neural networks. However, SAM incurs a high computational cost in practice, requiring up to twice as much computation as vanilla SGD. The computational challenge posed by SAM arises because each iteration requires both ascent and descent steps and thus double the gradient computations. To address this challenge, we propose to compute gradients in both stages of SAM on only the top-k samples with highest loss. K-SAM is simple and extremely easy-to-implement while providing significant generalization boosts over vanilla SGD at little to no additional cost.
GradInit: Learning to Initialize Neural Networks for Stable and Efficient Training
Feb 16, 2021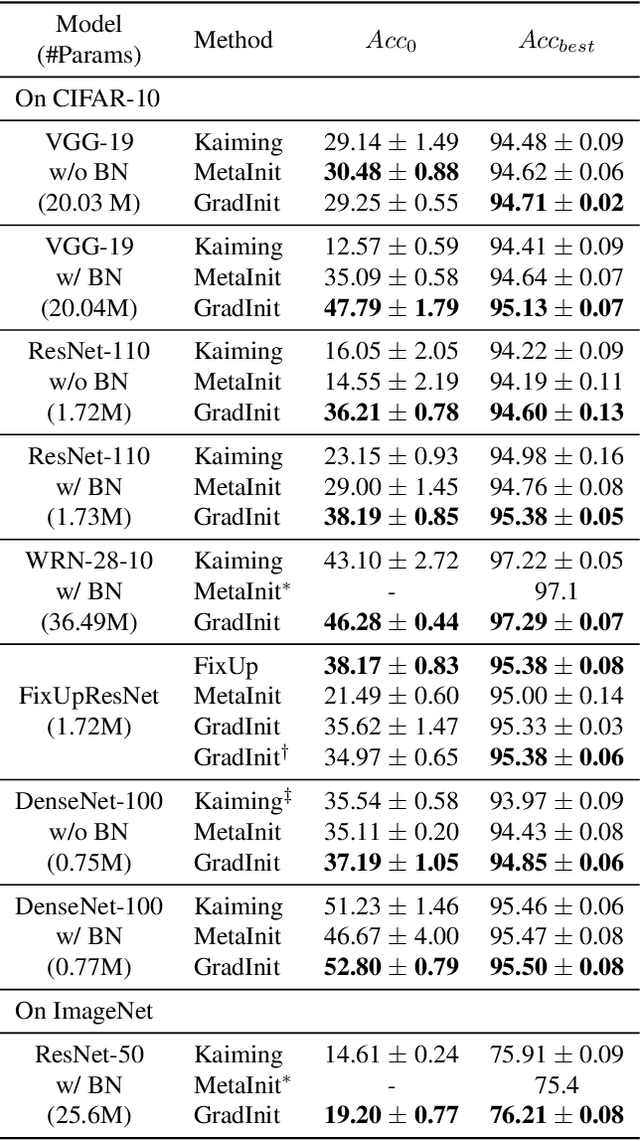
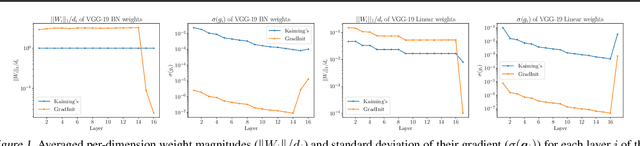
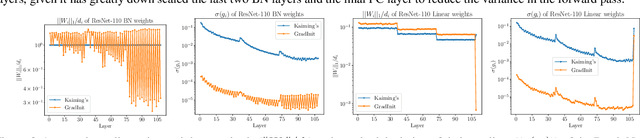
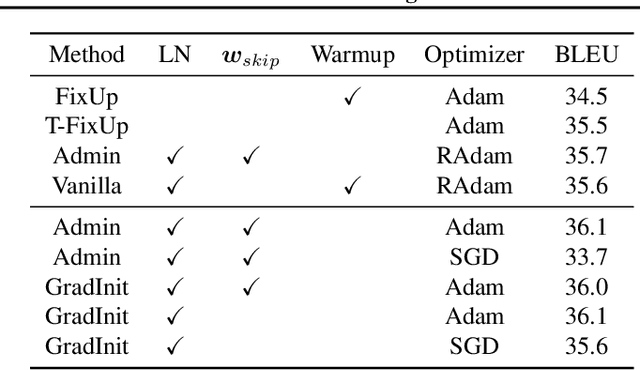
Changes in neural architectures have fostered significant breakthroughs in language modeling and computer vision. Unfortunately, novel architectures often require re-thinking the choice of hyperparameters (e.g., learning rate, warmup schedule, and momentum coefficients) to maintain stability of the optimizer. This optimizer instability is often the result of poor parameter initialization, and can be avoided by architecture-specific initialization schemes. In this paper, we present GradInit, an automated and architecture agnostic method for initializing neural networks. GradInit is based on a simple heuristic; the variance of each network layer is adjusted so that a single step of SGD or Adam results in the smallest possible loss value. This adjustment is done by introducing a scalar multiplier variable in front of each parameter block, and then optimizing these variables using a simple numerical scheme. GradInit accelerates the convergence and test performance of many convolutional architectures, both with or without skip connections, and even without normalization layers. It also enables training the original Post-LN Transformer for machine translation without learning rate warmup under a wide range of learning rates and momentum coefficients. Code is available at https://github.com/zhuchen03/gradinit.
Data Augmentation for Meta-Learning
Oct 14, 2020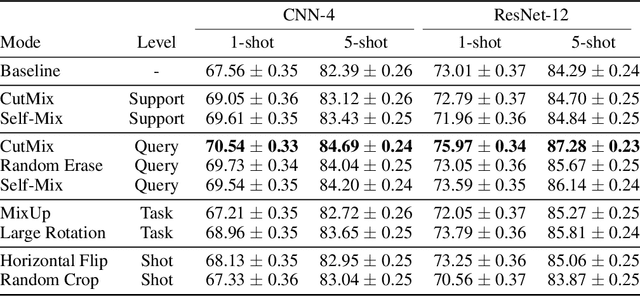

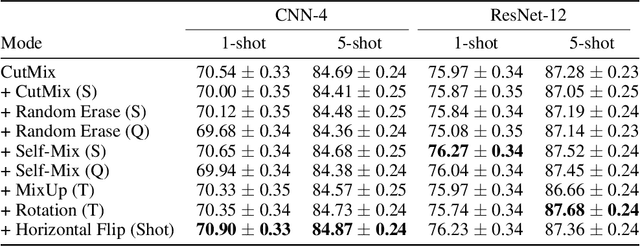

Conventional image classifiers are trained by randomly sampling mini-batches of images. To achieve state-of-the-art performance, sophisticated data augmentation schemes are used to expand the amount of training data available for sampling. In contrast, meta-learning algorithms sample not only images, but classes as well. We investigate how data augmentation can be used not only to expand the number of images available per class, but also to generate entirely new classes. We systematically dissect the meta-learning pipeline and investigate the distinct ways in which data augmentation can be integrated at both the image and class levels. Our proposed meta-specific data augmentation significantly improves the performance of meta-learners on few-shot classification benchmarks.
WrapNet: Neural Net Inference with Ultra-Low-Resolution Arithmetic
Jul 26, 2020
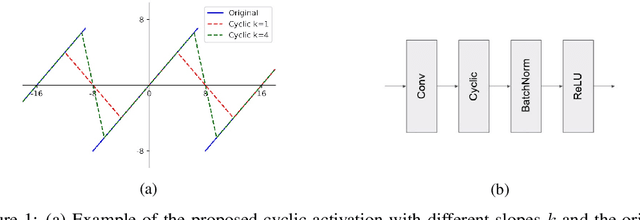

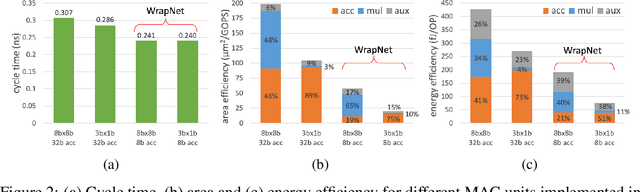
Low-resolution neural networks represent both weights and activations with few bits, drastically reducing the multiplication complexity. Nonetheless, these products are accumulated using high-resolution (typically 32-bit) additions, an operation that dominates the arithmetic complexity of inference when using extreme quantization (e.g., binary weights). To further optimize inference, we propose a method that adapts neural networks to use low-resolution (8-bit) additions in the accumulators, achieving classification accuracy comparable to their 32-bit counterparts. We achieve resilience to low-resolution accumulation by inserting a cyclic activation layer, as well as an overflow penalty regularizer. We demonstrate the efficacy of our approach on both software and hardware platforms.
Unraveling Meta-Learning: Understanding Feature Representations for Few-Shot Tasks
Mar 21, 2020



Meta-learning algorithms produce feature extractors which achieve state-of-the-art performance on few-shot classification. While the literature is rich with meta-learning methods, little is known about why the resulting feature extractors perform so well. We develop a better understanding of the underlying mechanics of meta-learning and the difference between models trained using meta-learning and models which are trained classically. In doing so, we develop several hypotheses for why meta-learned models perform better. In addition to visualizations, we design several regularizers inspired by our hypotheses which improve performance on few-shot classification.
Certified Defenses for Adversarial Patches
Mar 14, 2020
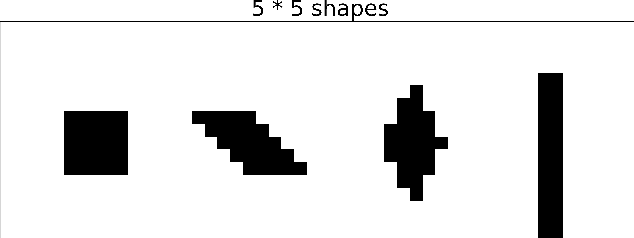

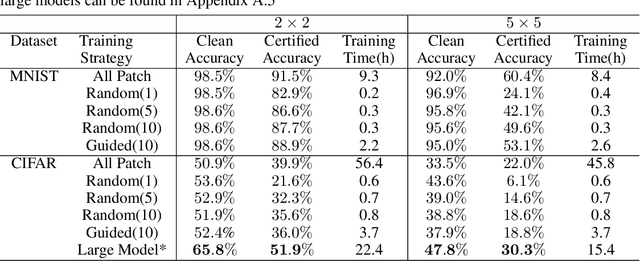
Adversarial patch attacks are among one of the most practical threat models against real-world computer vision systems. This paper studies certified and empirical defenses against patch attacks. We begin with a set of experiments showing that most existing defenses, which work by pre-processing input images to mitigate adversarial patches, are easily broken by simple white-box adversaries. Motivated by this finding, we propose the first certified defense against patch attacks, and propose faster methods for its training. Furthermore, we experiment with different patch shapes for testing, obtaining surprisingly good robustness transfer across shapes, and present preliminary results on certified defense against sparse attacks. Our complete implementation can be found on: https://github.com/Ping-C/certifiedpatchdefense.
Improving the Tightness of Convex Relaxation Bounds for Training Certifiably Robust Classifiers
Feb 22, 2020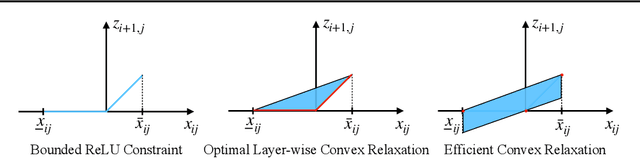

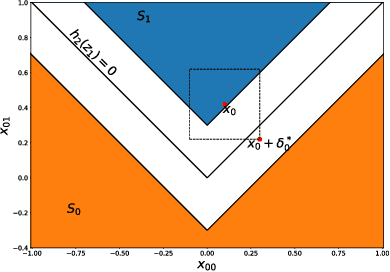

Convex relaxations are effective for training and certifying neural networks against norm-bounded adversarial attacks, but they leave a large gap between certifiable and empirical robustness. In principle, convex relaxation can provide tight bounds if the solution to the relaxed problem is feasible for the original non-convex problem. We propose two regularizers that can be used to train neural networks that yield tighter convex relaxation bounds for robustness. In all of our experiments, the proposed regularizers result in higher certified accuracy than non-regularized baselines.
WITCHcraft: Efficient PGD attacks with random step size
Nov 18, 2019



State-of-the-art adversarial attacks on neural networks use expensive iterative methods and numerous random restarts from different initial points. Iterative FGSM-based methods without restarts trade off performance for computational efficiency because they do not adequately explore the image space and are highly sensitive to the choice of step size. We propose a variant of Projected Gradient Descent (PGD) that uses a random step size to improve performance without resorting to expensive random restarts. Our method, Wide Iterative Stochastic crafting (WITCHcraft), achieves results superior to the classical PGD attack on the CIFAR-10 and MNIST data sets but without additional computational cost. This simple modification of PGD makes crafting attacks more economical, which is important in situations like adversarial training where attacks need to be crafted in real time.